
`skiplist`即跳跃表,有时候也简称为跳表。使用`skiplist`编码的有序集合对象使用了`zset`结构来作为底层实现,而`zset`中同时包含了一个字典和一个跳跃表。
#### 跳跃表
跳跃表是一种有序的数据结构,其主要特点是通过在每个节点中维持多个指向其它节点的指针,从而达到快速访问节点的目的。
大部分情况下,跳跃表的效率可以等同于平衡树,但是跳跃表的实现却远远比平衡树的实现简单,所以`Redis`选择了使用跳跃表来实现有序集合。
下图是一个普通的有序链表,我们如果想要找到`35`这个元素,只能从头开始遍历到尾(**链表中元素不支持随机访问,所以不能用二分查找,而数组中可以通过下标随机访问,所以二分查找一般适用于有序数组**),时间复杂度是`O(n)`。

那么假如我们可以直接跳到链表的中间,那就可以节省很多资源了,这就是跳表的原理,如下图所示就是一个跳表的数据结构示例:
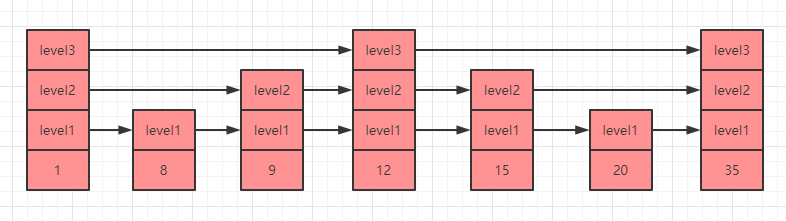
上图中`level1`、`level2`、`level3`就是跳表的层级,每一个`level`层级都有一个指向下一个相同`level`层级元素的指针,比如上图我们遍历寻找元素`35`的时候就有三种方案:
* 第`1`种:执行`level1`层级的指针,需要遍历`7`次(1->8->9->12->15->20->35)才能找到元素`35`。
* 第`2`种:执行`level2`层级的指针,只需要遍历`5`次(1->9->12->15->35)就能找到元素`35`。
* 第`3`种:执行`level3`层级的元素,这时候只需要遍历`3`次(1->12->35)就能找到元素`35`了,大大提升了效率。
#### skiplist 的存储结构
跳跃表中的每个节点是一个`zskiplistNode`节点(源码`server.h`内):
~~~c
typedef struct zskiplistNode {
sds ele;//元素
double score;//分值
struct zskiplistNode *backward;//后退指针
struct zskiplistLevel {//层
struct zskiplistNode *forward;//前进指针
unsigned long span;//当前节点到下一个节点的跨度(跨越的节点数)
} level[];
} zskiplistNode;
~~~
* level(层)
`level`即跳跃表中的层,其是一个数组,也就是说一个节点的元素可以拥有多个层,即多个指向其它节点的指针,程序可以通过不同层级的指针来选择最快捷的路径提升访问速度。
`level`是在每次创建新节点的时候根据幂次定律(power law)随机生成的一个介于`1~32`之间的数字。
* `forward`(前进指针)
每个层都会有一个指向链表尾部方向元素的指针,遍历元素的时候需要使用到前进指针。
* `span`(跨度)
跨度记录了两个节点之间的距离,需要注意的是,如果指向了`NULL`的话,则跨度为`0`。
* `backward`(后退指针)
和前进指针不一样的是后退指针只有一个,所以每次只能后退至前一个节点(上图中没有画出后退指针)。
* `ele`(元素)
跳跃表中元素是一个`sds`对象(早期版本使用的是`redisObject`对象),元素必须唯一、不能重复。
* `score`(分值)
节点的分值是一个`double`类型的浮点数,跳跃表中会将节点按照分值从小到大的顺序排列,不同节点的分值可以重复。
上面介绍的只是跳跃表中的一个节点,多个`zskiplistNode`节点组成了一个`zskiplist`对象:
~~~c
typedef struct zskiplist {
struct zskiplistNode *header, *tail;//跳跃表的头节点和尾结点指针
unsigned long length;//跳跃表的节点数
int level;//所有节点中最大的层数
} zskiplist;
~~~
到这里你可能以为有序集合就是用这个`zskiplist`来实现的,然而实际上`Redis`并没有直接使用`zskiplist`来实现,而是用`zset`对象再次进行了一层包装。
~~~c
typedef struct zset {
dict *dict;//字典对象
zskiplist *zsl;//跳跃表对象
} zset;
~~~
所以最终,一个有序集合如果使用了`skiplist`编码,其数据结构如下图所示:
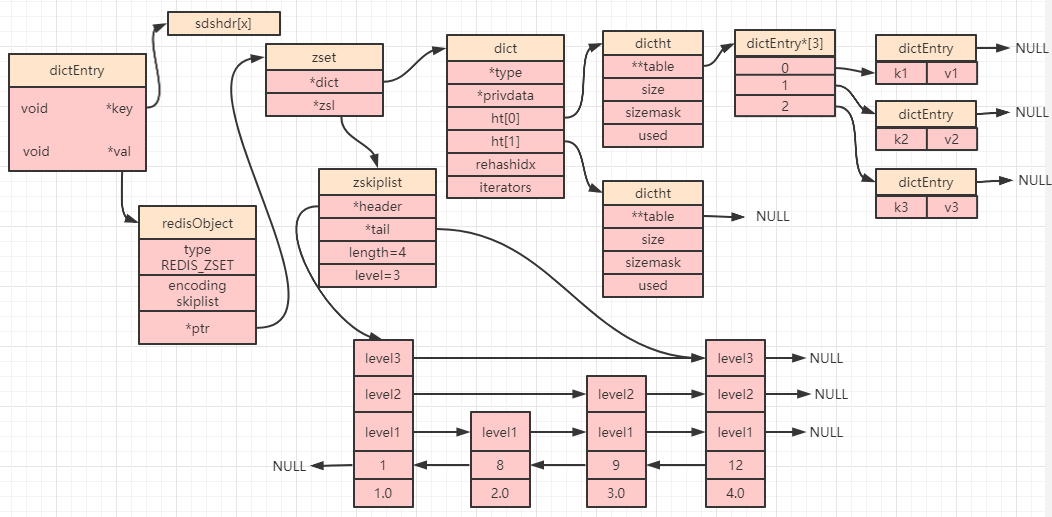
上图中,上面一部分的字典中的`key`就是对应了有序集合中的元素(`member`),`value`就对应了分值(`score`);下面一部分中跳跃表整数`1,8,9,12`也是对应了元素(`member`),最后一排的`double`型数字就是分值(`score`)。
也就是说字典和跳跃表中的数据都指向了我们存储的元素(**两种数据结构最终指向的是同一个地址,所以数据并不会出现冗余存储**),`Redis`为什么要这么做呢?
#### 为什么同时选择使用字典和跳跃表
有序集合直接使用跳跃表或者单独使用字典完全可以独自实现,但是我们想一下:
* 如果单独使用跳跃表来实现,那么虽然可以使用跨度大的指针去遍历元素来找到我们需要的数据,但是其复杂度仍然达到了`O(logN)`,而字典中获取一个元素的复杂度是`O(1)`。
* 如果单独使用字典,虽然获取元素很快,但是字典是无序的,所以如果要范围查找就需要对其进行排序,这又是一个耗时的操作。
所以`Redis`综合了两种数据结构来最大程度的提升性能,这也是`Redis`设计的精妙之处。
- Redis 为什么这么快
- 什么是 Redis
- Redis 的安装
- Redis 到底有多快
- Redis 是单线程还是多线程
- Redis 为什么选择使用单线程来执行请求
- 什么是 IO 多路复用机制
- Redis 中 I/O 多路复用的应用
- 一个简单的字符串,为什么 Redis 要设计的如此特别
- Redis 的 9 种数据类型
- 二进制安全字符串
- sds 空间分配策略
- sds 和 C 语言字符串区别
- sds 是如何被存储的
- type 属性
- encoding 属性
- 通过牺牲速度来节省内存,Redis 是觉得自己太快了吗
- 什么是压缩列表
- ziplist 的存储结构
- entry 存储结构
- ziplist 数据示例
- ziplist 连锁更新问题
- 为了加快速度,Redis 都做了哪些“变态”设计
- 列表对象
- linkedlist
- linkedlist 和 ziplist 的选择
- quicklist
- 列表对象常用操作命令
- Redis 中哈希分布不均匀该怎么办
- 哈希对象
- hashtable
- ziplist
- ziplist 和 hashtable 的编码转换
- 哈希对象常用命令
- 同一份数据,Redis 为什么要存”两次”
- 五种基本类型之集合对象
- intset 编码
- 集合对象常用命令
- 五种基本类型之有序集合对象
- skiplist 编码
- ziplist 编码
- ziplist 和 skiplist 编码转换
- 有序集合对象常用命令
- 要想用活 Redis,Lua 脚本是绕不过去的坎
- 发布与订阅
- 基于频道的实现
- 基于模式的实现
- Lua 脚本
- Lua 脚本的调用
- Lua 脚本中执行 Redis 命令
- Lua 脚本摘要
- Lua 脚本文件
- 脚本异常
- 作为一款内存数据库,为什么断电后 Redis 数据不会丢失
- Redis 持久化机制
- RDB 持久化机制
- AOF 持久化机制
- 内存耗尽后 Redis 会发生什么
- 内存回收
- 过期策略
- 8 种淘汰策略
- LRU 算法
- LFU 算法
- 不能回滚的 Redis 事务还能用吗
- Redis 有事务吗
- Redis 事务实现原理
- Redis 事务 ACID 特性
- watch 命令
- watch 命令的作用
- watch 原理分析
- Redis 为什么不直接用 master-slave 集群
- Redis 集群方案
- 主从复制
- 配置一主两从 master-slave 集群
- 主从复制原理分析
- 主从服务的不足之处
- Sentinel(哨兵)机制为什么从神坛滑落
- 哨兵 Sentinel 机制
- Sentinel 原理分析
- 配置 Sentinel 集群
- Sentinel 机制实战
- Sentinel 机制的不足之处
- Redis Cluster 集群凭什么成为了最终的胜利者
- Redis 分布式集群方案
- 客户端实现分片
- 中间代理服务实现分片
- Redis Cluster 方案
- 手动配置一个 Redis Cluster 集群
- Redis Cluster 集群常用命令
- 客户端如何使用 Redis Cluster 集群
- Redis Cluster 的不足
- 如何从 10 亿数据中快速判断是否存在某一个元素
- 缓存雪崩
- 缓存击穿
- 缓存穿透
- 布隆过滤器(Bloom Filter)
- 布隆过滤器的 2 大特点
- 布隆过滤器的实现(Guava)
- 布隆过滤器的如何删除