
在`Guava`的包中提供了布隆过滤器的实现,下面就让我们通过`Guava`提供的布隆过滤器来体会一下布隆过滤器的使用:
1. 还是使用之前的`redis-demo`项目,打开`pom.xml`文件,引入下面的`pom`依赖:
~~~java
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>
~~~
在如下图所示位置引入:
2. 在`src/main/java`目录下的`com.lonely.wolf.redis`包内新建一个测试类`GuavaBloomFilter.java`进行测试:
~~~java
package com.lonely.wolf.redis;
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.text.NumberFormat;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
public class GuavaBloomFilter {
private static final int expectedInsertions = 1000000;
public static void main(String[] args) {
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),expectedInsertions);
List<String> list = new ArrayList<>(expectedInsertions);
for (int i = 0; i < expectedInsertions; i++) {
String uuid = UUID.randomUUID().toString();
bloomFilter.put(uuid);
list.add(uuid);
}
int mightContainNum1 = 0;
NumberFormat percentFormat =NumberFormat.getPercentInstance();
percentFormat.setMaximumFractionDigits(2); //最大小数位数
for (int i=0;i < 500;i++){
String key = list.get(i);
if (bloomFilter.mightContain(key)){
mightContainNum1++;
}
}
System.out.println("【key真实存在的情况】布隆过滤器认为存在的key值数:" + mightContainNum1);
System.out.println("-----------------------分割线---------------------------------");
int mightContainNum2 = 0;
for (int i=0;i < expectedInsertions;i++){
String key = UUID.randomUUID().toString();
if (bloomFilter.mightContain(key)){
mightContainNum2++;
}
}
System.out.println("【key不存在的情况】布隆过滤器认为存在的key值数:" + mightContainNum2);
System.out.println("【key不存在的情况】布隆过滤器的误判率为:" + percentFormat.format((float)mightContainNum2 / expectedInsertions));
}
}
~~~
3. 同时,需要修改`pom.xml`文件中的`mainClass`属性,把这个类名修改正确:
~~~xml
<mainClass>com.lonely.wolf.redis.GuavaBloomFilter</mainClass>
~~~
4. 执行如下命令:
~~~bash
# 进入主目录
cd /home/project/redis-demo
# 将项目打包成一个 jar 包
mvn clean package -Dmaven.test.skip=true
# 运行
java -jar target/redis-demo-1.0.0-SNAPSHOT.jar
~~~
运行之后的结果为:
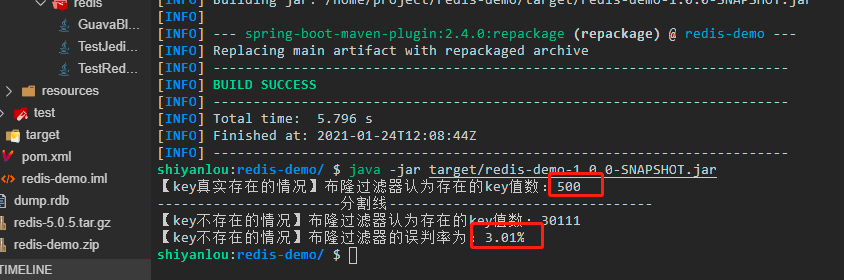
第一部分输出的`mightContainNum1`一定是和`for`循环内的值相等,也就是百分百匹配。即满足了原则`1`:**如果元素实际存在,那么布隆过滤器一定会判断存在**。
第二部分的输出的误判率即`fpp`总是在`3%`左右,而且随着`for`循环的次数越大,越接近`3%`。即满足了原则`2`:**如果元素不存在,那么布隆过滤器可能会判断存在**。
这个`3%`的`fpp`是`Guava`中默认的`fpp`,且经过哈希计算次数默认为`5`次,这个`3%`的误判率和`5`次哈希运算需要多大空间位数组呢?这个大小可以[点击这里](https://hur.st/bloomfilter/?n=1000000&p=0.03&m=&k=)进行模拟计算,下图就是一个计算结果:
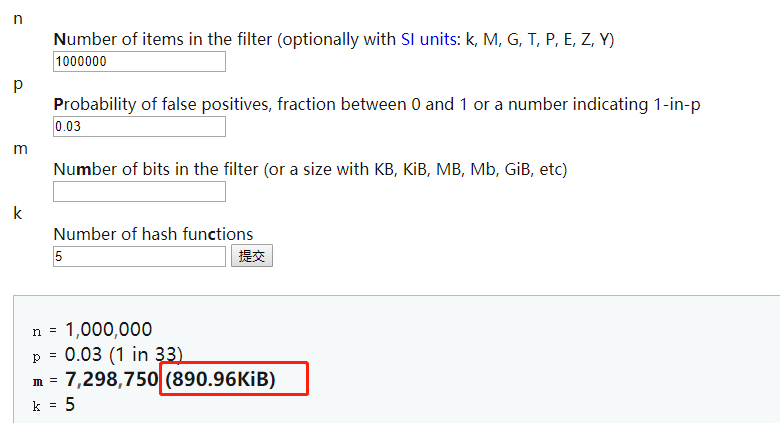
得到的结果是`890kb`,`100W`的`key`才占用了`0.89M`,而如果是`10`亿呢,计算的结果是`870M`,这个内存空间是完全可以接受的。
- Redis 为什么这么快
- 什么是 Redis
- Redis 的安装
- Redis 到底有多快
- Redis 是单线程还是多线程
- Redis 为什么选择使用单线程来执行请求
- 什么是 IO 多路复用机制
- Redis 中 I/O 多路复用的应用
- 一个简单的字符串,为什么 Redis 要设计的如此特别
- Redis 的 9 种数据类型
- 二进制安全字符串
- sds 空间分配策略
- sds 和 C 语言字符串区别
- sds 是如何被存储的
- type 属性
- encoding 属性
- 通过牺牲速度来节省内存,Redis 是觉得自己太快了吗
- 什么是压缩列表
- ziplist 的存储结构
- entry 存储结构
- ziplist 数据示例
- ziplist 连锁更新问题
- 为了加快速度,Redis 都做了哪些“变态”设计
- 列表对象
- linkedlist
- linkedlist 和 ziplist 的选择
- quicklist
- 列表对象常用操作命令
- Redis 中哈希分布不均匀该怎么办
- 哈希对象
- hashtable
- ziplist
- ziplist 和 hashtable 的编码转换
- 哈希对象常用命令
- 同一份数据,Redis 为什么要存”两次”
- 五种基本类型之集合对象
- intset 编码
- 集合对象常用命令
- 五种基本类型之有序集合对象
- skiplist 编码
- ziplist 编码
- ziplist 和 skiplist 编码转换
- 有序集合对象常用命令
- 要想用活 Redis,Lua 脚本是绕不过去的坎
- 发布与订阅
- 基于频道的实现
- 基于模式的实现
- Lua 脚本
- Lua 脚本的调用
- Lua 脚本中执行 Redis 命令
- Lua 脚本摘要
- Lua 脚本文件
- 脚本异常
- 作为一款内存数据库,为什么断电后 Redis 数据不会丢失
- Redis 持久化机制
- RDB 持久化机制
- AOF 持久化机制
- 内存耗尽后 Redis 会发生什么
- 内存回收
- 过期策略
- 8 种淘汰策略
- LRU 算法
- LFU 算法
- 不能回滚的 Redis 事务还能用吗
- Redis 有事务吗
- Redis 事务实现原理
- Redis 事务 ACID 特性
- watch 命令
- watch 命令的作用
- watch 原理分析
- Redis 为什么不直接用 master-slave 集群
- Redis 集群方案
- 主从复制
- 配置一主两从 master-slave 集群
- 主从复制原理分析
- 主从服务的不足之处
- Sentinel(哨兵)机制为什么从神坛滑落
- 哨兵 Sentinel 机制
- Sentinel 原理分析
- 配置 Sentinel 集群
- Sentinel 机制实战
- Sentinel 机制的不足之处
- Redis Cluster 集群凭什么成为了最终的胜利者
- Redis 分布式集群方案
- 客户端实现分片
- 中间代理服务实现分片
- Redis Cluster 方案
- 手动配置一个 Redis Cluster 集群
- Redis Cluster 集群常用命令
- 客户端如何使用 Redis Cluster 集群
- Redis Cluster 的不足
- 如何从 10 亿数据中快速判断是否存在某一个元素
- 缓存雪崩
- 缓存击穿
- 缓存穿透
- 布隆过滤器(Bloom Filter)
- 布隆过滤器的 2 大特点
- 布隆过滤器的实现(Guava)
- 布隆过滤器的如何删除