
`LFU`全称为`Least Frequently Used`。即:最近最少频率使用,这个主要针对的是使用频率。这个属性也是记录在`redisObject`中的`lru`属性内。
当我们采用`LFU`回收策略时,`lru`属性的高`16`位用来记录访问时间(last decrement time:ldt,单位为分钟),低`8`位用来记录访问频率(logistic counter:logc),简称`counter`。
#### 访问频次递增
`LFU`计数器每个键只有`8`位,它能表示的最大值是`255`,所以`Redis`使用的是一种基于概率的对数器来实现`counter`的递增。
给定一个旧的访问频次,当一个键被访问时,`counter`按以下方式递增:
1. 提取`0`和`1`之间的随机数`R`。
2. `counter`\- 初始值(默认为`5`),得到一个基础差值,如果这个差值小于`0`,则直接取`0`,为了方便计算,把这个差值记为`baseval`。
3. 概率`P`计算公式为:`1/(baseval * lfu_log_factor + 1)`。
4. 如果`R < P`时,频次进行递增(`counter++`)。
公式中的`lfu_log_factor`称之为对数因子,默认是`10`,可以通过参数来进行控制:
~~~
lfu_log_factor 10
~~~
下图就是对数因子`lfu_log_factor`和频次`counter`增长的关系图:
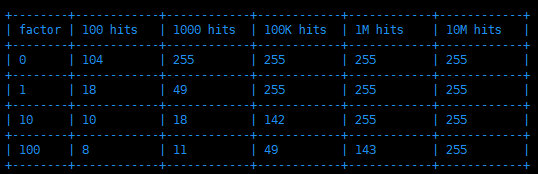
可以看到,当对数因子`lfu_log_factor`为`100`时,大概是`10M(1000万)`次访问才会将访问`counter`增长到`255`,而默认的`10`也能支持到`1M(100万)`次访问`counter`才能达到`255`上限,这在大部分场景都是足够满足需求的。
#### 访问频次递减
如果访问频次`counter`只是一直在递增,那么迟早会全部都到`255`,也就是说`counter`一直递增不能完全反应一个`key`的热度,所以当某一个`key`一段时间不被访问之后,`counter`也需要对应减少。
`counter`的减少速度由参数`lfu-decay-time`进行控制,默认是`1`,单位是分钟。默认值`1`表示:`N`分钟内没有访问,`counter`就要减`N`。
~~~
lfu-decay-time 1
~~~
具体算法如下:
1. 获取当前时间戳,转化为**分钟**后取低`16`位(为了方便后续计算,这个值记为`now`)。
2. 取出对象内的`lru`属性中的高`16`位(为了方便后续计算,这个值记为`ldt`)。
3. 当`lru`\>`now`时,默认为过了一个周期(`16`位,最大`65535`),则取差值`65535-ldt+now`:当`lru`<=`now`时,取差值`now-ldt`(为了方便后续计算,这个差值记为`idle_time`)。
4. 取出配置文件中的`lfu_decay_time`值,然后计算:`idle_time / lfu_decay_time`(为了方便后续计算,这个值记为`num_periods`)。
5. 最后将`counter`减少:`counter - num_periods`。
看起来这么复杂,其实计算公式就是一句话:
取出当前的时间戳和对象中的`lru`属性进行对比,计算出当前多久没有被访问到,比如计算得到的结果是`100`分钟没有被访问,然后再去除配置参数`lfu_decay_time`;如果这个配置默认为`1`也即是`100/1=100`,代表`100`分钟没访问,所以`counter`就减少`100`。
- Redis 为什么这么快
- 什么是 Redis
- Redis 的安装
- Redis 到底有多快
- Redis 是单线程还是多线程
- Redis 为什么选择使用单线程来执行请求
- 什么是 IO 多路复用机制
- Redis 中 I/O 多路复用的应用
- 一个简单的字符串,为什么 Redis 要设计的如此特别
- Redis 的 9 种数据类型
- 二进制安全字符串
- sds 空间分配策略
- sds 和 C 语言字符串区别
- sds 是如何被存储的
- type 属性
- encoding 属性
- 通过牺牲速度来节省内存,Redis 是觉得自己太快了吗
- 什么是压缩列表
- ziplist 的存储结构
- entry 存储结构
- ziplist 数据示例
- ziplist 连锁更新问题
- 为了加快速度,Redis 都做了哪些“变态”设计
- 列表对象
- linkedlist
- linkedlist 和 ziplist 的选择
- quicklist
- 列表对象常用操作命令
- Redis 中哈希分布不均匀该怎么办
- 哈希对象
- hashtable
- ziplist
- ziplist 和 hashtable 的编码转换
- 哈希对象常用命令
- 同一份数据,Redis 为什么要存”两次”
- 五种基本类型之集合对象
- intset 编码
- 集合对象常用命令
- 五种基本类型之有序集合对象
- skiplist 编码
- ziplist 编码
- ziplist 和 skiplist 编码转换
- 有序集合对象常用命令
- 要想用活 Redis,Lua 脚本是绕不过去的坎
- 发布与订阅
- 基于频道的实现
- 基于模式的实现
- Lua 脚本
- Lua 脚本的调用
- Lua 脚本中执行 Redis 命令
- Lua 脚本摘要
- Lua 脚本文件
- 脚本异常
- 作为一款内存数据库,为什么断电后 Redis 数据不会丢失
- Redis 持久化机制
- RDB 持久化机制
- AOF 持久化机制
- 内存耗尽后 Redis 会发生什么
- 内存回收
- 过期策略
- 8 种淘汰策略
- LRU 算法
- LFU 算法
- 不能回滚的 Redis 事务还能用吗
- Redis 有事务吗
- Redis 事务实现原理
- Redis 事务 ACID 特性
- watch 命令
- watch 命令的作用
- watch 原理分析
- Redis 为什么不直接用 master-slave 集群
- Redis 集群方案
- 主从复制
- 配置一主两从 master-slave 集群
- 主从复制原理分析
- 主从服务的不足之处
- Sentinel(哨兵)机制为什么从神坛滑落
- 哨兵 Sentinel 机制
- Sentinel 原理分析
- 配置 Sentinel 集群
- Sentinel 机制实战
- Sentinel 机制的不足之处
- Redis Cluster 集群凭什么成为了最终的胜利者
- Redis 分布式集群方案
- 客户端实现分片
- 中间代理服务实现分片
- Redis Cluster 方案
- 手动配置一个 Redis Cluster 集群
- Redis Cluster 集群常用命令
- 客户端如何使用 Redis Cluster 集群
- Redis Cluster 的不足
- 如何从 10 亿数据中快速判断是否存在某一个元素
- 缓存雪崩
- 缓存击穿
- 缓存穿透
- 布隆过滤器(Bloom Filter)
- 布隆过滤器的 2 大特点
- 布隆过滤器的实现(Guava)
- 布隆过滤器的如何删除