
`AOF`全称为:`Append Only File`,是`Redis`当中提供的另一种持久化机制。`AOF`采用日志的形式将每个写操作追加到文件中。开启`AOF`机制后,只要执行更改`Redis`数据的命令时,命令就会被写入到`AOF`文件中。在`Redis`重启的时候会根据日志内容依次执行`AOF`文件中的命令来恢复数据。
**`AOF`和`RDB`最大的不同是:`AOF`记录的是执行命令(类似于`MySQL`中`binlog`的`statement`格式),而`RDB`记录的是数据(类似于`MySQL`中`binlog`的`row`格式)。**
需要注意的是:假如同时开启了`RDB`和`AOF`两种机制,那么`Redis`会优先选择`AOF`持久化文件来进行数据恢复。
#### AOF 机制如何开启
`AOF`机制默认是关闭的,可以通过以下配置文件进行修改
~~~
appendonly no #是否开启AOF机制,默认是no表示关闭,修改为yes则表示开启
appendfilename "appendonly.aof" #AOF文件名
~~~
PS:和`RDB`机制一样,其生成文件的路径也是通过`dir`属性进行配置。
#### AOF 机制数据是否实时写入磁盘
`AOF`机制下数据是否实时写入磁盘,这个和`MySQL`的`redo log`机制很类似,也是需要通过参数来进行控制。
`AOF`数据何时写入磁盘由参数`appendfsync`来进行控制:
| appendfsync | 描述 | 备注 |
| --- | --- | --- |
| always | 写入缓存的同时通知操作系统刷新(fsync)到磁盘(但是也可能会有部分操作系统只是尽快刷盘,而不是实时刷盘) | Slow, Safest |
| everysec | 先写入缓存,然后每秒中刷一次盘(**默认值**),这种模式极端情况可能会丢失`1s`的数据 | Compromise |
| no | 只写入缓存,什么时候刷盘由操作系统自己决定 | Faster |
#### AOF 文件重写
`AOF`机制主要是通过记录执行命令的方式来实现的,那么随着时间的增加,`AOF`文件不可避免的会越来越大,而且可能会出现很多冗余命令。比如同一个`key`值执行了`10000`次`set`操作,实际上前面`9999`次对恢复数据来说都是没用的,只需要执行最后一次命令就可以把数据恢复,正是为了避免这种问题,`AOF`机制就提供了文件重写功能。
1. 重写原理分析
`AOF`重写时`Redis`并不会去分析原有的文件,因为如果原有文件过大,分析也会很耗时,所以`Redis`选择的做法就是重新去`Redis`中读取现有的键值对,然后用一条命令记录键值对的值。
只使用一条命令也有一个前提,那就是一个集合键或者列表键或者哈希键内包含的元素不能超过`64`个,一旦超过`64`个,就会使用多条命令来进行记录。
2. AOF 重写缓冲区
`AOF`重写的时候一般都会有大量的写操作,所以为了不阻塞客户端的命令请求,`Redis`会把重写操作放入到子进程中执行,但是放入子进程中执行也会带来一个问题,那就是重写期间如果同时又执行了客户端发过来的命令,又该如何保证数据的一致性?
为了解决数据不一致问题,`Redis`中引入了一个`AOF`重写缓冲区。当开始执行`AOF`文件重写之后又接收到客户端的请求命令,不但要将命令写入原本的`AOF`缓冲区(根据上面提到的参数刷盘),还要同时写入`AOF`重写缓冲区:
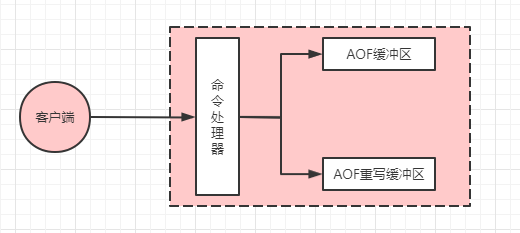
一旦子进程完成了`AOF`文件的重写,此时会向父进程发出信号,父进程收到信号之后会进行阻塞(阻塞期间不执行任何命令),并进行以下两项工作:
* 将`AOF`重写缓冲区的文件刷新到新的`AOF`文件内。
* 将新`AOF`文件进行改名并原子的替换掉旧的`AOF`文件。
完成了上面的两项工作之后,整个`AOF`重写工作完成,父进程开始正常接收命令。
#### AOF 机制触发条件
`AOF`机制的触发条件同样也分为自动触发和手动触发。
* 自动触发:自动触发可以通过以下参数进行设置。
~~~
auto-aof-rewrite-percentag #文件大小超过上次AOF重写之后的文件的百分比。默认100,也就是默认达到上一次AOF重写文件的2倍之后会再次触发AOF重写
auto-aof-rewrite-min-size #设置允许重写的最小AOF文件大小,默认是64M。主要是避免满足了上面的百分比,但是文件还是很小的情况。
~~~
* 手动触发:执行`bgrewriteaof`命令。
注意:`bgrewriteaof`命令也不能和上面`RDB`持久化命令`bgsave`同时执行,这么做是为了避免同时创建两个子进程来同时执行大量写磁盘操作,影响到`Redis`的性能。
#### AOF 机制优点
* 使用`AOF`机制,可以自由选择不同`fsync`(刷盘)策略,而且在默认策略下最多也仅仅是损失`1s`的数据。
* `AOF`日志是一个仅追加的日志,因此如果出现断电,也不存在查找或损坏问题。即使由于某些原因(磁盘已满或其它原因),日志已经写了一半的命令结束,`redis-check-aof`工具也能够轻松地修复它。
* 当`AOF`文件变得太大时,`Redis`能够在后台自动重写。
* 不同于`RDB`的文件格式,`AOF`是一种易于理解和解析的格式,依次包含所有操作的日志。
#### AOF 机制缺点
* 对于相同的数据集,`AOF`文件通常比等效的`RDB`文件大。
* 根据`fsync`的具体策略,`AOF`机制可能比`RDB`机制慢。但是一般情况下,`fsync`设置为每秒的性能仍然很高,禁用`fsync`后,即使在高负载下,它的速度也能和`RDB`一样快。
* 因为`AOF`文件是追加形式,可能会遇到`BRPOP`、`LPUSH`等阻塞命令的错误,从而导致生成的`AOF`在重新加载时不能复制完全相同的数据集,而`RDB`文件每次都是重新从头创建快照,这在一定程度上来说`RDB`文件更加健壮。
- Redis 为什么这么快
- 什么是 Redis
- Redis 的安装
- Redis 到底有多快
- Redis 是单线程还是多线程
- Redis 为什么选择使用单线程来执行请求
- 什么是 IO 多路复用机制
- Redis 中 I/O 多路复用的应用
- 一个简单的字符串,为什么 Redis 要设计的如此特别
- Redis 的 9 种数据类型
- 二进制安全字符串
- sds 空间分配策略
- sds 和 C 语言字符串区别
- sds 是如何被存储的
- type 属性
- encoding 属性
- 通过牺牲速度来节省内存,Redis 是觉得自己太快了吗
- 什么是压缩列表
- ziplist 的存储结构
- entry 存储结构
- ziplist 数据示例
- ziplist 连锁更新问题
- 为了加快速度,Redis 都做了哪些“变态”设计
- 列表对象
- linkedlist
- linkedlist 和 ziplist 的选择
- quicklist
- 列表对象常用操作命令
- Redis 中哈希分布不均匀该怎么办
- 哈希对象
- hashtable
- ziplist
- ziplist 和 hashtable 的编码转换
- 哈希对象常用命令
- 同一份数据,Redis 为什么要存”两次”
- 五种基本类型之集合对象
- intset 编码
- 集合对象常用命令
- 五种基本类型之有序集合对象
- skiplist 编码
- ziplist 编码
- ziplist 和 skiplist 编码转换
- 有序集合对象常用命令
- 要想用活 Redis,Lua 脚本是绕不过去的坎
- 发布与订阅
- 基于频道的实现
- 基于模式的实现
- Lua 脚本
- Lua 脚本的调用
- Lua 脚本中执行 Redis 命令
- Lua 脚本摘要
- Lua 脚本文件
- 脚本异常
- 作为一款内存数据库,为什么断电后 Redis 数据不会丢失
- Redis 持久化机制
- RDB 持久化机制
- AOF 持久化机制
- 内存耗尽后 Redis 会发生什么
- 内存回收
- 过期策略
- 8 种淘汰策略
- LRU 算法
- LFU 算法
- 不能回滚的 Redis 事务还能用吗
- Redis 有事务吗
- Redis 事务实现原理
- Redis 事务 ACID 特性
- watch 命令
- watch 命令的作用
- watch 原理分析
- Redis 为什么不直接用 master-slave 集群
- Redis 集群方案
- 主从复制
- 配置一主两从 master-slave 集群
- 主从复制原理分析
- 主从服务的不足之处
- Sentinel(哨兵)机制为什么从神坛滑落
- 哨兵 Sentinel 机制
- Sentinel 原理分析
- 配置 Sentinel 集群
- Sentinel 机制实战
- Sentinel 机制的不足之处
- Redis Cluster 集群凭什么成为了最终的胜利者
- Redis 分布式集群方案
- 客户端实现分片
- 中间代理服务实现分片
- Redis Cluster 方案
- 手动配置一个 Redis Cluster 集群
- Redis Cluster 集群常用命令
- 客户端如何使用 Redis Cluster 集群
- Redis Cluster 的不足
- 如何从 10 亿数据中快速判断是否存在某一个元素
- 缓存雪崩
- 缓存击穿
- 缓存穿透
- 布隆过滤器(Bloom Filter)
- 布隆过滤器的 2 大特点
- 布隆过滤器的实现(Guava)
- 布隆过滤器的如何删除