
## 一、zookeeper简介
zookeeper是一个分布式应用的协调服务。用于对分布式系统进行配置管理、节点管理、leader选举、分布式锁等。ZooKeeper最初是由“ Yahoo!”开发的。后来,Apache ZooKeeper成为Hadoop,HBase和其他分布式框架常用的服务配置管理的标准。
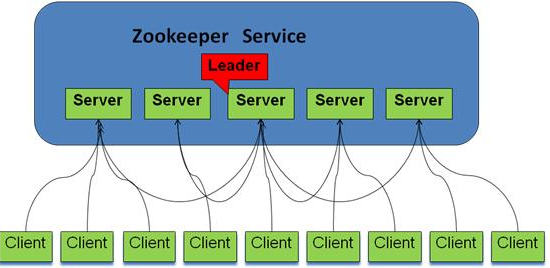
zookeeper 将集群内的节点进行了这样三种角色划分(**上图中的Client不属于zookeeper集群**):
* leader:负责进行投票选举的发起和决议,更新系统状态。
* follower:用于接收客户端请求并向客户端返回结果以及在选举过程中参与投票。
* observer):也可以接收客户端连接,将写请求转发给leader节点,但是不参与投票过程,只同步leader的状态。通常对查询操作做负载。
zookeeper集群是一个强调保障数据一致性的分布式系统(CP),客户端发起的每次查询操作,集群节点都能返回同样的结果。那么问题来了:对于客户端发起的修改、删除等能改变数据的操作呢?集群中那么多台机器,如果是你修改你的,我修改我的,没有统一管理,最后查询返回集群中哪台机器的数据呢?如果随意操作,就不能保证数据一致性了。于是在zookeeper集群中,leader的作用就体现出来了,
* 只有leader节点才有权利发起修改数据的操作,follower节点即使接收到了客户端发起的修改操作,也要将其转交给leader来处理
* leader接到数据修改的请求后,会向所有follower广播一条消息,让他们执行修改操作
* follower 执行完后,便会向 leader 回复执行完毕。当 leader 收到半数以上的 follower 的确认消息,便会判定该操作执行完毕。
* 完成同步数据的follower,可以对外提供下一次查询或修改数据的服务。
这样就保障了zookeeper内各个节点的数据一致性。所以zookeeper集群中leader是不可缺少的,但是 leader 节点是怎么产生的呢?其实就是由所有follower 节点选举产生的,且leader节点只能有一个。当前leader如果因为某些原因挂掉了,集群内剩余的节点会重新选举leader。
## 二、集群节点必须是奇数个
我们要搭建服务注册中心zookeeper集群,必须搭建奇数个节点,这是为什么呢?
### 容错率
首先从容错率来说明:(需要保证集群能够有半数进行投票)
* 2台服务器,至少2台正常运行才行(2的半数为1,半数以上最少为2),正常运行1台服务器都不允许挂掉,但是相对于 单节点服务器,2台服务器还有两个单点故障,所以直接排除了。
* 3台服务器,至少2台正常运行才行(3的半数为1.5,半数以上最少为2),正常运行可以允许1台服务器挂掉
* 4台服务器,至少3台正常运行才行(4的半数为2,半数以上最少为3),正常运行可以允许1台服务器挂掉
* 5台服务器,至少3台正常运行才行(5的半数为2.5,半数以上最少为3),正常运行可以允许2台服务器挂掉
### 防脑裂
脑裂集群的脑裂通常是发生在节点之间通信不可达的情况下,集群会分裂成不同的小集群,小集群各自选出自己的leader节点,导致原有的集群出现多个leader节点的情况,这就是脑裂。
* 3台服务器,投票选举半数为1.5,一台服务裂开,和另外两台服务器无法通行,这时候2台服务器的集群(2票大于半数1.5票),所以可以选举出leader,而 1 台服务器的集群无法选举。
* 4台服务器,投票选举半数为2,可以分成 1,3两个集群或者2,2两个集群,对于 1,3集群,3集群可以选举;对于2,2集群,则不能选择,造成没有leader节点。
* 5台服务器,投票选举半数为2.5,可以分成1,4两个集群,或者2,3两集群,这两个集群分别都只能选举一个集群,满足zookeeper集群搭建数目。
以上分析,我们从容错率以及防止脑裂两方面说明了3台服务器是搭建集群的最少数目,4台服务器发生脑裂时会造成没有leader节点的错误。
## 三、临时节点与持久节点
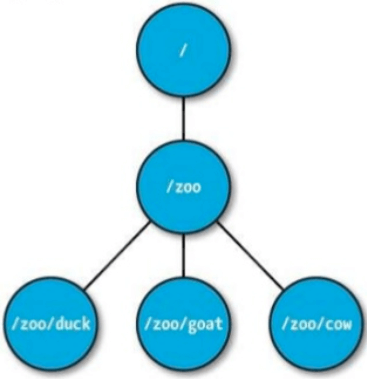
zookeeper中的数据是以树形结构组织的,类似于树形文件系统。树中的节点称为znode,znode按持久化类型分类可以分为:
**持久znode**
即使在创建该特定znode的客户端断开连接后,持久znode数据仍然存在。默认情况下,所有znode都是持久的。
**临时znode**
当客户端处于活跃状态时,该客户端创建的临时znode就是有效的。当客户端与ZooKeeper集合断开连接时,临时znode会自动删除。
> Spring Cloud 微服务向zookeeper注册的过程就是在zookeeper增加临时znode节点,znode节点中保存了服务的注册信息。也正是利用了临时客户端断开连接后删除znode的的特性,实现了服务的自动下线。
zookeeper除了上面的这些内容,还能做很多事情,如:分布式锁。还有很多应用、运维的知识可以学习。本文只为大家介绍与“服务注册中心”相关的理论基础知识。下一节我们就手动搭建一个zookeeper集群。
- 文档简介
- 模块与代码分支说明
- dongbb-cloud项目核心架构
- 微服务架构进化论
- SpringBoot与Cloud选型兼容
- Spring Cloud组件的选型
- 单体应用拆分微服务
- 单体应用与微服务对比
- 微服务设计拆分原则
- 新建父工程及子模块框架
- 通用微服务初始化模块构建
- 持久层模块单独拆分
- 拆分rbac权限管理微服务
- Hello-microservice
- 构建eureka服务注册中心
- 向服务注册中心注册服务
- 第一个微服务调用
- 远程服务调用
- HttpClient远程服务调用
- RestTemplate远程服务调用
- RestTemplate多实例负载均衡
- Ribbon调用流程源码解析
- Ribbon负载均衡策略源码解析
- Ribbon重试机制与饥饿加载
- Ribbon自定义负载均衡策略
- Feign与OpenFeign
- Feign设计原理源码解析
- Feign请求压缩与超时等配置
- 服务注册与发现
- 白话服务注册与发现
- DiscoveryClient服务发现
- Eureka集群环境构建(linux)
- Eureka集群多网卡环境ip设置
- Eureka集群服务注册与安全认证
- Eureka自我保护与健康检查
- 主流服务注册中心对比(含nacos)
- zookeeper概念及功能简介
- zookeeper-linux集群安装
- zookeeper服务注册与发现
- consul概念及功能介绍
- consul-linux集群安装
- consul服务注册与发现
- 通用-auatator导致401问题
- 分布式配置中心-apollo
- 服务配置中心概念及使用场景
- apollo概念功能简介
- apollo架构详解
- apollo分布式部署之Portal
- apollo分布式部署之环境区分
- apollo项目权限管理实战
- apollo-java客户端基础
- apollo与SpringCloud服务集成
- apollo实例配置热更新
- apollo命名空间与集群
- apollo灰度发布(日志热更新为例)
- SpringCloudConfig配置中心
- config-git配置文件仓库
- config配置中心搭建与测试
- config客户端基础
- config配置安全认证
- config客户端配置刷新
- config配置中心高可用
- BUS消息总线
- bus消息总线简介
- docker安装rabbitMQ
- 基于rabbitMQ的消息总线
- bus实现批量配置刷新
- alibaba-nacos
- nacos介绍与单机部署
- nacos集群部署方式(linux)
- nacos服务注册与发现
- nacos服务注册中心详解
- nacos客户端配置加载
- nacos客户端配置刷新
- nacos服务配置隔离与共享
- nacos配置Beta发布
- 服务熔断降级hystrix
- 服务降级&熔断&限流
- Hystrix集成并实现服务熔断
- Jemter模拟触发服务熔断
- Hystrix服务降级fallback
- Hystrix结合Feign服务降级
- 远程服务调用异常传递的问题
- Hystrix-Feign异常拦截与处理
- Hystrix-DashBoard单服务监控
- Hystrix-dashboard集群监控
- 分布式系统流量卫兵sentinel
- sentinel简介与安装
- 客户端集成与实时监控
- 实战流控规则-QPS限流
- 实战流控规则-线程数限流
- 实战流控规则-关联限流
- 实战流控规则-链路限流
- 实战流控效果-WarmUp
- 实战流控效果-匀速排队
- BlockException处理
- 实战熔断降级-RT
- 实战熔断降级-异常数与比例
- DegradeException处理
- 注解与异常的归纳总结
- Feign降级及异常传递拦截
- 动态规则nacos集中存储
- 热点参数限流
- 系统自适应限流
- 微服务网关-GateWay
- 还有必要学习Zuul么?
- 简介与非阻塞异步IO模型
- GateWay概念与流程
- 新建一个GateWay项目
- 通用Predicate的使用
- 自定义PredicateFactory
- 编码方式构建静态路由
- Filter过滤器介绍与使用
- 自定义过滤器Filter
- 网关请求转发负载均衡
- 结合nacos实现动态路由配置
- 整合Sentinel实现资源限流
- 跨域访问配置
- 网关层面全局异常处理
- 微服务网关安全认证-JWT篇
- Gateway-JWT认证鉴权流程
- 登录认证JWT令牌颁发
- 全局过滤器实现JWT鉴权
- 微服务自身内部的权限管理