
`Redis`中的`key-value`是通过`dictEntry`对象进行包装的,而哈希表就是将`dictEntry`对象进行了再一次的包装得到的,这就是哈希表对象`dictht`:
~~~c
typedef struct dictht {
dictEntry **table;//哈希表数组
unsigned long size;//哈希表大小
unsigned long sizemask;//掩码大小,用于计算索引值,总是等于size-1
unsigned long used;//哈希表中的已有节点数
} dictht;
~~~
注意:上面结构定义中的`table`是一个数组,其每个元素都是一个`dictEntry`对象。
#### 字典
字典,又称为符号表(symbol table),关联数组(associative array)或者映射(map),字典的内部嵌套了哈希表`dictht`对象,下面就是一个字典`ht`的定义:
~~~c
typedef struct dict {
dictType *type;//字典类型的一些特定函数
void *privdata;//私有数据,type中的特定函数可能需要用到
dictht ht[2];//哈希表(注意这里有2个哈希表)
long rehashidx; //rehash索引,不在rehash时,值为-1
unsigned long iterators; //正在使用的迭代器数量
} dict;
~~~
其中`dictType`内部定义了一些常用函数,其数据结构定义如下:
~~~c
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);//计算哈希值函数
void *(*keyDup)(void *privdata, const void *key);//复制键函数
void *(*valDup)(void *privdata, const void *obj);//复制值函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);//对比键函数
void (*keyDestructor)(void *privdata, void *key);//销毁键函数
void (*valDestructor)(void *privdata, void *obj);//销毁值函数
} dictType;
~~~
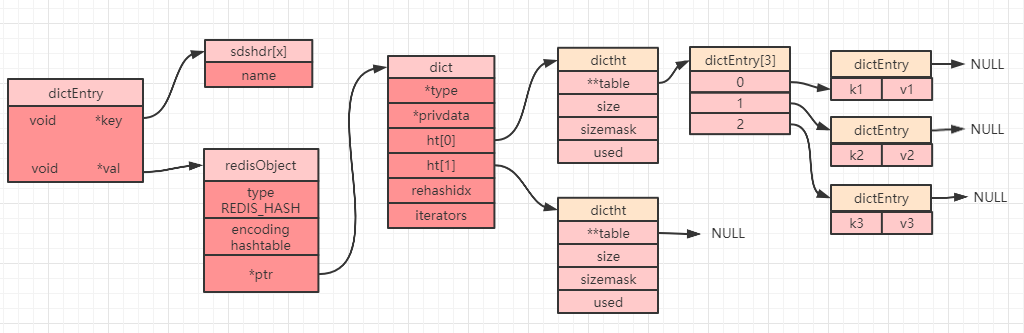
当我们创建一个哈希对象时,可以得到如下简图(部分属性被省略):
#### rehash 操作
`dict`中定义了一个数组`ht[2]`,`ht[2]`中定义了两个哈希表:`ht[0]`和`ht[1]`。而`Redis`在默认情况下只会使用`ht[0]`,并不会使用`ht[1]`,也不会为`ht[1]`初始化分配空间。
当设置一个哈希对象时,具体会落到哈希数组(上图中的`dictEntry[3]`)中的哪个下标,是通过计算哈希值来确定的,如果发生哈希碰撞,那么同一个下标就会有多个`dictEntry`,从而形成一个链表(上图中最右边指向`NULL`的位置),不过需要注意的是最后插入的元素总是落在链表的最前面(即发生哈希冲突时,总是将节点往链表的头部放)。
当读取数据的时候遇到一个节点有多个元素,就需要遍历链表,故链表越长,性能越差。为了保证哈希表的性能,需要在满足以下两个条件中的一个时,对哈希表进行`rehash`(重新散列)操作:
* 负载因子大于等于`1`且`dict_can_resize`为`1`时。
* 负载因子大于等于安全阈值(`dict_force_resize_ratio=5`)时。
PS:负载因子 = 哈希表已使用节点数 / 哈希表大小(即:`h[0].used/h[0].size`)。
#### rehash 步骤
扩展哈希和收缩哈希都是通过执行`rehash`来完成,这其中就涉及到了空间的分配和释放,主要经过以下五步:
1. 为字典`dict`的`ht[1]`哈希表分配空间,其大小取决于当前哈希表已保存节点数(即:`ht[0].used`):
* 如果是扩展操作则`ht[1]`的大小为`2`的`n`次方中第一个大于等于`ht[0].used * 2`属性的值(比如`used=3`,此时`ht[0].used * 2=6`,故`2`的`3`次方为`8`就是第一个大于`used * 2`的值(2 的 2 次方 6))。`
* 如果是收缩操作则`ht[1]`大小为 2 的 n 次方中第一个大于等于`ht[0].used`的值。
2. 将字典中的属性`rehashidx`的值设置为`0`,表示正在执行`rehash`操作。
3. 将`ht[0]`中所有的键值对依次重新计算哈希值,并放到`ht[1]`数组对应位置,每完成一个键值对的`rehash`之后`rehashidx`的值需要自增`1`。
4. 当`ht[0]`中所有的键值对都迁移到`ht[1]`之后,释放`ht[0]`,并将`ht[1]`修改为`ht[0]`,然后再创建一个新的`ht[1]`数组,为下一次`rehash`做准备。
5. 将字典中的属性`rehashidx`设置为`-1`,表示此次`rehash`操作结束,等待下一次`rehash`。
#### 渐进式 rehash
`Redis`中的这种重新哈希的操作因为不是一次性全部`rehash`,而是分多次来慢慢的将`ht[0]`中的键值对`rehash`到`ht[1]`,故而这种操作也称之为渐进式`rehash`。渐进式`rehash`可以避免集中式`rehash`带来的庞大计算量,是一种分而治之的思想。
在渐进式`rehash`过程中,因为还可能会有新的键值对存进来,此时`Redis`的做法是新添加的键值对统一放入`ht[1]`中,这样就确保了`ht[0]`键值对的数量只会减少。
当正在执行`rehash`操作时,如果服务器收到来自客户端的命令请求操作,则**会先查询`ht[0]`,查找不到结果再到`ht[1]`中查询**。
- Redis 为什么这么快
- 什么是 Redis
- Redis 的安装
- Redis 到底有多快
- Redis 是单线程还是多线程
- Redis 为什么选择使用单线程来执行请求
- 什么是 IO 多路复用机制
- Redis 中 I/O 多路复用的应用
- 一个简单的字符串,为什么 Redis 要设计的如此特别
- Redis 的 9 种数据类型
- 二进制安全字符串
- sds 空间分配策略
- sds 和 C 语言字符串区别
- sds 是如何被存储的
- type 属性
- encoding 属性
- 通过牺牲速度来节省内存,Redis 是觉得自己太快了吗
- 什么是压缩列表
- ziplist 的存储结构
- entry 存储结构
- ziplist 数据示例
- ziplist 连锁更新问题
- 为了加快速度,Redis 都做了哪些“变态”设计
- 列表对象
- linkedlist
- linkedlist 和 ziplist 的选择
- quicklist
- 列表对象常用操作命令
- Redis 中哈希分布不均匀该怎么办
- 哈希对象
- hashtable
- ziplist
- ziplist 和 hashtable 的编码转换
- 哈希对象常用命令
- 同一份数据,Redis 为什么要存”两次”
- 五种基本类型之集合对象
- intset 编码
- 集合对象常用命令
- 五种基本类型之有序集合对象
- skiplist 编码
- ziplist 编码
- ziplist 和 skiplist 编码转换
- 有序集合对象常用命令
- 要想用活 Redis,Lua 脚本是绕不过去的坎
- 发布与订阅
- 基于频道的实现
- 基于模式的实现
- Lua 脚本
- Lua 脚本的调用
- Lua 脚本中执行 Redis 命令
- Lua 脚本摘要
- Lua 脚本文件
- 脚本异常
- 作为一款内存数据库,为什么断电后 Redis 数据不会丢失
- Redis 持久化机制
- RDB 持久化机制
- AOF 持久化机制
- 内存耗尽后 Redis 会发生什么
- 内存回收
- 过期策略
- 8 种淘汰策略
- LRU 算法
- LFU 算法
- 不能回滚的 Redis 事务还能用吗
- Redis 有事务吗
- Redis 事务实现原理
- Redis 事务 ACID 特性
- watch 命令
- watch 命令的作用
- watch 原理分析
- Redis 为什么不直接用 master-slave 集群
- Redis 集群方案
- 主从复制
- 配置一主两从 master-slave 集群
- 主从复制原理分析
- 主从服务的不足之处
- Sentinel(哨兵)机制为什么从神坛滑落
- 哨兵 Sentinel 机制
- Sentinel 原理分析
- 配置 Sentinel 集群
- Sentinel 机制实战
- Sentinel 机制的不足之处
- Redis Cluster 集群凭什么成为了最终的胜利者
- Redis 分布式集群方案
- 客户端实现分片
- 中间代理服务实现分片
- Redis Cluster 方案
- 手动配置一个 Redis Cluster 集群
- Redis Cluster 集群常用命令
- 客户端如何使用 Redis Cluster 集群
- Redis Cluster 的不足
- 如何从 10 亿数据中快速判断是否存在某一个元素
- 缓存雪崩
- 缓存击穿
- 缓存穿透
- 布隆过滤器(Bloom Filter)
- 布隆过滤器的 2 大特点
- 布隆过滤器的实现(Guava)
- 布隆过滤器的如何删除