
`Redis Cluster`是`Redis 3.0`版本正式推出的,实现了高可用的分布式集群部署。
一个`Cluster`集群由多个节点组成,`Redis`当中通过配置文件`cluster-enabled`是否为`yes`来决定当前`Redis`服务是否开启集群模式,只有开启了集群模式,才可以使用集群相关的命令。与之相反的,如果没有开启集群的`Redis`我们称之为单机`Redis`。
#### 数据分片
水平集群的最关键一个问题就是数据应该如何分配,主流的有**哈希后取模**和**一致性哈希**两种数据分片方式。
##### 哈希后取模
哈希后再取模这种方式比较简单,就是将`key`值进行哈希运算之后再来除以节点数,即:`hash(key)%N`,然后根据余数来决定落在哪个节点。这种方式数据分布会比较均匀,但是这种方式同时也是一种静态的数据分片方式,一旦节点数发生变化,需要重新计算然后将数据进行重新分布。
##### 一致性哈希
一致性哈希的原理就是把所有的哈希值组织成一个虚拟的哈希圆环,其中起点`0`和终点(2 的 32 次方 - 1)位置重叠,如下图所示:
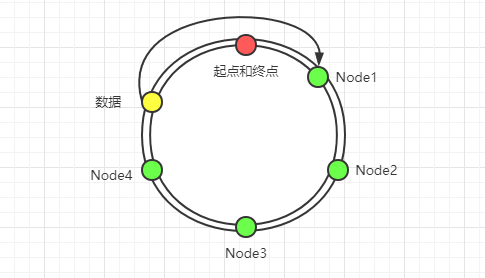
上图中绿色表示当前存在的节点,黄色表示数据落点处,如果数据没有恰好落在节点上,则会落到顺时针找到第一个节点,如上图中黄色的数据最终会落到`Node1`节点上。
这种方式的好处就是如果新增或者删除了节点,那么最多也只会影响相关的`1`个节点的数据,而不需要将所有的数据全部进行重新分片。
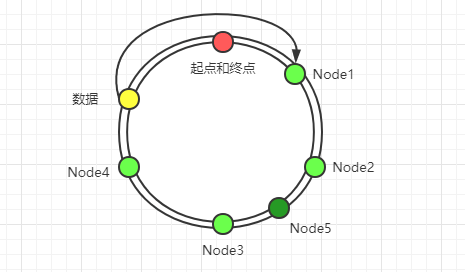
下图就是新增了一个`Node5`节点,那么其影响的就是`Node2`到`Node5`之间的这部分数据,对其它节点数据没有任何影响。也就是说这部分数据需要由原来落在`Node3`节点改到`Node5`节点。
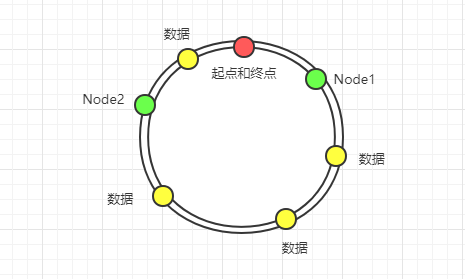
一致性哈希有一个问题就是当节点数比较少的情况下会导致数据分布不均匀。如下图所示(这里面只有`2`个节点,但是有`3`条数据落在了`Node2`而`Node1`只有`1`条数据,分布不均匀):
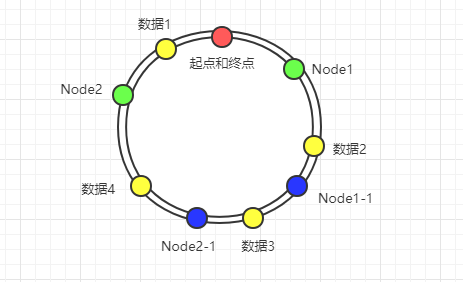
为了解决这种可能存在的分布不均匀问题,一致性哈希又引入了虚拟节点。当节点过少的时候,在哈西环上创建一些虚拟节点,然后按照范围指派给实际节点。
如下图,蓝色的就是虚拟节点,其中`Node1-1`的数据会分到`Node1`上,而`Node2-1`会分到`Node2`上,这样就可以使得数据较为平均(数据 1 和数据 2 最终落到节点 1,而数据 3 和数据 4 最终会落到节点 2):
#### 槽(slot)
`Redis`当中的数据分布并没有采用以上两种数据分片方式,而是另外引入了一个槽(slot)的概念。
`Redis`将整个数据库划分为`16384`个槽(slot),然后根据当前数据库的节点数来划分,每个节点负责一部分槽。如下图所示(上面的`1`表示当前槽有数据,`0`表示没有数据):
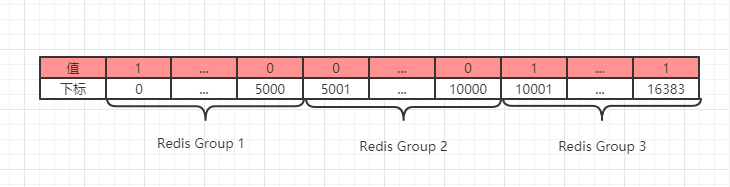
槽数组也是一个位图数组(bit array),每个对象分配到哪个槽是根据`CRC16`算法得到的,需要注意的是:**一个`key`落在哪一个槽是不会改变的,但是每个`Redis Group`(Redis 主从服务)负责的槽可能会发生变化**。
##### 如何让相关业务数据强制落在同一个槽
有时候我们同一个业务需要缓存一些数据,假如这些数据落在不同的槽归属于不同的服务器负责,那么在有些时候是会带来不便的,比如`multi`开启事务之后涉及到的`key`就不能跨节点,`Lua`脚本中同一个脚本涉及到的`key`也不能跨节点。所以我们应该如何让相关业务数据强制落在同一个槽呢?
`Redis`提供了一种`{}`机制,当我们的`key`里面带有`{}`的时候,那么`Redis`只会通过计算`{}`里面的字符来进行哈希,所以我们可以通过这种方式来强制同一种业务数据落在同一个槽。
我们可以将所有用户相关信息的`key`都带上`{user_info}`前缀,当然`get`的时候也需要带上`{}`这个完整的`key`,带上`{}`只是影响`slot`的计算,其它并不影响。
#### 客户端的重定向
`Redis`集群中服务器的数据分布客户端是不可知的,所以假如在一个客户端获取`key`,然后这个`key`不存在当前服务器,那么服务器会根据后台自己存储的信息判断出当前`key`所在槽归属于哪台服务器负责,会返回一个`MOVED`指令,并且带上服务器的`ip`和端口来告诉客户端当前`key`所在的服务器,客户端接收到`MOVED`指令之后进行重定向,然后去指定服务器查询`key`值的`value`。
这种方式客户端获取一个`key`可能会需要连接`2`次服务器。`Jedis`等客户端会在本地维护一份`slot`和`node`的映射关系,所以大部分时候不需要重定向,这种客户端也称之为`smart jedis`。但是这种特性并不是所有的客户端都支持。
#### 重新分片
`Redis`集群中,可以将已经指派给某个节点的任意数量的槽重新指派给另一个节点,且重新指派的槽所属的键值对也会被移动到新的目标节点,利用这个特性就可以实现新增节点或者删除节点。
重新分片的操作是可以在线进行的,也就是说重新分片的过程中,集群不需要下线,并且参与重新分片的节点也可以继续处理命令请求。
##### ASK 指令
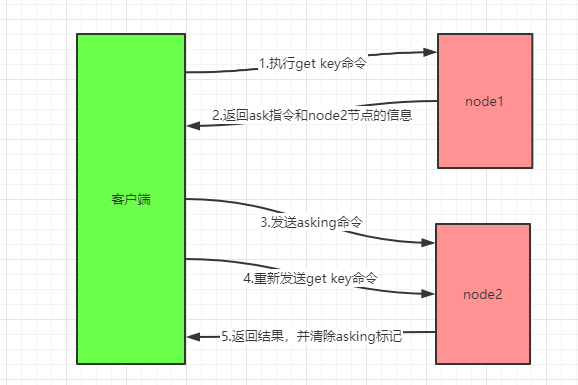
在重新分片的过程中会涉及到键值对的迁移,那么可能会出现这样一种情况:被迁移槽的一部分键值对保存在目标节点里面,还有一部分键值对仍然在原节点还没来得及迁移。
而假如这时候客户端来访问原节点时发现本来应该在这个节点的键值对已经被迁移到目标节点了,那么这时候就会返回一个`ASK`指令来引导客户端到目标节点去访问,这时候客户端并不能直接去访问目标节点,因为目标节点在所有键值对被迁移完成前是无法直接通过正常访问得到的。
目标节点在接收其它节点指派过来的槽所对应键值对时,会通过一个临时数组属性`importing_slots_from[16384]`来存储,所以客户端在接收到返回的`ASK`错误之后,客户端会先向目标节点发送一个`ASKING`命令,之后再发送原本想要执行的命令,这样目标节点就知道当前客户端访问的`key`是正在迁移过来的,知道去哪里取这个数据。
需要注意的是,`ASKING`命令的作用是客户端会打上一个标记,而这个标记是临时性的,当服务器执行过一个带有`ASKING`标记的命令之后就会将该标记清除。
下图就是一个重新分片的执行流程图:
##### ASK 指令和 MOVED 指令
* `ASK`指令可以认为是一种过渡时期的特殊指令,只有在发生槽迁移的过程中,发现原本属于`node1`管理的槽被指派给了`node2`,而数据又还没有迁移完成的情况下。因为这是一种特殊场景,所以客户端收到`ASK`指令之后不能直接连到目标节点执行命令(这时候直接连过去目标节点会返回`MOVED`命令指向`node1`),客户端收到`ASK`指令之后需要先向`node2`节点发送一个`ASKING`命令给自己打上标记才能真正发送客户端想要执行的命令。
* `MOVED`指令是在正常情况或者说槽已经完成重新分片的情况下返回的错误,这种情况服务器发现当前`key`所在槽不归自己管,那么就会直接返回`MOVED`指令并同时返回负责管理该槽的服务器信息,客户端收到`MOVED`指令及其携带的目标服务器地址之后就会再次连接目标节点执行命令。
#### Redis Group
`Redis`集群中的节点并不是只有一台服务器,而是一个由`master-slave`组成的集群,称之为`Redis Group`,那么既然是主从就会涉及到主从的数据复制,复制的原理和我们前面实验十一讲述的一致,但是故障检测以及故障转移和前面实验十二讲述的`Sentinel`模式工作原理有点区别。
##### 故障检测
集群中的各个节点都会定期向集群中的其它节点发送`PING`消息来检测对方是否在线,如果接收`PING`消息的节点没有在规定时间内返回`PONG`,那么发送`PING`消息的节点就会将其标记为疑似下线(probable fail,PFAIL)。
`PFAIL`类似于`Sentinel`机制下的主观下线,不同的是:集群中并不是发现`PFAIL`之后才会去询问其它节点,而是定期通过消息的方式来交换状态。
在`Redis`集群中,各个节点会通过互相发送消息(`PING`指令)的方式来交换集群中各个节点的状态信息,一旦某一个主节点`A`发现半数以上的主节点都将某一个主节点`B`标记为`PFAIL`,这时候主节点`A`就会将主节点`B`标记为已下线(`FAIL`),**然后主节点`A`会向集群中发一条主节点`B`已下线的消息的广播,所有收到这条广播消息的节点会立即将主节点`B`标记为已下线**。
**注意:如果广播之后,发现这个`master`节点所在的`Redis Group`中,所有的`slave`节点也挂了,那么这时候就会将集群标记为下线状态,整个集群将会不可用**。
##### 故障转移
当一个从节点发现自己的主节点已下线时,从节点将会开始进行故障转移,执行故障转移的从节点需要经过选举,如何选举在后面讲,故障转移的步骤主要分为以下三步:
1. 被选中的从节点会执行`replicaof no one`命令,使得自己成为新的主节点。
2. 新的主节点会将已下线的主节点负责的槽全部指派给自己。
3. 新的主节点会向集群发一条`PONG`消息的广播,收到这条消息的其它节点就会知道这个节点已经成为了新的`master`节点,并且接管了旧`master`节点的槽。
##### 选举新的 master 节点
一个从节点发现主节点下线后,会发起选举,选举步骤如下:
1. 该从节点会将集群的配置纪元自增`1`(和`Sentinel`机制一样,配置纪元默认值也是`0`)。
2. 该从节点会向集群发一条`CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST`的消息广播。
3. 其它节点收到广播后,`master`节点会判断合法性,如果一个主节点具有投票权(正在负责处理槽),那么就会返回一个`CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK`消息给它投`1`票(一个配置纪元内,一个`master`节点最多只能投票`1`次)。
4. 如果同时有多个从节点发起投票,那么每个从节点都会统计自己所得票数,然后进行统计,只要得到了大于参与投票的主节点数的一半的从节点,就会成为新的`master`节点。
5. 如果一个配置纪元内没有一个从节点达到要求,那么集群会把配置纪元再次自增,并再次进行选举,直到选出新的`master`。
#### 为什么槽定义为 16384 个
前面我们提到`Redis`集群中,判断一个`key`值落在哪个槽上是通过`CRC16`算法来计算的,`CRC16`算法产生的`hash`值有`16bit`大小,也就是可以产生 2 的 16 次方(即:`65536`)个值,但是`Redis`中定义的槽却只有`16384`个,这是为什么呢?
`Redis`中每秒都在发送`PING`消息,发送`PING`消息的节点会带上自己负责处理的槽信息,如果创建`65536`个槽(0-65535),那么就需要`65536`大小的位图(Bitmap)来存储,也就是需要:`65535/8/1024=8k`的位图数组空间,这对于频繁发送的心跳包来说太大了,而如果使用`16384`那么只需要`16384/8/1024=2kb`的位图数组空间,这是原因之一。
另一个原因是`Redis`集群中的节点数官方建议不要超过`1000`个,那么对于最大的`1000`个节点来说,`16384`个槽是比较合适的,因为`16384/1000=16`,也就是极端情况下每个节点负责`16`个`slot`,这是比较合适的,槽如果太小了(即`slot/N`不宜过大)会影响到位图的压缩。
下面截图就是`Redis`作者的回复(原文地址请[点击这里](https://github.com/redis/redis/issues/2576)):

- Redis 为什么这么快
- 什么是 Redis
- Redis 的安装
- Redis 到底有多快
- Redis 是单线程还是多线程
- Redis 为什么选择使用单线程来执行请求
- 什么是 IO 多路复用机制
- Redis 中 I/O 多路复用的应用
- 一个简单的字符串,为什么 Redis 要设计的如此特别
- Redis 的 9 种数据类型
- 二进制安全字符串
- sds 空间分配策略
- sds 和 C 语言字符串区别
- sds 是如何被存储的
- type 属性
- encoding 属性
- 通过牺牲速度来节省内存,Redis 是觉得自己太快了吗
- 什么是压缩列表
- ziplist 的存储结构
- entry 存储结构
- ziplist 数据示例
- ziplist 连锁更新问题
- 为了加快速度,Redis 都做了哪些“变态”设计
- 列表对象
- linkedlist
- linkedlist 和 ziplist 的选择
- quicklist
- 列表对象常用操作命令
- Redis 中哈希分布不均匀该怎么办
- 哈希对象
- hashtable
- ziplist
- ziplist 和 hashtable 的编码转换
- 哈希对象常用命令
- 同一份数据,Redis 为什么要存”两次”
- 五种基本类型之集合对象
- intset 编码
- 集合对象常用命令
- 五种基本类型之有序集合对象
- skiplist 编码
- ziplist 编码
- ziplist 和 skiplist 编码转换
- 有序集合对象常用命令
- 要想用活 Redis,Lua 脚本是绕不过去的坎
- 发布与订阅
- 基于频道的实现
- 基于模式的实现
- Lua 脚本
- Lua 脚本的调用
- Lua 脚本中执行 Redis 命令
- Lua 脚本摘要
- Lua 脚本文件
- 脚本异常
- 作为一款内存数据库,为什么断电后 Redis 数据不会丢失
- Redis 持久化机制
- RDB 持久化机制
- AOF 持久化机制
- 内存耗尽后 Redis 会发生什么
- 内存回收
- 过期策略
- 8 种淘汰策略
- LRU 算法
- LFU 算法
- 不能回滚的 Redis 事务还能用吗
- Redis 有事务吗
- Redis 事务实现原理
- Redis 事务 ACID 特性
- watch 命令
- watch 命令的作用
- watch 原理分析
- Redis 为什么不直接用 master-slave 集群
- Redis 集群方案
- 主从复制
- 配置一主两从 master-slave 集群
- 主从复制原理分析
- 主从服务的不足之处
- Sentinel(哨兵)机制为什么从神坛滑落
- 哨兵 Sentinel 机制
- Sentinel 原理分析
- 配置 Sentinel 集群
- Sentinel 机制实战
- Sentinel 机制的不足之处
- Redis Cluster 集群凭什么成为了最终的胜利者
- Redis 分布式集群方案
- 客户端实现分片
- 中间代理服务实现分片
- Redis Cluster 方案
- 手动配置一个 Redis Cluster 集群
- Redis Cluster 集群常用命令
- 客户端如何使用 Redis Cluster 集群
- Redis Cluster 的不足
- 如何从 10 亿数据中快速判断是否存在某一个元素
- 缓存雪崩
- 缓存击穿
- 缓存穿透
- 布隆过滤器(Bloom Filter)
- 布隆过滤器的 2 大特点
- 布隆过滤器的实现(Guava)
- 布隆过滤器的如何删除