
传统的关系型数据库中,一个事务一般都具有`ACID`特性。那么现在就让我们来分析一下`Redis`是否也满足这`ACID`四大特性。
#### A - 原子性
在讨论事务的原子性之前,我们先来看`2`个例子。
* 模拟事务在执行命令前发生异常。依次执行以下命令:
~~~java
multi //开启事务
set name lonely_wolf //设置 name,此时 Redis 会将命令放入队列
get //执行一个不完成的命令,此时会报错
exec //在发生异常后提交事务
~~~
最终得到了如下图所示的结果,我们可以看到,当命令入队时报错,事务已经被取消了:

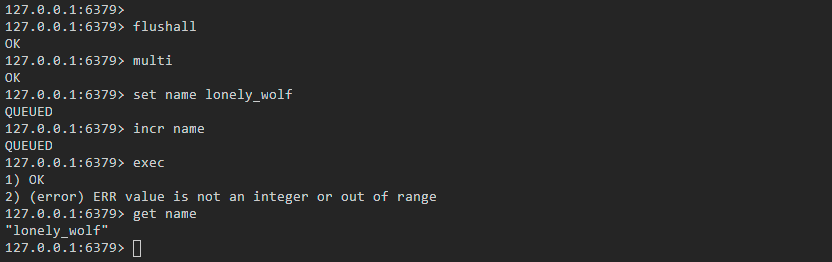
* 模拟事务在执行命令前发生异常。依次执行以下命令:
~~~java
flushall //为了防止影响,先清空数据库
multi //开启事务
set name lonely_wolf //设置 name,此时 Redis 会将命令放入队列
incr name //这个命令只能用于 value 为整数的字符串对象,此时执行会报错
exec //提交事务,此时在执行第一条命令成功,执行第二条命令失败
get name //获取 name 的值
~~~
最终得到了如下图所示的结果。我们可以看到,当执行事务报错的时候,之前已经成功的命令并没有被回滚,也就是说**在执行事务的时候某一个命令失败了,并不会影响其它命令的执行,即`Redis`的事务并不会回滚**:
#### Redis 中的事务为什么不会滚
这个问题的答案在`Redis`官网中给出了明确的解释:

总结起来主要就是`3`个原因:
* `Redis`作者认为发生事务回滚的原因大部分都是程序错误导致,这种情况一般发生在开发和测试阶段,而生产环境很少出现。
* 对于逻辑性错误,比如本来应该把一个数加`1`,但是程序逻辑写成了加`2`,那么这种错误也是无法通过事务回滚来进行解决的。
* `Redis`追求的是简单高效,而传统事务的实现相对比较复杂,这和`Redis`的设计思想相违背。
#### C - 一致性
一致性指的就是事务执行前后的数据符合数据库的定义和要求。这一点`Redis`中的事务是符合要求的,上面讲述原子性的时候已经提到,不论是发生语法错误还是运行时错误,错误的命令均不会被执行。
#### I - 隔离性
事务中的所有命令都会按顺序执行,在执行`Redis`事务的过程中,另一个客户端发出的请求不可能被服务,这保证了命令是作为单独的独立操作执行的。所以`Redis`当中的事务是符合隔离性要求的。
#### D - 持久性
如果`Redis`当中没有被开启持久化,那么就是纯内存运行的,一旦重启,所有数据都会丢失,此时可以认为`Redis`不具备事务的持久性;而如果`Redis`开启了持久化,那么可以认为`Redis`在特定条件下是具备持久性的。
- Redis 为什么这么快
- 什么是 Redis
- Redis 的安装
- Redis 到底有多快
- Redis 是单线程还是多线程
- Redis 为什么选择使用单线程来执行请求
- 什么是 IO 多路复用机制
- Redis 中 I/O 多路复用的应用
- 一个简单的字符串,为什么 Redis 要设计的如此特别
- Redis 的 9 种数据类型
- 二进制安全字符串
- sds 空间分配策略
- sds 和 C 语言字符串区别
- sds 是如何被存储的
- type 属性
- encoding 属性
- 通过牺牲速度来节省内存,Redis 是觉得自己太快了吗
- 什么是压缩列表
- ziplist 的存储结构
- entry 存储结构
- ziplist 数据示例
- ziplist 连锁更新问题
- 为了加快速度,Redis 都做了哪些“变态”设计
- 列表对象
- linkedlist
- linkedlist 和 ziplist 的选择
- quicklist
- 列表对象常用操作命令
- Redis 中哈希分布不均匀该怎么办
- 哈希对象
- hashtable
- ziplist
- ziplist 和 hashtable 的编码转换
- 哈希对象常用命令
- 同一份数据,Redis 为什么要存”两次”
- 五种基本类型之集合对象
- intset 编码
- 集合对象常用命令
- 五种基本类型之有序集合对象
- skiplist 编码
- ziplist 编码
- ziplist 和 skiplist 编码转换
- 有序集合对象常用命令
- 要想用活 Redis,Lua 脚本是绕不过去的坎
- 发布与订阅
- 基于频道的实现
- 基于模式的实现
- Lua 脚本
- Lua 脚本的调用
- Lua 脚本中执行 Redis 命令
- Lua 脚本摘要
- Lua 脚本文件
- 脚本异常
- 作为一款内存数据库,为什么断电后 Redis 数据不会丢失
- Redis 持久化机制
- RDB 持久化机制
- AOF 持久化机制
- 内存耗尽后 Redis 会发生什么
- 内存回收
- 过期策略
- 8 种淘汰策略
- LRU 算法
- LFU 算法
- 不能回滚的 Redis 事务还能用吗
- Redis 有事务吗
- Redis 事务实现原理
- Redis 事务 ACID 特性
- watch 命令
- watch 命令的作用
- watch 原理分析
- Redis 为什么不直接用 master-slave 集群
- Redis 集群方案
- 主从复制
- 配置一主两从 master-slave 集群
- 主从复制原理分析
- 主从服务的不足之处
- Sentinel(哨兵)机制为什么从神坛滑落
- 哨兵 Sentinel 机制
- Sentinel 原理分析
- 配置 Sentinel 集群
- Sentinel 机制实战
- Sentinel 机制的不足之处
- Redis Cluster 集群凭什么成为了最终的胜利者
- Redis 分布式集群方案
- 客户端实现分片
- 中间代理服务实现分片
- Redis Cluster 方案
- 手动配置一个 Redis Cluster 集群
- Redis Cluster 集群常用命令
- 客户端如何使用 Redis Cluster 集群
- Redis Cluster 的不足
- 如何从 10 亿数据中快速判断是否存在某一个元素
- 缓存雪崩
- 缓存击穿
- 缓存穿透
- 布隆过滤器(Bloom Filter)
- 布隆过滤器的 2 大特点
- 布隆过滤器的实现(Guava)
- 布隆过滤器的如何删除