
Sentinel**熔断降级**会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高),对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联错误。当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断(默认行为是抛出`DegradeException`)。
一共有三种熔断降级策略:
* RT平均响应时长
* 异常比例
* 异常数量
先为大家介绍第一种:RT平均响应时长降级策略。
## 一、RT降级策略

以下的两个条件同时满足才能触发RT服务降级。
* 一秒钟内通过5个以上的请求,全部超时
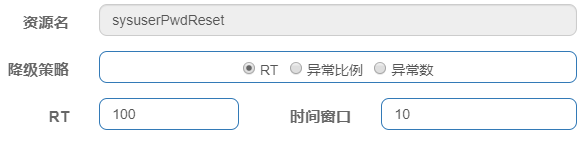
* 超时是指超过RT平均响应时长的配置值(上图红色框配置)
触发RT服务降级规则之后,在时间窗口期内(上图绿色框配置)对资源的访问将被降级,即:断路器被打开。时间窗口期之后关闭断路器。
> 需要注意的是:
>
> 1. RT平均响应时长最大可配值为4900毫秒。当配置超过4900的时候,默认等于4900。
> 2. 官方之所以设置RT最大值为4900,是因为当一次请求超过5秒就到了用户能忍受的极限。
> 3. 如果确实希望修改RT可配最大值,使用`-Dcsp.sentinel.statistic.max.rt=xxx`进行配置
#### 问题:为什么要1秒超时5次才降级?
答:如果一个服务的请求量比较小,几秒钟才有一次请求,不巧这1次请求因为瞬时网络原因失败了,进而导致服务降级,这种情况是我们不愿意看到的。服务降级仍然是主要指针对高并发情况下,导致的服务资源紧张的情况下生效。
* 不能因为有一例新冠患者,就进行封城!同样道理,不能因为个别情况,就进行服务降级!
* minRequestAmount=5秒钟,是在DeGradeRule中的配置`RuleConstant.DEGRADE_DEFAULT_MIN_REQUEST_AMOUNT`。

## 二、RT熔断降级测试
为了更容易触发降级,我们将平均响应时长设置为0.1秒(我们的方法执行时间肯定大于0.1秒)。降级之后的时间窗口是10秒。
参考Hystrix章节的《Jemeter模拟触发服务熔断》创建Jemeter接口测试用例。为了更明显的触发降级规则:配置1秒钟发送10个请求“/sysuser/pwd/reset”。

* 下图为**服务熔断降级之前**的响应结果。需要注意的是:虽然超过了0.1秒平均响应时长,但是可以正常响应结果。
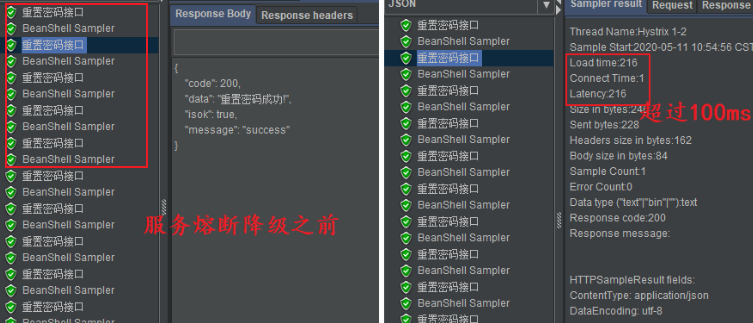
* 下图为**服务熔断降级之后**的响应结果,已经超过5次(一秒内发送的),所有请求处理均超过100ms。sentinel对于异常请求的临界状态判断并未执行的十分严格,有的时候是在第6次请求之后才进入服务降级。

哎,大家看“尊敬的客户您好,系统服务繁忙,请稍后再试!”这个响应结果是不是有点眼熟?没错,它就是我们上一节BlockHandler的处理方法。sentinel服务降级之后,有2种处理方法:
* fallback方法(defaultFallback方法)处理DegradeException,即:处理服务熔断降级。fallback服务降级处理方法我们后面的章节讲!
* 当服务降级没有定义fallback方法的时候,就会去执行BlockHandler方法。二者都定义了的话,也是执行BlockHandler方法。**BlockHandler优先**
## 三、sentinel流控规则与降级规则的区别
初学者咋一看sentinel流控规则与降级规则,好像没什么区别啊?为什么不统一叫做规则配置?还要去分开呢?为了方便大家的理解,我们来比较一下。
| 比较点 | 流控规则 | 降级规则 |
| --- | --- | --- |
| 内容比较 | QPS、线程数、关联、链路限流、冷启动及匀速排队 | 平均响应时长、异常比例、异常数量 |
| 解决问题的方向 | 外部流量压力导致问题 | 内部编码及处理能力导致的问题 |
| Exception | FlowException(BlockException) | DegradeException(BlockException) |
| 降级处理方法 | BlockHandler | fallback或BlockHandler |
- 文档简介
- 模块与代码分支说明
- dongbb-cloud项目核心架构
- 微服务架构进化论
- SpringBoot与Cloud选型兼容
- Spring Cloud组件的选型
- 单体应用拆分微服务
- 单体应用与微服务对比
- 微服务设计拆分原则
- 新建父工程及子模块框架
- 通用微服务初始化模块构建
- 持久层模块单独拆分
- 拆分rbac权限管理微服务
- Hello-microservice
- 构建eureka服务注册中心
- 向服务注册中心注册服务
- 第一个微服务调用
- 远程服务调用
- HttpClient远程服务调用
- RestTemplate远程服务调用
- RestTemplate多实例负载均衡
- Ribbon调用流程源码解析
- Ribbon负载均衡策略源码解析
- Ribbon重试机制与饥饿加载
- Ribbon自定义负载均衡策略
- Feign与OpenFeign
- Feign设计原理源码解析
- Feign请求压缩与超时等配置
- 服务注册与发现
- 白话服务注册与发现
- DiscoveryClient服务发现
- Eureka集群环境构建(linux)
- Eureka集群多网卡环境ip设置
- Eureka集群服务注册与安全认证
- Eureka自我保护与健康检查
- 主流服务注册中心对比(含nacos)
- zookeeper概念及功能简介
- zookeeper-linux集群安装
- zookeeper服务注册与发现
- consul概念及功能介绍
- consul-linux集群安装
- consul服务注册与发现
- 通用-auatator导致401问题
- 分布式配置中心-apollo
- 服务配置中心概念及使用场景
- apollo概念功能简介
- apollo架构详解
- apollo分布式部署之Portal
- apollo分布式部署之环境区分
- apollo项目权限管理实战
- apollo-java客户端基础
- apollo与SpringCloud服务集成
- apollo实例配置热更新
- apollo命名空间与集群
- apollo灰度发布(日志热更新为例)
- SpringCloudConfig配置中心
- config-git配置文件仓库
- config配置中心搭建与测试
- config客户端基础
- config配置安全认证
- config客户端配置刷新
- config配置中心高可用
- BUS消息总线
- bus消息总线简介
- docker安装rabbitMQ
- 基于rabbitMQ的消息总线
- bus实现批量配置刷新
- alibaba-nacos
- nacos介绍与单机部署
- nacos集群部署方式(linux)
- nacos服务注册与发现
- nacos服务注册中心详解
- nacos客户端配置加载
- nacos客户端配置刷新
- nacos服务配置隔离与共享
- nacos配置Beta发布
- 服务熔断降级hystrix
- 服务降级&熔断&限流
- Hystrix集成并实现服务熔断
- Jemter模拟触发服务熔断
- Hystrix服务降级fallback
- Hystrix结合Feign服务降级
- 远程服务调用异常传递的问题
- Hystrix-Feign异常拦截与处理
- Hystrix-DashBoard单服务监控
- Hystrix-dashboard集群监控
- 分布式系统流量卫兵sentinel
- sentinel简介与安装
- 客户端集成与实时监控
- 实战流控规则-QPS限流
- 实战流控规则-线程数限流
- 实战流控规则-关联限流
- 实战流控规则-链路限流
- 实战流控效果-WarmUp
- 实战流控效果-匀速排队
- BlockException处理
- 实战熔断降级-RT
- 实战熔断降级-异常数与比例
- DegradeException处理
- 注解与异常的归纳总结
- Feign降级及异常传递拦截
- 动态规则nacos集中存储
- 热点参数限流
- 系统自适应限流
- 微服务网关-GateWay
- 还有必要学习Zuul么?
- 简介与非阻塞异步IO模型
- GateWay概念与流程
- 新建一个GateWay项目
- 通用Predicate的使用
- 自定义PredicateFactory
- 编码方式构建静态路由
- Filter过滤器介绍与使用
- 自定义过滤器Filter
- 网关请求转发负载均衡
- 结合nacos实现动态路由配置
- 整合Sentinel实现资源限流
- 跨域访问配置
- 网关层面全局异常处理
- 微服务网关安全认证-JWT篇
- Gateway-JWT认证鉴权流程
- 登录认证JWT令牌颁发
- 全局过滤器实现JWT鉴权
- 微服务自身内部的权限管理