
`master-slave`集群的关键在于数据的同步,而在数据同步之前必须先建立连接,建立连接之后再进行数据同步。
#### 建立连接
建立连接主要分为以下几步:
1. 执行`replicaof`命令时,从服务器会在本地将主服务器的一些信息(如:`ip`和端口等信息)保存在`redisServer`内。
2. 创建和主服务器的连接,创建连接之后,从服务器就相当于主服务器的一个客户端。
3. 从服务器向主服务发送`ping`命令,确认连接是否可用,如果`Redis`服务器需要授权,这一步还会进行授权认证。
4. 如果从服务器收到主服务器的`pong`回复之后,表示当前连接是可用的。此时从服务器会将自己服务器的端口号发送给主服务器,主服务器收到之后将其记录在`redisClient`内。
5. 如果从服务器没收到主服务器返回`pong`,则会重新尝试建立连接。
注意:建立完连接之后,主从服务器会定时(间隔`1s`)向对方发送`replconf of`命令来检测对方是否正常。上图中在主服务器查看从服务器信息中有一个`lag`属性记录的就是上一次发送心跳包时间。
#### 同步
`master`和`slave`服务之间连接建立之后,就会开始进行数据同步,而**首次同步**一般用于首次建立主从连接的时候,这时候因为是初次建立`master-slave`关系,所以需要进行数据的全量同步。
首次数据全量同步主要分为以下步骤:
1. 从服务器向主服务器发送同步数据命令。
2. 主服务器接收到同步数据命令之后,则会执行`bgsave`命令,在后台生成一个`RDB`文件,并将其发送给从服务器,此时如果有新的命令过来,主服务器会将其记录在缓冲区内。
3. 从服务器收到主服务器发送过来的`RDB`文件之后,会首先清除自己的数据,然后载入`RDB`文件来生成数据。
4. 当从服务器执行完`RDB`文件之后,主服务器会将缓冲区的命令发送给从服务器,从服务器再依次执行。
#### 命令传播
执行完首次全量同步之后,这时候主服务器会将自己接收到的改变了数据库状态的命令发送给从服务器,从而使得主从服务器数据始终保持一致。
既然是命令传播,那么就不可避免的会造成数据延迟,`Redis`当中提供了一个参数来进行优化。
~~~
repl-disable-tcp-nodelay no #默认是no
~~~
当参数设置为`yes`时,`Redis`会将数据包进行合并发送,也就是降低了发送频率(发送频率与`Linux`内核配置有关);当参数设置为`no`时,则主服务器每执行一个能改变数据库状态的命令就会立刻实时同步给从服务器。
#### 部分重同步
上面就是在服务器正常情况下的同步措施,**数据全量同步 + 命令传播,可以使得正常情况下主从服务器数据保持一致**。然而如果说从服务器因为停电等其它因素导致其和主服务器之间的连接中途断开,那么当连接再次恢复正常之后,如果还是重新全量同步则效率会非常低,也显得没有必要,所以`Redis`还需要支持部分重同步。
**实现部分重同步最关键的地方就是需要记录原先同步的偏移量,只有这样才能在连接恢复正常之后继续实现命令传播,而无需传输整个`RDB`文件**。
##### 同步偏移量
主从服务器各自都会维护一个数据复制的偏移量,这个偏移量表示的是发送命令的字节数。下图就是一个刚建立连接的主从服务器,默认偏移量`offset`都是`0`:
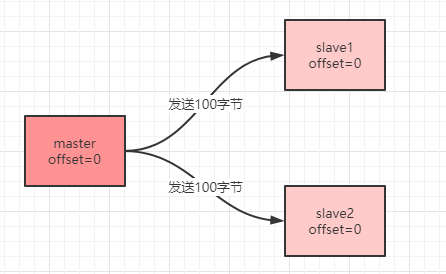
当主服务器向从服务器发送`100`字节之后,主从服务器的偏移量就会变成`100`。
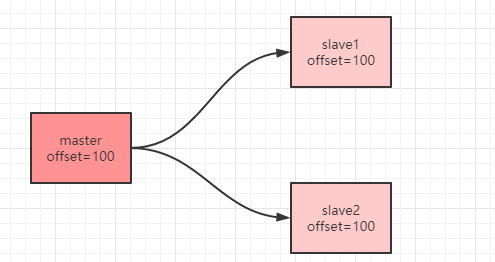
那么如果`master`再次向`slave1`和`slave2`传输了一个`200`字节的命令,`slave1`接收到了,而`slave2`没有接收到,就会出现以下情况:
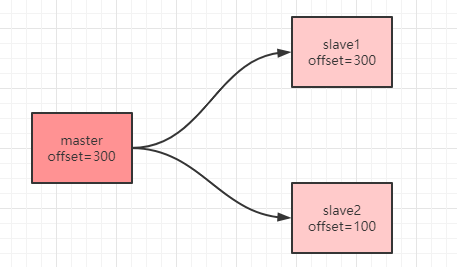
这时候当`slave2`再次和`master`恢复连接之后,此时`slave2`服务器会向主服务器发送同步命令,同步命令会带上偏移量。主服务器收到之后发现`slave2`发送过来的偏移量是`100`,而自己已经到`300`了,那么主服务器就会把`101`到`300`之间的命令再次进行发送给`slave2`,从而达到了部分重同步的目的。
##### 复制积压缓冲区
上面的部分重同步貌似看起来能解决问题,但是这又会带来另一个问题,那就是当主服务器将命令发送出去之后,**为了实现部分重同步还需要将命令保存起来,否则当从服务器的偏移量低于主服务器时,主服务器也无法将命令重传播。**
现在问题就是,这个命令要保存多久呢?这个也不可能一直保存下去,因为如果一直保存下去就会占据大量的空间。所以为了解决这个问题,`master`服务器维护了一个固定长度的`FIFO`队列,称之为**复制积压缓冲区**。
当进行命令传播的过程中,`master`服务器不仅会将命令传播给所有的`slave`服务器,同时还会将命令写入复制积压缓冲区。复制积压缓冲区默认大小为`1MB`。
当`master`服务器发现`slave`服务器传送过来的复制偏移量 +1 已经不在复制积压缓冲区的时候,就会执行一次全量同步,即发送`RDB`文件给从服务器,从服务器收到之后就会清空当前所有数据,然后再从主服务器发送过来的`RDB`文件中进行数据恢复。
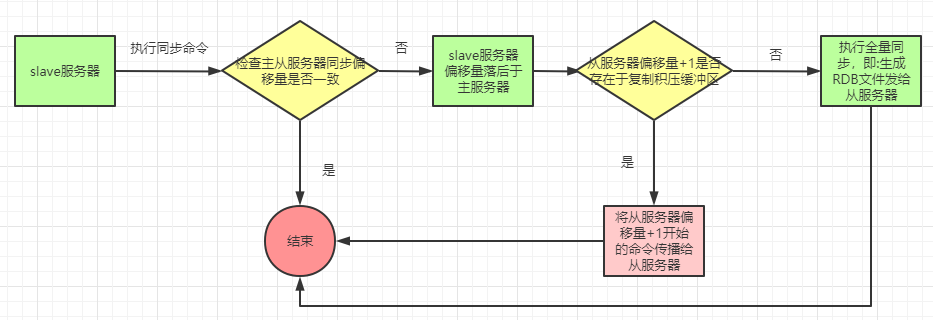
下面就是一个完整的部分重同步流程图:
- Redis 为什么这么快
- 什么是 Redis
- Redis 的安装
- Redis 到底有多快
- Redis 是单线程还是多线程
- Redis 为什么选择使用单线程来执行请求
- 什么是 IO 多路复用机制
- Redis 中 I/O 多路复用的应用
- 一个简单的字符串,为什么 Redis 要设计的如此特别
- Redis 的 9 种数据类型
- 二进制安全字符串
- sds 空间分配策略
- sds 和 C 语言字符串区别
- sds 是如何被存储的
- type 属性
- encoding 属性
- 通过牺牲速度来节省内存,Redis 是觉得自己太快了吗
- 什么是压缩列表
- ziplist 的存储结构
- entry 存储结构
- ziplist 数据示例
- ziplist 连锁更新问题
- 为了加快速度,Redis 都做了哪些“变态”设计
- 列表对象
- linkedlist
- linkedlist 和 ziplist 的选择
- quicklist
- 列表对象常用操作命令
- Redis 中哈希分布不均匀该怎么办
- 哈希对象
- hashtable
- ziplist
- ziplist 和 hashtable 的编码转换
- 哈希对象常用命令
- 同一份数据,Redis 为什么要存”两次”
- 五种基本类型之集合对象
- intset 编码
- 集合对象常用命令
- 五种基本类型之有序集合对象
- skiplist 编码
- ziplist 编码
- ziplist 和 skiplist 编码转换
- 有序集合对象常用命令
- 要想用活 Redis,Lua 脚本是绕不过去的坎
- 发布与订阅
- 基于频道的实现
- 基于模式的实现
- Lua 脚本
- Lua 脚本的调用
- Lua 脚本中执行 Redis 命令
- Lua 脚本摘要
- Lua 脚本文件
- 脚本异常
- 作为一款内存数据库,为什么断电后 Redis 数据不会丢失
- Redis 持久化机制
- RDB 持久化机制
- AOF 持久化机制
- 内存耗尽后 Redis 会发生什么
- 内存回收
- 过期策略
- 8 种淘汰策略
- LRU 算法
- LFU 算法
- 不能回滚的 Redis 事务还能用吗
- Redis 有事务吗
- Redis 事务实现原理
- Redis 事务 ACID 特性
- watch 命令
- watch 命令的作用
- watch 原理分析
- Redis 为什么不直接用 master-slave 集群
- Redis 集群方案
- 主从复制
- 配置一主两从 master-slave 集群
- 主从复制原理分析
- 主从服务的不足之处
- Sentinel(哨兵)机制为什么从神坛滑落
- 哨兵 Sentinel 机制
- Sentinel 原理分析
- 配置 Sentinel 集群
- Sentinel 机制实战
- Sentinel 机制的不足之处
- Redis Cluster 集群凭什么成为了最终的胜利者
- Redis 分布式集群方案
- 客户端实现分片
- 中间代理服务实现分片
- Redis Cluster 方案
- 手动配置一个 Redis Cluster 集群
- Redis Cluster 集群常用命令
- 客户端如何使用 Redis Cluster 集群
- Redis Cluster 的不足
- 如何从 10 亿数据中快速判断是否存在某一个元素
- 缓存雪崩
- 缓存击穿
- 缓存穿透
- 布隆过滤器(Bloom Filter)
- 布隆过滤器的 2 大特点
- 布隆过滤器的实现(Guava)
- 布隆过滤器的如何删除