
`LRU`全称为`Least Recently Used`。即:最近最长时间未被使用。这个主要针对的是使用时间。
#### Redis 改进后的 LRU 算法
在`Redis`当中,并没有采用传统的`LRU`算法,因为传统的`LRU`算法存在`2`个问题:
* 需要额外的空间进行存储。
* 可能存在某些`key`值使用很频繁,但是最近没被使用,从而被`LRU`算法删除。
为了避免以上`2`个问题,`Redis`当中对传统的`LRU`算法进行了改造,**通过抽样的方式进行删除**。
配置文件中提供了一个属性`maxmemory_samples 5`,默认值就是`5`,表示随机抽取`5`个`key`值,然后对这`5`个`key`值按照`LRU`算法进行删除,所以很明显`key`值越大,删除的准确度越高。
对抽样`LRU`算法和传统的`LRU`算法,`Redis`官网当中有一个对比图:
* 浅灰色带是被删除的对象。
* 灰色带是未被删除的对象。
* 绿色是添加的对象。
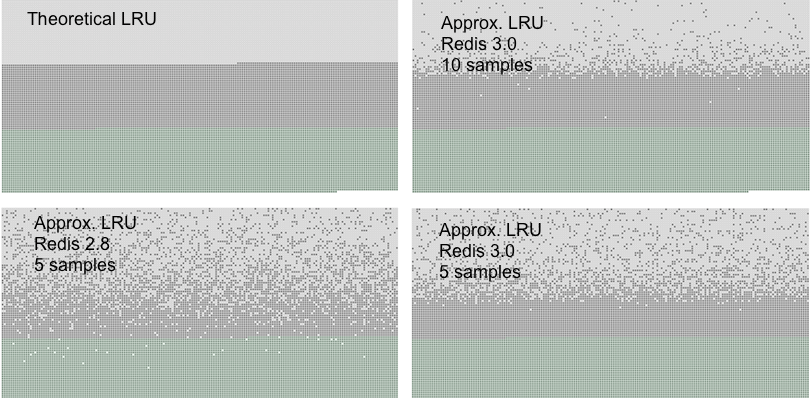
左上角第一幅图代表的是传统`LRU`算法。可以看到,当抽样数达到`10`个(右上角),已经和传统的`LRU`算法非常接近了。
#### Redis 如何管理热度数据
前面我们讲述字符串对象时,提到了`redisObject`对象中存在一个`lru`属性:
~~~c
typedef struct redisObject {
unsigned type:4;//对象类型(4位=0.5字节)
unsigned encoding:4;//编码(4位=0.5字节)
unsigned lru:LRU_BITS;//记录对象最后一次被应用程序访问的时间(24位=3字节)
int refcount;//引用计数。等于0时表示可以被垃圾回收(32位=4字节)
void *ptr;//指向底层实际的数据存储结构,如:SDS等(8字节)
} robj;
~~~
`lru`属性是创建对象的时候写入,对象被访问到时也会进行更新。正常人的思路就是最后决定要不要删除某一个键肯定是用当前时间戳减去`lru`,差值最大的就优先被删除。但是`Redis`里面并不是这么做的,`Redis`中维护了一个全局属性`lru_clock`,这个属性是通过一个全局函数`serverCron`每隔`100`毫秒执行一次来更新的,记录的是当前`unix`时间戳。
最后决定删除的数据是通过`lru_clock`减去对象的`lru`属性而得出的。那么为什么`Redis`要这么做呢?直接取全局时间不是更准确吗?
这是因为这么做可以避免每次更新对象的`lru`属性的时候可以直接取全局属性,而不需要去调用系统函数来获取系统时间,从而提升效率(`Redis`当中有很多这种细节考虑来提升性能,可以说是对性能尽可能的优化到极致)。
不过这里还有一个问题,我们看到`redisObject`对象中的`lru`属性只有`24`位,`24`位只能存储`194`天的时间戳大小,一旦超过`194`天之后就会重新从`0`开始计算,所以这时候就可能会出现`redisObject`对象中的`lru`属性大于全局的`lru_clock`属性的情况。
正因为如此,所以计算的时候也需要分为`2`种情况:
* 当全局`lruclock`\>`lru`,则使用`lruclock`\-`lru`得到空闲时间。
* 当全局`lruclock`<`lru`,则使用`lruclock_max`(即`194`天) -`lru`+`lruclock`得到空闲时间。
需要注意的是,这种计算方式并不能保证抽样的数据中一定能删除空闲时间最长的。这是因为首先超过`194`天还不被使用的情况很少,再次只有`lruclock`第`2`轮继续超过`lru`属性时,计算才会出问题。
比如对象`A`记录的`lru`是`1`天,而`lruclock`第二轮都到`10`天了,这时候就会导致计算结果只有`10-1=9`天,实际上应该是`194+10-1=203`天。但是这种情况可以说又是更少发生,所以说这种处理方式是可能存在删除不准确的情况,但是本身这种算法就是一种近似的算法,所以并不会有太大影响。
- Redis 为什么这么快
- 什么是 Redis
- Redis 的安装
- Redis 到底有多快
- Redis 是单线程还是多线程
- Redis 为什么选择使用单线程来执行请求
- 什么是 IO 多路复用机制
- Redis 中 I/O 多路复用的应用
- 一个简单的字符串,为什么 Redis 要设计的如此特别
- Redis 的 9 种数据类型
- 二进制安全字符串
- sds 空间分配策略
- sds 和 C 语言字符串区别
- sds 是如何被存储的
- type 属性
- encoding 属性
- 通过牺牲速度来节省内存,Redis 是觉得自己太快了吗
- 什么是压缩列表
- ziplist 的存储结构
- entry 存储结构
- ziplist 数据示例
- ziplist 连锁更新问题
- 为了加快速度,Redis 都做了哪些“变态”设计
- 列表对象
- linkedlist
- linkedlist 和 ziplist 的选择
- quicklist
- 列表对象常用操作命令
- Redis 中哈希分布不均匀该怎么办
- 哈希对象
- hashtable
- ziplist
- ziplist 和 hashtable 的编码转换
- 哈希对象常用命令
- 同一份数据,Redis 为什么要存”两次”
- 五种基本类型之集合对象
- intset 编码
- 集合对象常用命令
- 五种基本类型之有序集合对象
- skiplist 编码
- ziplist 编码
- ziplist 和 skiplist 编码转换
- 有序集合对象常用命令
- 要想用活 Redis,Lua 脚本是绕不过去的坎
- 发布与订阅
- 基于频道的实现
- 基于模式的实现
- Lua 脚本
- Lua 脚本的调用
- Lua 脚本中执行 Redis 命令
- Lua 脚本摘要
- Lua 脚本文件
- 脚本异常
- 作为一款内存数据库,为什么断电后 Redis 数据不会丢失
- Redis 持久化机制
- RDB 持久化机制
- AOF 持久化机制
- 内存耗尽后 Redis 会发生什么
- 内存回收
- 过期策略
- 8 种淘汰策略
- LRU 算法
- LFU 算法
- 不能回滚的 Redis 事务还能用吗
- Redis 有事务吗
- Redis 事务实现原理
- Redis 事务 ACID 特性
- watch 命令
- watch 命令的作用
- watch 原理分析
- Redis 为什么不直接用 master-slave 集群
- Redis 集群方案
- 主从复制
- 配置一主两从 master-slave 集群
- 主从复制原理分析
- 主从服务的不足之处
- Sentinel(哨兵)机制为什么从神坛滑落
- 哨兵 Sentinel 机制
- Sentinel 原理分析
- 配置 Sentinel 集群
- Sentinel 机制实战
- Sentinel 机制的不足之处
- Redis Cluster 集群凭什么成为了最终的胜利者
- Redis 分布式集群方案
- 客户端实现分片
- 中间代理服务实现分片
- Redis Cluster 方案
- 手动配置一个 Redis Cluster 集群
- Redis Cluster 集群常用命令
- 客户端如何使用 Redis Cluster 集群
- Redis Cluster 的不足
- 如何从 10 亿数据中快速判断是否存在某一个元素
- 缓存雪崩
- 缓存击穿
- 缓存穿透
- 布隆过滤器(Bloom Filter)
- 布隆过滤器的 2 大特点
- 布隆过滤器的实现(Guava)
- 布隆过滤器的如何删除