
欢迎关注我的公众号:

# Android提供的 LruCache 的分析
[TOC]
## 前言
在日常的开发当中,我们主要的工作就是把用户想要看的信息通过界面展示出来,难免就要和数据打交道,对于一些用户关心的数据,我们肯定是要每次都要从网络拿最新的数据展示。
但是对于一些图片数据,如果我们每次都从网络读取图片未免就有点浪费资源了,不仅会浪费用户的流量,也会影响我们 App 的性能,所以通常的做法就是对图片做缓存处理。
相信大家都听过图片的三级缓存,下面先讲下什么是三级缓存?
## 什么是三级缓存
三级缓存主要由三部分构成:
- 内存
- 硬盘
- 网络
我们知道,在内存中对数据处理的速度是最快的,硬盘次之,而网络上读取数据,显示的时候,也要加载到内存中然后进行展示。
所以,我们完全可以将部分用户关心的,最经常使用的图片保存在内存和硬盘中,当下次展示的时候快速的进行展示,并且不用浪费用户流量。
比如我们要加载一个图片,地址是 url,如果实现了三级缓存,那么我们在要显示图片的时候,进行以下步骤:
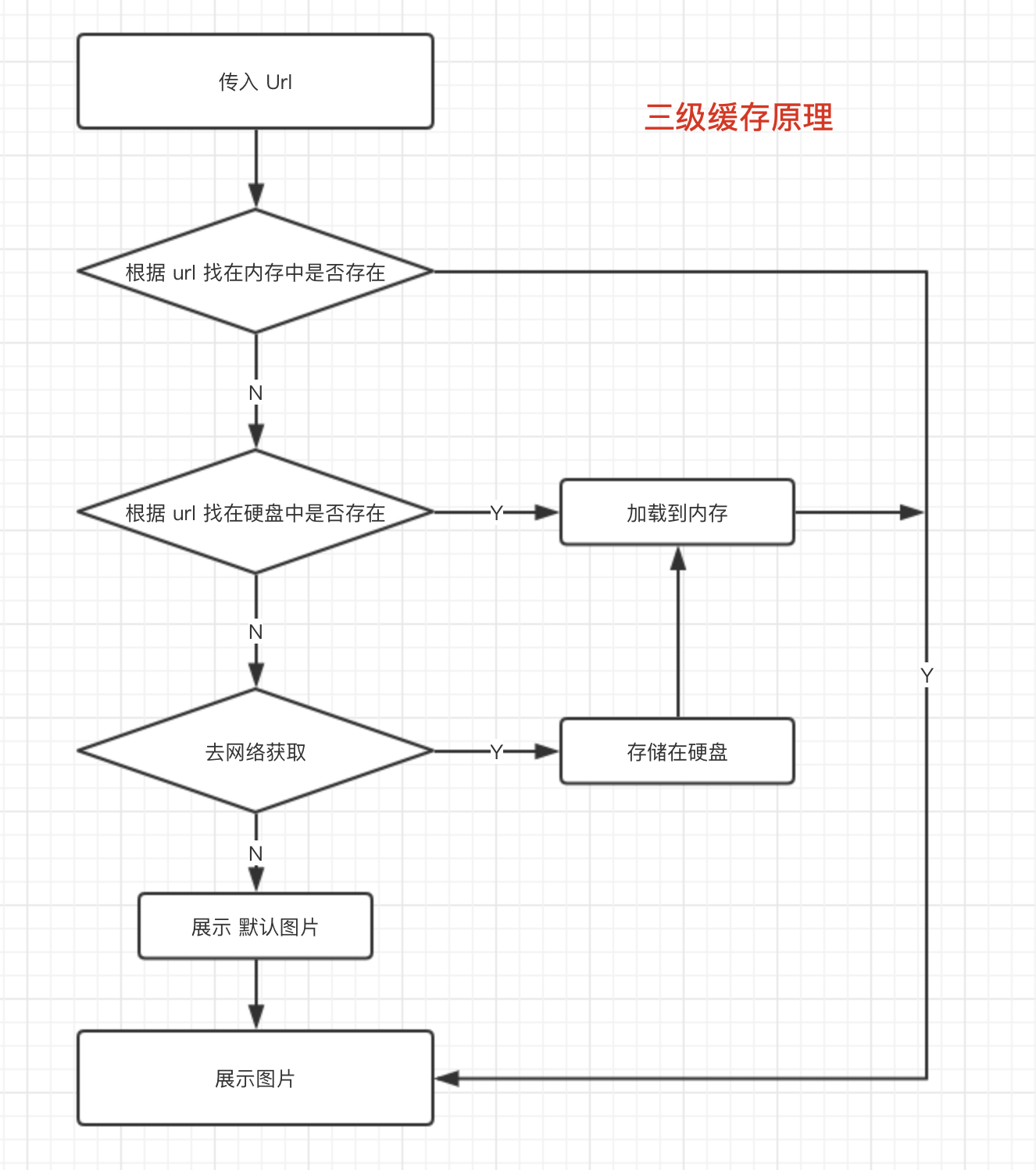
上图中就展示了一个完整的实现了三级缓存的图片加载的流程,仔细分析下流程图,相信你已经知道什么是三级缓存是什么了
## 缓存的核心 LRU 算法
我们知道,内存和硬盘空间是有限的,我们在实现内存缓存和硬盘缓存的时候,不可以无休止的往缓存中添加数据,必然是要设置和合适的空间去缓存数据,当我们设置的空间满的时候,我们需要移除一部分数据,然后添加新的数据进入缓存。
这就遇到了一个问题:空间满的时候,先移除哪些数据呢?
肯定是先移除用户最不经常使用的数据,把用户经常使用的数据留在缓存中,保证用户可以快速的访问到数据,这就使用到了 LRU 算法
**LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高,如果数据最近没被,那么未来被访问的几率就比较低,优先删除”。**
接下来我们看下 Lru 算法在 Android 中的应用 LruCache 是怎么实现的(DiskLruCache 原理类似,本文不在将)
## LruCache
内存缓存可以使用 Android 3.1 以后提供的一个缓存类:LruCache,这个类实现了 LRU 算法。
### 官方描述
> A cache that holds strong references to a limited number of values. Each time a value is accessed, it is moved to the head of a queue. When a value is added to a full cache, the value at the end of that queue is evicted and may become eligible for garbage collection.
> If your cached values hold resources that need to be explicitly released, override entryRemoved(boolean, K, V, V).
> If a cache miss should be computed on demand for the corresponding keys, override create(K). This simplifies the calling code, allowing it to assume a value will always be returned, even when there's a cache miss.
LruCache 是存储了有限数量的强引用的缓存,每次访问一个值的时候,会将其移动到队列的头部,当一个值添加到已经满的队列的时候,会将队列尾部的元素移除掉,让 GC 回收掉。
如果缓存的值明确的要知道已经释放,需要重写 entryRemoved(boolean, K, V, V) 方法,做一些自己的处理
如果缓存用没有找到一个对应的值,可以通过 create(K),简化了调用代码,允许即使是没有找到对应值的情况下能够返回一个值。
### 看下成员变量和构造方法
```java
public class LruCache<K, V> {
// LruCache 的核心 LinkedHashMap
private final LinkedHashMap<K, V> map;
// 当前缓存大小
private int size;
// 最大缓存大小
private int maxSize;
// 插入次数
private int putCount;
// 创建次数,只有重写 create(K) 方法的时候会改变
private int createCount;
// 移除数据次数,缓存满的时候,插入新数据的时候,移除旧数据的时候,会改变这个值.
private int evictionCount;
// 命中次数,也就是 get 查找到元素的次数
private int hitCount;
// 未命中次数,也就是 get 没查找到元素的次数
private int missCount;
/**
* @param maxSize 如果没有重写 sizeOf 方法,maxSize 就是缓存中元素的最大个数
* 如果重写了 sizeOf 方法,则 maxSize 就是所有缓存元素大小(也就是每个元素乘以自身大小的总和)
*/
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
// 创建了一个默认容量 默认负载因子 ,允许访问排序的 LinkedHashMap.
this.map = new LinkedHashMap<K, V>(0, 0.75f, true);
}
}
```
上面的最主要的就是设置的 maxSize 以及内部的定义的允许访问排序的 LinkedHashMap。
maxSize 在重写了 sizeOf 方法的情况下,代表的就是我们每个元素乘以自身大小之后累加的允许的最大值。
LinkedHashMap的对象 map 则是实现 LruCache 的核心,前面在 [LinkedHashMap 源码分析](https://blog.csdn.net/Sean_css/article/details/91906206) 中已经讲了,如果在创建 LinkedHashMap 的时候,指定了 accessOrder 为 true 的话,那么就会在访问 LinkedHashMap 的过程中,会对内部的元素重新排序,这里就是实现 LruCache 的关键部分。
虽然我们设置了 accessOrder 为 true 实现了访问时的元素排序,但是还远远不够,因为 LruCache 会在一定时候移除最久未访问的元素,那达到什么程度移除?怎么移除?
答案是在 LruCache 中去实现的,下面就按传统的方式来了解 LruCache 的增删改查的相关操作,通过一个完整的流程分析,基本能了解整个 LruCache 的实现。
### 常用方法分析
使用缓存,肯定要先把数据添加到缓存中,我们才能访问,在 LruCache 中添加缓存的操作是 put 方法:
#### put() 添加缓存
```java
public final V put(K key, V value) {
// 键值对不可为空
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
// 旧值
V previous;
// 同步代码块,使用 this 也就是说同时只能由一个线程操作这个对象
synchronized (this) {
putCount++;
// 先通过safeSizeOf方法计算当前传入的 value 的大小,累加的 size
size += safeSizeOf(key, value);
// 把键值对插入到 LinkedHashMap 中,如果有返回值,说明存在相同的 key,取出旧值给 previous
previous = map.put(key, value);
// 如果存在旧值,则从当前大小中删除旧值占用的大小.
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
// 如果 存在旧值,相当于把旧值移除了,这里调用 entryRemoved 方法.
// entryRemoved 默认是空实现,如果用户有需求,可以自己实现,完成一些资源的释放工作.
if (previous != null) {
entryRemoved(false, key, previous, value);
}
// 这个是最关键的方法,用来计算当前大小是否符合要求.
trimToSize(maxSize);
// 返回旧值
return previous;
}
```
在 put 方法里面我们看到了,使用 LruCache 缓存是不允许键值对为空的,并且在执行插入操作的时候,使用了 Synchronized 关键字对代码进行线程同步,保证了插入操作的线程安全。
然后计算了当前插入值的大小,累加到 size 上,执行完插入操作以后,如果之前存在相同的 key 值,则把之前元素的大小从 size 上面给移除掉。如果没有存在,就什么也不做。
如果用户重写了 entryRemoved 操作,也会回调 entryRemoved方法,让用户执行一些资源释放等工作。
最后调用了trimToSize(maxSize) 方法,这个方法是个核心方法,主要计算当前大小是否超过了设置的最大值,超过了则会将最近最少使用的元素移除。
#### trimToSize() 控制缓存的容量
在 LruCache 里面,控制缓存容量不超过我们设置的最大值的关键点就是这个 trimToSize() 方法:
```java
public void trimToSize(int maxSize) {
while (true) {
K key;
V value;
// 同样是线程同步的.
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
// 如果当前大小小于设定的最大值大小,直接跳出循环.
if (size <= maxSize || map.isEmpty()) {
break;
}
// 使用 map.entrySet() 代表从 LinkedHashMap 的头结点开始遍历,在
// 上篇文章里面看了源码,可以参考下面的链接
// 从头开始遍历,那只取一次,toEvict 就是头节点的元素
Map.Entry<K, V> toEvict = map.entrySet().iterator().next();
// 要删除元素的 key
key = toEvict.getKey();
// 要删除元素的 value
value = toEvict.getValue();
// 使用 LinkedHashMap 的 remove 方法删除指定元素
map.remove(key);
// 重新计算当前 size 的大小
size -= safeSizeOf(key, value);
// 移除次数+1
evictionCount++;
}
// 调用用户自定义的 entryRemoved() 如果用户定义了的话
entryRemoved(true, key, value, null);
}
}
```
首先开启了一个无限循环,在循环里面的同步代码块里面会判断当前的容量 size 是否超过最大容量 maxSize。
如果没超过,结束循环。
如果超过,就会遍历内部的 LinkedHashMap 对象 map,这里使用的是 map.entrySet(),在上一篇[LinkedHashMap 源码分析](https://mp.weixin.qq.com/s?__biz=MzI2MzQzNzU5Mg==&mid=2247483796&idx=1&sn=fd5a2bb2bac5b034b2e939d9956a1fe2&chksm=eabaade3ddcd24f5b16c86b54a4831118859d2680b1eb089d9a3007c98b091fcb6f25780f297&token=79300944&lang=zh_CN#rd) 里面我们对 LinkedHashMap 的遍历做了简单的介绍,map.entrySet() 最终是调用 LinkedHashIterator 里面的 nextNode 拿到节点,然后在 LinkedEntryIterator 里面从节点里面 通过 nextNode() 拿到 entry 的值。
上篇源码里面讲了,在 LinkedHashIterator 的构造方法里面是从头节点开始取值的,所以这里的调用的 next 方法拿的就是头节点。
所以在 trimToSize 方法里面主要做的事情就是:如果容量没超过最大值,返回,如果超过最大值,就依次移除头节点元素,一直到容量满足设定的最大值。
#### remove() 删除缓存
```java
public final V remove(K key) {
// 不允许 null 值
if (key == null) {
throw new NullPointerException("key == null");
}
// 删除的元素
V previous;
// 同步代码块保证线程安全
synchronized (this) {
// 删除元素,并把值赋给 previous
previous = map.remove(key);
//如果之前有 key 对应的值,将其减去
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
// 如果用户重写了entryRemoved 并且 之前有与 key 对应的值,执行entryRemoved。
if (previous != null) {
entryRemoved(false, key, previous, null);
}
return previous;
}
```
这里也很简单,住要是通过内部的 LinkedHashMap 移除元素,然后再把原来缓存中的对应的值删掉。
#### get() 获取缓存
```java
public final V get(K key) {
// 不允许 null key
if (key == null) {
throw new NullPointerException("key == null");
}
// value 的值
V mapValue;
// 同步代码块保证当前实例的线程安全
synchronized (this) {
// 通过 LinkedHashMap 的 get 方法去寻找
mapValue = map.get(key);
// 找到只,直接返回,命中值 +1
if (mapValue != null) {
hitCount++;
return mapValue;
}
// 没找到,未命中次数+1
missCount++;
}
// 这个地方意识,没有通过 get 方法找到,但是你想要有返回值,那么久可以重写 create 方法自己创建一个 返回值、。
V createdValue = create(key);
// 创建的值为 null ,直接返回 null
if (createdValue == null) {
return null;
}
synchronized (this) {
createCount++;
//将createdValue加入到map中,并且将原来键为key的对象保存到mapValue
mapValue = map.put(key, createdValue);
// 原来位置不为空,
if (mapValue != null) {
// There was a conflict so undo that last put
// 撤销上一步的操作,依旧把原来的值放到缓存。,替换掉新创建的值
map.put(key, mapValue);
} else {
// 原来key 对应的没值,计算当前缓存大小。
size += safeSizeOf(key, createdValue);
}
}
// 相当于一个替换操作,先用 createdValue 替换原来的值,然后这里移除掉 createdValue 。返回原来 key 对应的值。
if (mapValue != null) {
entryRemoved(false, key, createdValue, mapValue);
return mapValue;
} else {
// 调用trimToSize方法看是否需要回收旧数据
trimToSize(maxSize);
return createdValue;
}
}
```
get方法前半部分是,从 map 里面取值,如果取到就返回。
如果没取到,并且重写了 create(K) 方法,就会先把 create(K) 方法创建的 value 保存到缓存,如果新创建的 value 保存的位置原来有值,就会替换回来。并且执行 entryRemoved 方法给调用者回调。
前面也讲了,LruCache 会根据元素的访问顺序进行排序。其实这里内部调用 LinkedHashMap 的 get 或者 put 方法的时候会调用到 afterNodeAccess 方法, 在 LinkedHashMap 的 afterNodeAccess 方法中对内部元素排序,这在上一篇 LinkedHashMap 中有讲到。
#### evictAll清除全部缓存数据
```java
public final void evictAll() {
trimToSize(-1); // -1 will evict 0-sized elements
}
```
这里还是调用的 trimToSize 方法,传入的 -1,前面分析过,trimToSize 方法内部有一个循环,会在执行了
```java
if (size <= maxSize || map.isEmpty()) {
break;
}
```
以后,才会终止循环,这里传入 -1,也就是当 map.isEmpty() 的时候,终止循环,也就把缓存清空了。
## 最后
通过对前面文章的阅读,相信你对 Android 提供给我们的 LruCache 有了清除的认识。
**概括来说就是:**
LruCache 中维护了一个 LinkedHashMap,该 LinkedHashMap 创建的时候,设置了 accessOrder 为 true,其内部元素不是已插入顺序排序,而是以访问顺序排序的。当调用put()方法获取数据的时候,会在内部的 map 中添加元素,并调用 trimToSize() 判断缓存是否已满,如果满了就删除 LinkedHashMap 中位于头节点的元素,即近期最少访问的元素。当调用 get() 方法访问缓存对象时,就会调用 LinkedHashMap 的 get() 方法获得对应集合元素,进而调用 LinkedHashMap 内部实现的 afterNodeAccess 方法将元素移动到尾节点。
事实上,LRU 算法是一种算法,具体的实现还是要看个人,只不过这里 Google 为我们提供了实现好的 LruCache,我们也是可以自己实现一个类似的 LruCache 的。
最重要的还是要懂思想啊。
- Java 面试题
- String、StringBuffer、StringBuilder 的区别?
- Java 中的四种引用
- 接口和抽象类的本质区别
- 集合框架
- 集合概述
- ArrayList 源码分析
- LinkedList 源码分析
- HashMap 源码分析
- LinkedHashMap 源码分析
- Android提供的 LruCache 的分析
- LinkedList 和 ArrayList 的区别
- 多线程
- 实现多线程的几种方式
- 线程的几种状态
- Thread 的 start() 和 run() 的区别
- sleep() 、yield() 和 wait() 的区别 ?
- notify() 和 notifyAll() 的区别?
- 保证线程安全的方式有哪几种?
- Synchronized 关键字
- volatile 和 synchronized 的区别?
- 如何正确的终止一个线程?
- ThreadLocal 原理分析
- 线程池
- 多线程的三个特征
- 五种线程池,四种拒绝策略,三种阻塞队列
- 给定三个线程如何顺序执行完以后在主线程拿到执行结果
- Java 内存模型
- 判定可回收对象算法
- equals 与 == 操作符
- 类加载机制
- 类加载简单例子
- 算法
- 时间、空间复杂度
- 冒泡排序
- 快速排序
- 链表反转
- IO
- 泛型
- Kolin 面试题
- Android 面试题
- Handler 线程间通信
- Message、MessageQueue、Looper、Handler 的对象关系
- Handler 使用
- Handler 源码分析
- HandlerThread
- AsyncTask
- IntentService
- 三方框架
- Rxjava
- rxjava 操作符有哪些
- 如何解决 RxJava 内存泄漏
- Rxjava 线程切换原理
- map和 flatmap 的区别
- Databinding引起的 java方法大于 65535 的问题
- Glide
- Glide 的缓存原理
- Glide 是如何和生命周期绑定的?不同的Context 有什么区别?
- Glide 、Picasso 、的区别,优劣势,如何选择?
- Jetpack
- 源码分析
- EventBus
- EventBus 源码分析
- RxBus 替代 EventBus
- OkHttp
- OkHttp 源码分析
- OkHttp 缓存分析
- RxPermission
- RxPermission 源码分析
- Retrofit
- create
- Retrofit 源码分析
- 优化
- 启动优化
- 布局优化
- 绘制优化
- 内存优化
- 屏幕适配
- 组件
- Activity
- Frgment
- Service
- ContentProvider
- BroadcastReceiver
- 进程间通信
- Binder机制和AIDL
- AILD 中的接口和普通的接口有什么区别
- in、out、inout 的区别
- Binder 为什么只需要拷贝一次
- 在android中,请简述jni的调用过程
- 生命周期
- Activity 生命周期
- Fragment 生命周期
- Service 生命周期
- onSaveInstanceState() 与 onRestoreIntanceState()
- 前沿技术
- 组件化
- 模块化
- 插件化
- 热更新
- UI - View
- Android 动画
- 事件分发机制
- WebView
- 系统相关
- 谈谈对 Context 的理解
- Android 版本
- App应用启动流程
- App 的打包
- App 的加固
- App 的安装
- Activity 启动流程
- ClassLoader
- Lru 算法加载 Bitmap 三级缓存原理
- Parcelable 和 Serializable 的区别
- Activity的启动流程
- 相关概念
- 网络相关
- Http
- Https
- Http 和 Https 的区别
- 为什么要进行三次握手和四次挥手?
- OkHttp使用Https访问服务器时信任所有证书
- 设计模式
- 单例模式
- 构建者模式
- 工厂模式
- 外观模式
- 代理模式