
`Redis`是基于`C`语言进行开发的,而`C`语言中的字符串是二进制不安全的,所以`Redis`就没有直接使用`C`语言的字符串,而是自己编写了一个新的数据结构来表示字符串,这种数据结构称之为简单动态字符串(Simple dynamic string),简称`sds`。
在`C`语言中,字符串采用的是一个`char`数组(柔性数组)来存储字符串,而且字符串必须要以一个空字符串`\0`来结尾。字符串并不记录长度,所以如果想要获取一个字符串的长度就必须遍历整个字符串,直到遇到第一个`\0`为止(`\0`不会计入字符串长度),故而获取字符串长度的时间复杂度为`O(n)`。
正因为`C`语言中是以遇到的第一个空字符`\0`来识别是否到了字符串末尾,因此其只能保存文本数据,不能保存图片、音频、视频和压缩文件等二进制数据,否则可能出现字符串不完整的问题,所以其是二进制不安全的。
`Redis`中为了实现二进制安全的字符串,对原有`C`语言中的字符串实现做了改进。如下所示就是一个旧版本的`sds`字符串的结构定义:
~~~c
struct sdshdr{
int len;//记录buf数组已使用的长度,即SDS的长度(不包含末尾的'\0')
int free;//记录buf数组中未使用的长度
char buf[];//字节数组,用来保存字符串
}
~~~
经过改进之后,如果想要获取`sds`的长度不用去遍历`buf`数组了,直接读取`len`属性就可以得到长度,时间复杂度一下就变成了`O(1)`,而且因为判断字符串长度不再依赖空字符`\0`,所以其能存储图片、音频、视频和压缩文件等二进制数据,不用担心读取到的字符串不完整。
需要注意的是,`sds`依然遵循了`C`语言字符串以`\0`结尾的惯例,这么做是为了方便复用`C`语言字符串原生的一些 API,换言之就是在`C`语言中会以碰到的第一个`\0`字符作为当前字符串对象的结尾,所以如果一些二进制数据就可能会出现读取字符串不完整的现象,而`sds`会以长度来判断是否到字符串末尾。
在`Redis 3.2`之后的版本,`Redis`对`sds`又做了优化,按照存储空间的大小拆分成为了`sdshdr5`、`sdshdr8`、`sdshdr16`、`sdshdr32`、`sdshdr64`,分别用来存储大小为:`32`字节(`2`的`5`次方),`256`字节(`2`的`8`次方),`64KB`(`2`的`16`次方),`4GB`大小(`2`的`32`次方)以及`2`的`64`次方大小的字符串(因为目前版本`key`和`value`都限制了最大`512MB`,所以`sdshdr64`暂时并未使用到)。`sdshdr5`只被应用在了`Redis`的`key`中,`value`中不会被使用到,因为`sdshdr5`和其它类型也不一样,其并没有存储未使用空间,所以比较适用于使用大小固定的场景(比如`key`值):
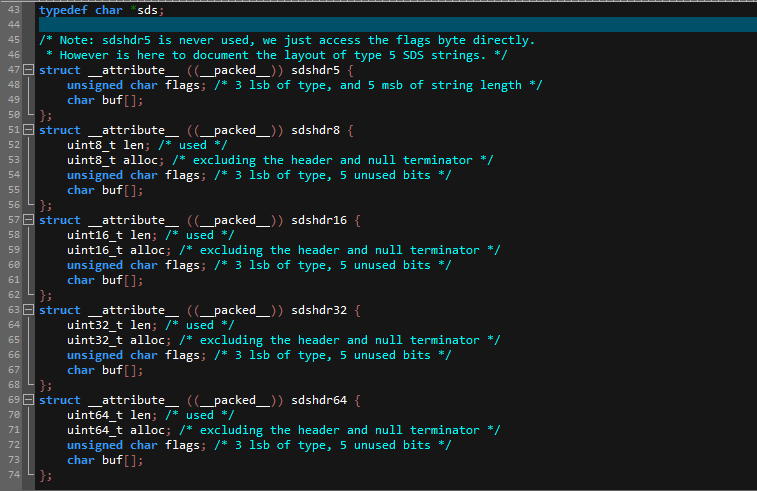
任意选择其中一种数据类型,其字段代表含义如下:
~~~c
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; //已使用空间大小
uint8_t alloc; //总共申请的空间大小(包括未使用的)
unsigned char flags; //用来表示当前sds类型是sdshdr8还是sdshdr16等
char buf[]; //真实存储字符串的字节数组
};
~~~
可以看到相比较于`Redis 3.2`版本之前的`sds`,主要是修改了`free`属性然后新增了一个`flags`标记来区分当前的`sds`类型。
- Redis 为什么这么快
- 什么是 Redis
- Redis 的安装
- Redis 到底有多快
- Redis 是单线程还是多线程
- Redis 为什么选择使用单线程来执行请求
- 什么是 IO 多路复用机制
- Redis 中 I/O 多路复用的应用
- 一个简单的字符串,为什么 Redis 要设计的如此特别
- Redis 的 9 种数据类型
- 二进制安全字符串
- sds 空间分配策略
- sds 和 C 语言字符串区别
- sds 是如何被存储的
- type 属性
- encoding 属性
- 通过牺牲速度来节省内存,Redis 是觉得自己太快了吗
- 什么是压缩列表
- ziplist 的存储结构
- entry 存储结构
- ziplist 数据示例
- ziplist 连锁更新问题
- 为了加快速度,Redis 都做了哪些“变态”设计
- 列表对象
- linkedlist
- linkedlist 和 ziplist 的选择
- quicklist
- 列表对象常用操作命令
- Redis 中哈希分布不均匀该怎么办
- 哈希对象
- hashtable
- ziplist
- ziplist 和 hashtable 的编码转换
- 哈希对象常用命令
- 同一份数据,Redis 为什么要存”两次”
- 五种基本类型之集合对象
- intset 编码
- 集合对象常用命令
- 五种基本类型之有序集合对象
- skiplist 编码
- ziplist 编码
- ziplist 和 skiplist 编码转换
- 有序集合对象常用命令
- 要想用活 Redis,Lua 脚本是绕不过去的坎
- 发布与订阅
- 基于频道的实现
- 基于模式的实现
- Lua 脚本
- Lua 脚本的调用
- Lua 脚本中执行 Redis 命令
- Lua 脚本摘要
- Lua 脚本文件
- 脚本异常
- 作为一款内存数据库,为什么断电后 Redis 数据不会丢失
- Redis 持久化机制
- RDB 持久化机制
- AOF 持久化机制
- 内存耗尽后 Redis 会发生什么
- 内存回收
- 过期策略
- 8 种淘汰策略
- LRU 算法
- LFU 算法
- 不能回滚的 Redis 事务还能用吗
- Redis 有事务吗
- Redis 事务实现原理
- Redis 事务 ACID 特性
- watch 命令
- watch 命令的作用
- watch 原理分析
- Redis 为什么不直接用 master-slave 集群
- Redis 集群方案
- 主从复制
- 配置一主两从 master-slave 集群
- 主从复制原理分析
- 主从服务的不足之处
- Sentinel(哨兵)机制为什么从神坛滑落
- 哨兵 Sentinel 机制
- Sentinel 原理分析
- 配置 Sentinel 集群
- Sentinel 机制实战
- Sentinel 机制的不足之处
- Redis Cluster 集群凭什么成为了最终的胜利者
- Redis 分布式集群方案
- 客户端实现分片
- 中间代理服务实现分片
- Redis Cluster 方案
- 手动配置一个 Redis Cluster 集群
- Redis Cluster 集群常用命令
- 客户端如何使用 Redis Cluster 集群
- Redis Cluster 的不足
- 如何从 10 亿数据中快速判断是否存在某一个元素
- 缓存雪崩
- 缓存击穿
- 缓存穿透
- 布隆过滤器(Bloom Filter)
- 布隆过滤器的 2 大特点
- 布隆过滤器的实现(Guava)
- 布隆过滤器的如何删除