
[TOC]
主机的CPU有很多比如说有N个,Tn时刻主机CPU空闲率的计算方法应该为
```
(Tn时刻所有CPU的空闲时间和 - Tn-1所有CPU的空闲时间和) / (时间间隔 * N)
```
分解开来,其实就是
```
[(Tn时刻CPU{0}的空闲时间 - Tn-1所有CPU{0}的空闲时间) / 时间间隔 + ... + (Tn时刻所有CPU{N-1}的空闲时间 - Tn-1所有CPU{N-1}的空闲时间) / 时间间隔] / N
```
那么就是
```
[irate(node_cpu_seconds_total{cpu="0",mode="idle"}[1m]) + ... + irate(node_cpu_seconds_total{cpu="N-1",mode="idle"}[1m])] / N
```
即
```
avg(irate(node_cpu_seconds_total{mode="idle"}[1m]))
```
上面的表达式只适于用只有一台主机时,如果有多台主机时,某台主机的CPU空闲率为
```
avg(irate(node_cpu_seconds_total{instance="ip:port",mode="idle"}[1m]))
```
如下是分别统计出来的两台主机的cpu空闲率的截图
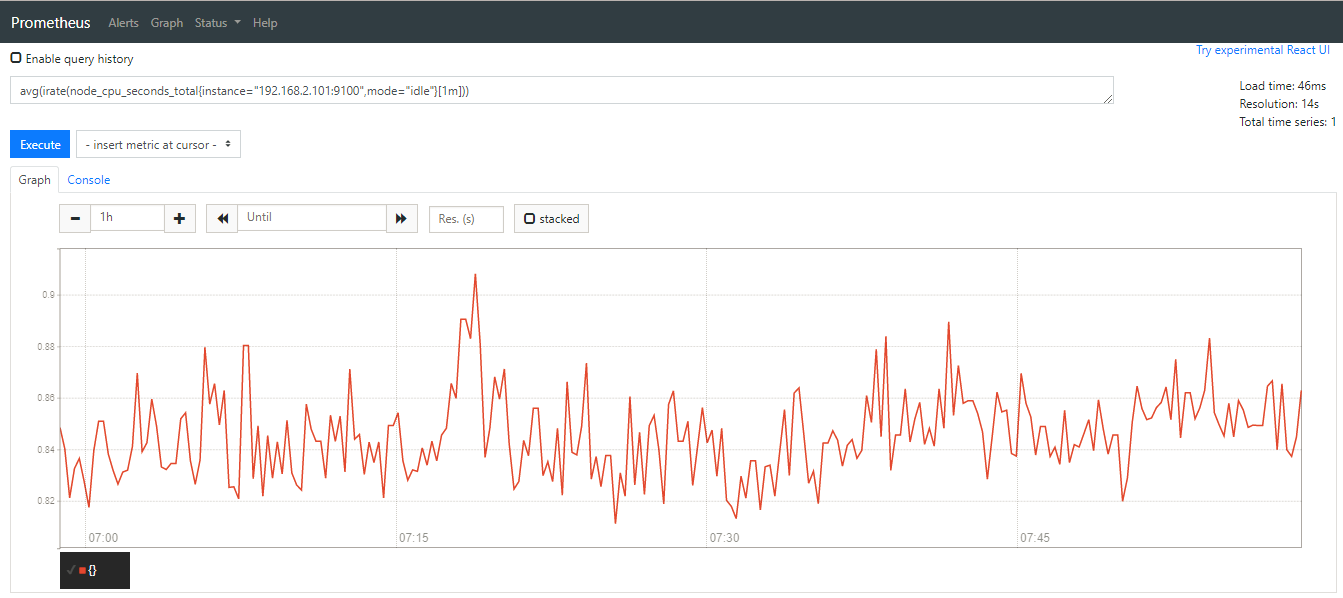
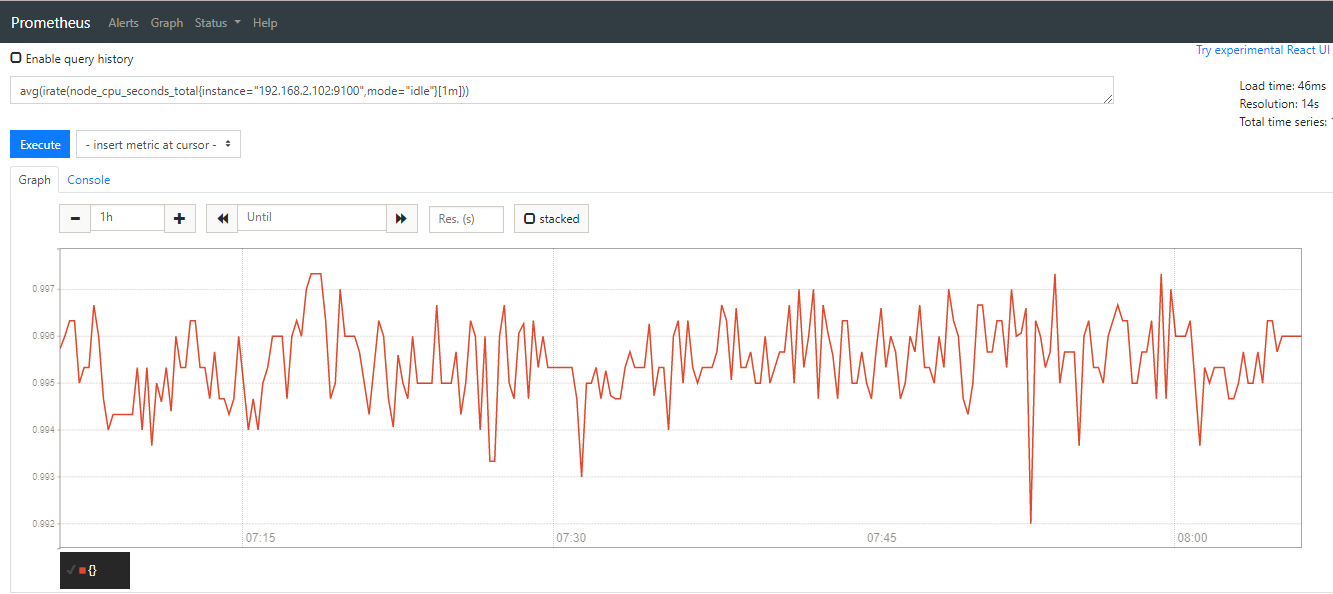
可以用下面的表达式来一次性统计所有主机的cpu空闲率
```
avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by(instance)
```
如下是统计出来的两台主机的cpu空闲率截图,可以看到有两条曲线,分别表示两台个instance
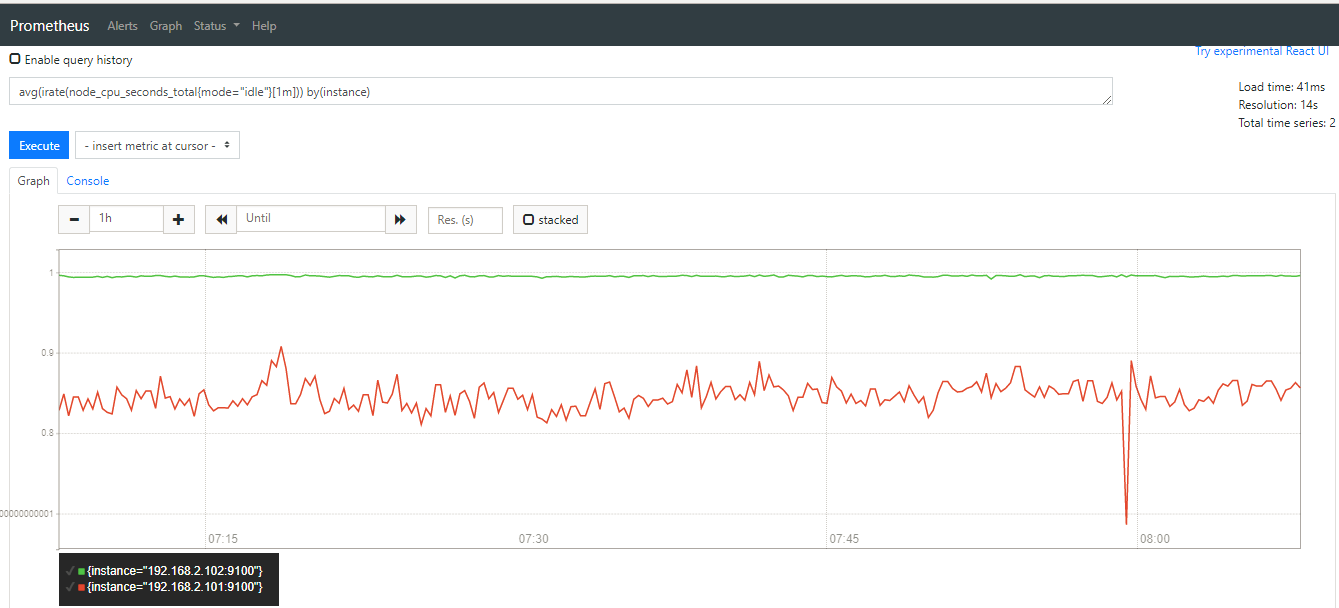
那么一次性统计每台主机的cpu使用率的表达式为
```
1 - avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by(instance)
```
- (一)快速开始
- 安装Prometheus
- 使用NodeExporter采集数据
- AlertManager进行告警
- Grafana数据可视化
- (二)探索PromQL
- 理解时间序列
- Metrics类型
- 初识PromQL
- PromQL操作符
- PromQL内置函数
- rate和irate
- 常见指标的PromQL
- 主机CPU使用率
- 主机内存使用率
- 主机磁盘使用率
- 主机磁盘IO
- 主机网络IO
- API的响应时间
- (三)Promtheus告警处理
- 自定义告警规则
- 示例-对主机进行监控告警
- 部署AlertManager
- 告警的路由与分组
- 使用Receiver接收告警信息
- 集成邮件系统
- 屏蔽告警通知
- 扩展阅读
- AlertManager的API
- Prometheus发送告警机制
- 实践:接收Prometheus的告警
- 实践:AlertManager
- (四)监控Kubernetes集群
- 部署Prometheus
- Kubernetes下的服务发现
- 监控Kubernetes集群
- 监控Kubelet的运行状态
- 监控Pod的资源(cadvisor)
- 监控K8s主机的资源
- KubeStateMetrics
- K8S及ETCD常见监控指标
- ETCD监控指标
- Kube-apiserver监控指标
- (五)其他
- Prometheus的relabel-config
- Target的Endpoint
- Prometheus的其他配置
- (六)BlackboxExporter
- 安装
- BlackboxExporter的应用场景
- 在Promtheus中使用BlackboxExporter
- 参考