
[TOC]
# DataPipeline v2.6.0版本介绍
**2019年8月5日**
Version 2.6.0包括以下新增功能和优化。
*****
## **新增功能**
#### **1.一对多的数据同步**
详情见:[如何创建数据同步](创建数据同步.md)
当用户想要将一个数据源同步到多个不同的目的地时,可以选择多个数据目的地,从而省去了用户创建多个任务的麻烦,同时减少任务并发数量,节省操作时间,只需要读取一次即可完成到多个目的地的分发。
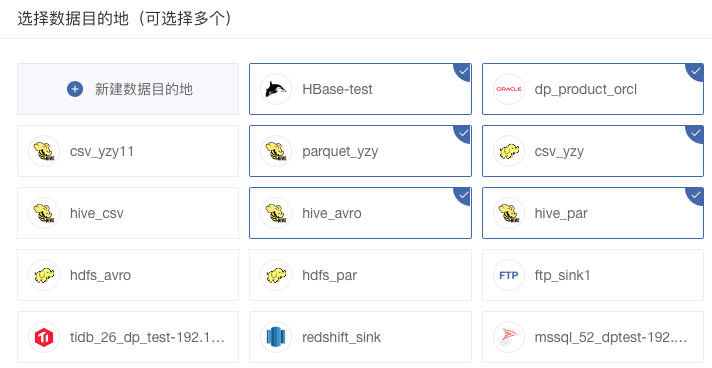
<br/>
#### **2.动态限速和传输队列限制**
详情见:[如何进行任务设置](rwsz.md)
在进行数据同步任务时,有时读取速率远大于写入速率,那么**已经被读取但还未写入**的数据会暂时存储到队列中,但该队列的存储空间有限,当数据已被读取而未被写入,队列存储空间已满时,就会造成数据的丢失。
在该版本中提供了解决方案:
* 可以在任务设置中对数据源设置的【传输队列最大缓存值】和【传输队列回收时间】根据业务数据量进行合理设置,使得队列缓存大小可以满足业务数据量大小
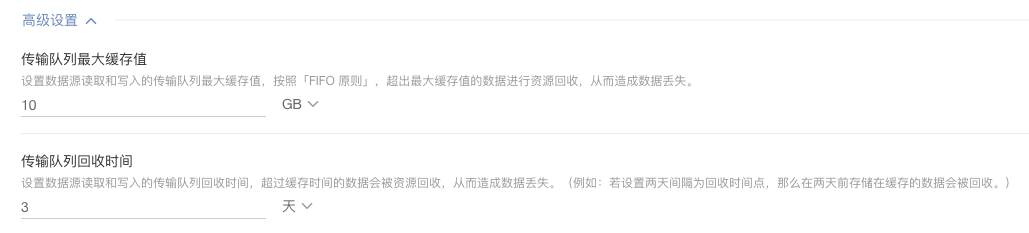
* 除此之外,该版本还提供了【数据任务动态限速】的功能,用户可以开启该功能,当队列满时,进行数据读取限制,以保证数据不会丢失,但会带来读写性能下降。

* **在读取设置界面,对于每个单表级别可以进行单独的传输队列的设置,该优先级高于任务设置。当用户进行了该设置,会优先使用表级别的传输队列设置;若部分表无此设置,则使用任务设置中的传输队列设置**
<br/>
#### **3.批量设置**
详情见:[如何进行读取设置](如何设置读取规则.md)
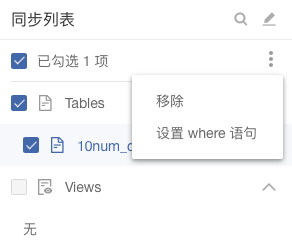
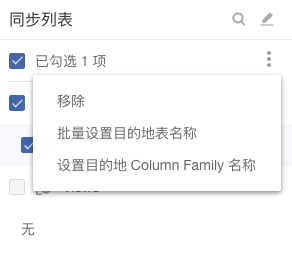
用户在进行读取和写入设置时,可能会需要对每个表进行批量移除、where语句设置和目的地表名设置等,当每个表操作相同时需要多次重复操作,过于繁琐。
在该版本中,可以一次性勾选多个表,批量进行where语句和目的地表名的设置(当目的地为HBase时还包括Column Family设置)
#### **4.端到端一致性功能**
详情见:[如何进行任务设置](rwsz.md)
在数据同步的过程中,当出现暂停任务再开启后,可能会出现任务进度没有被记录的情况,从而导致数据丢失或重复的问题。
该版本提供了读取端和写入端的【事务一致性】选项,开启后,系统会准确记录任务进度,保持数据源和目的地的一致性。


除此之外,在批量读取模式下,提供【写入临时表】选项,将每批数据先写入临时表,本批次写完后再写入实际表,保证数据一致性。

<br/>
#### **5.读取模式优化**
详情见:[如何进行任务设置](rwsz.md)
当用户选择批量模式,可选择增量识别字段进行增量数据的读取和写入,但一些目的地不能实现对数据唯一性的判断,就无法进行增量读取和写入,只能每批都重新写入,从而会造成数据重复。
该版本在任务设置 - 数据目的地设置提供了【清除目标数据表数据】的选项,可以在每批数据写入前清除目标表,从而解决数据重复的问题。

<br/>
#### **6.批量设置读取条件**
详情见:[SQL类型数据源读取条件设置](数据源为SQL类型.md)
当数据源为SQL类型的数据源时,用户可以编辑不同的读取条件来进行数据的同步,在之前的版本中我们支持设置增量识别字段的方式来读取增量,但是要求选择的字段必须为可排序,例如数字或时间类型,推荐的字段类型一般为随数据更新而自增的字段。在本版中支持设置其他的字段作为增量读取条件。
新功能解决的问题:
1\. 在关系型数据库作为数据源的情况下,允许用户针对每一个表设置WHERE读取条件,并提供lastmax方法。
2\. 使用该函数DataPipeline会取该任务下已同步数据中某一个字段的最大值,用户可以使用该值作为WHERE语句读取条件。
3\. 用户使用last\_max()函数,在首次执行该语句或对应字段暂无数值时,则会忽略该函数相关的读取条件。
4\. 允许用户结合其他数据库提供的方法编辑读取条件:
:-: 
#### **7.数据源腾讯云TDSQL**
详情见:[腾讯云TDSQL](chapter1/shu-ju-yuan/pei-zhi-tdsql.md)
新增数据源——腾讯云TDSQL,支持同步到目的支持的所有数据库。
#### **8.Oracle数据源支持Agent的实时读取方式
详情见:[Oracle数据源设置](Oracle数据源设置.md)
数据源Oracle新增实时读取方式——Agent,使用该实时模式时,需要联系DataPipeline的工程师为您部署环境。
## **优化功能**
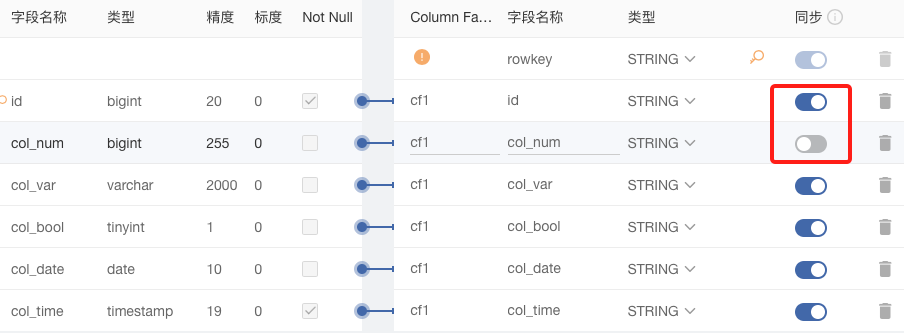
#### **1.同步功能**
详情见:[如何进行写入设置](pzgz.md)
当用户不想同步部分字段时,可单独对每个字段选择是否开启同步按钮。开启标识同步该字段数据,关闭标识该字段不传任何数据。
<br/>
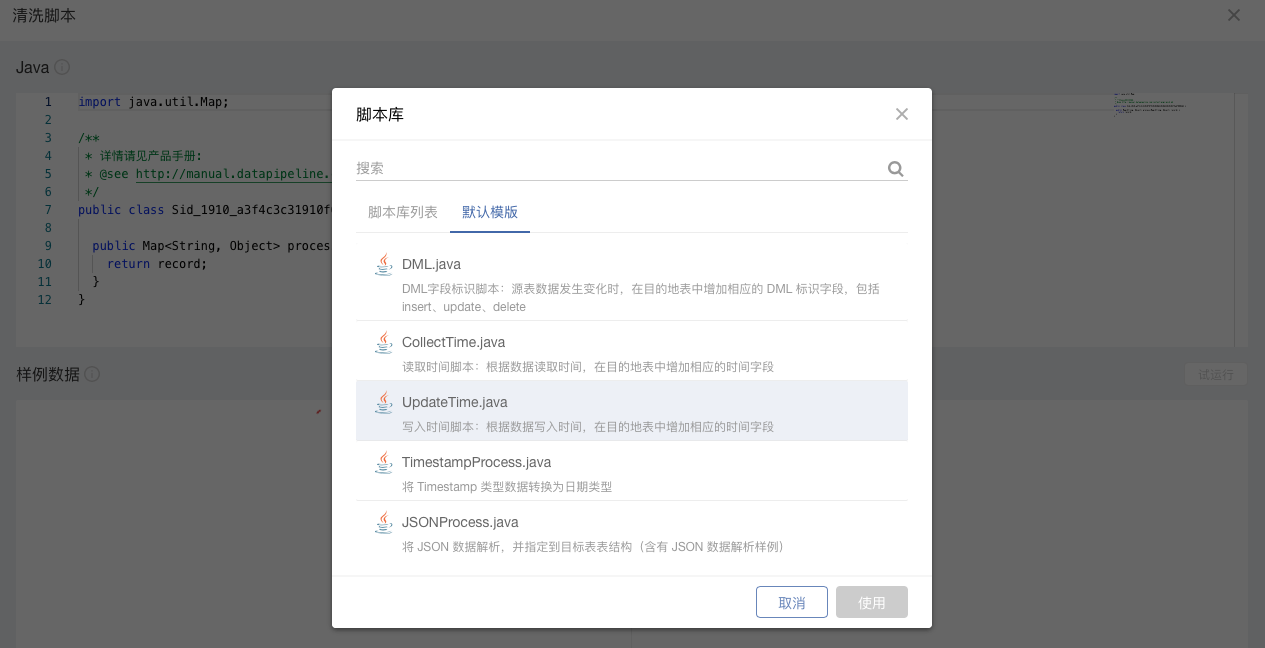
#### **2.高级清洗**
详情见:[如何进行写入设置](pzgz.md)
在清洗脚本中,该版本增加了一些脚本模版,减少用户编写脚本的负担,同时用户也可以保存自己的脚本至脚本库。
<br/>
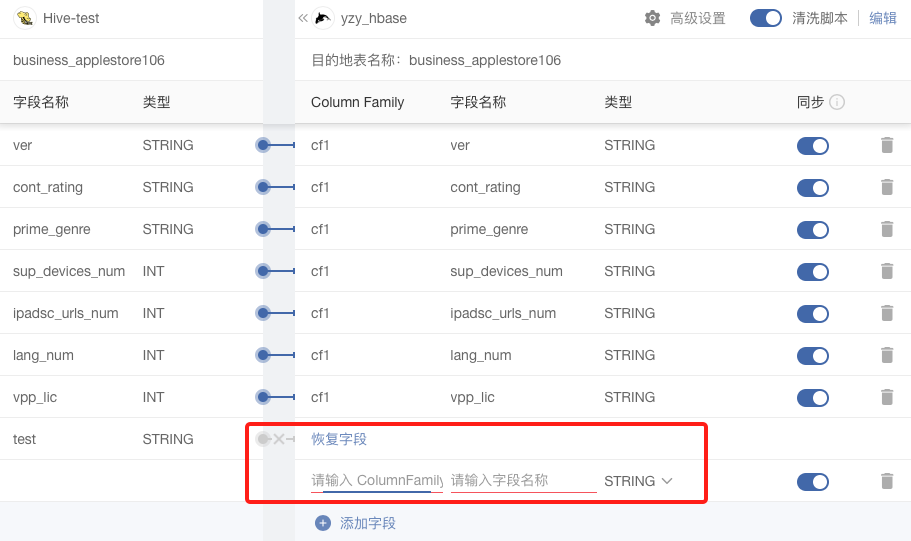
#### **3.动态修改表结构**
详情见:[如何进行写入设置](pzgz.md)
当用户已经激活任务后,想要对字段进行修改,该版本支持用户暂停任务,进行字段的增加和删除功能
<br/>
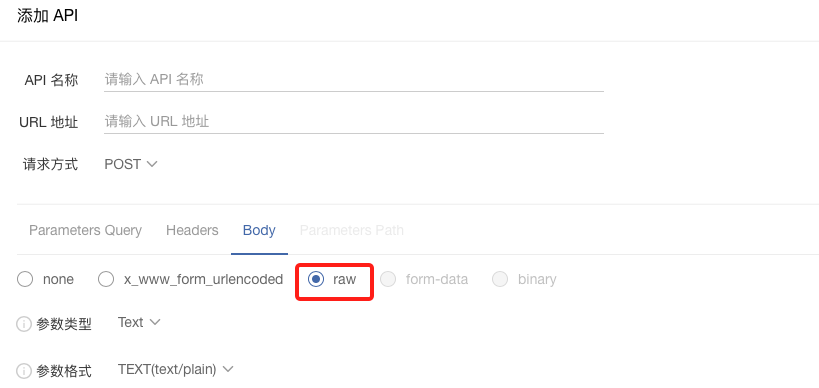
#### **4.API数据源**
详情见:[如何进行读取设置](如何设置读取规则.md)
* 使用API数据源时,增加对「raw」的请求模式的支持
* 添加API时,可对分页参数进行设置,需要选择上面添加过的参数名称,「Parameters Query」和「Headers」下均可添加参数,当参数名相同时,无法区分。
在该版本中,选择分页参数时可看到参数所属模块,即可区分

* API的URL中支持【花括号】的模式,可以支持一些动态参数,该版本添加了「Parameters Path」模块,用以支持【花括号】参数。
<br/>
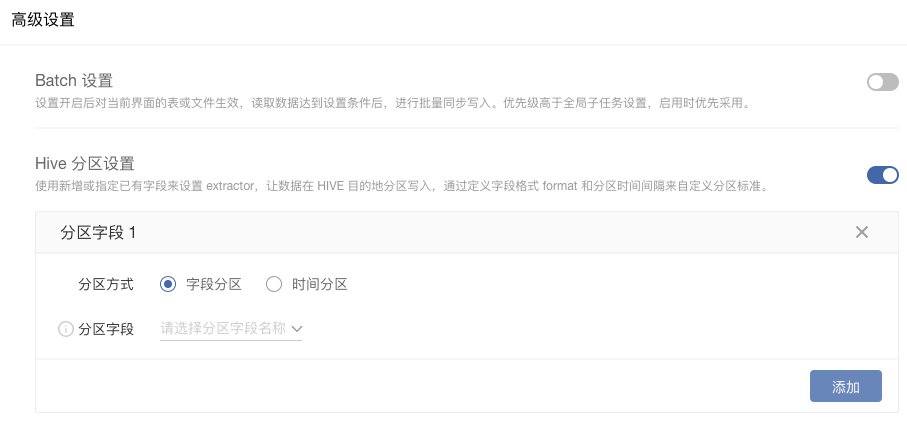
#### **5.Hive目的地动态分区**
详情见:[如何进行写入设置](pzgz.md)
支持字段分区,当数据目的地为hive时,在写入设置中可由用户指定字段进行hive分区
<br/>
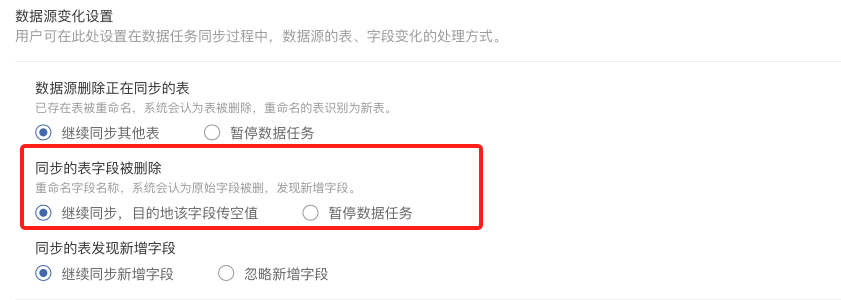
#### **6.Hive目的地增加数据源变化类型**
详情见:[如何进行任务设置](rwsz.md)
在该版本中,当目的地为hive时,数据源变化设置中增加了对【同步的表字段删除】变化的需求支持,用户可以选择「继续同步,目的地该字段传空」或「暂停数据任务」
<br/>
#### **7.重新同步策略优化**
详情见:[如何管理数据同步](yun-wei-guan-li/shu-ju-ren-wu-xiang-qing-ye/ji-ben-xin-xi.md)
当用户已经激活任务后,可能任务出现一些问题时用户希望重新同步。在概览最下方,可选中要同步的表,进行重新同步操作。
在该版本中,重新同步功能提供【删除目的地已存在的存量数据】选项,满足用户可能希望清理之前同步出错的数据,再进行重新同步的要求。
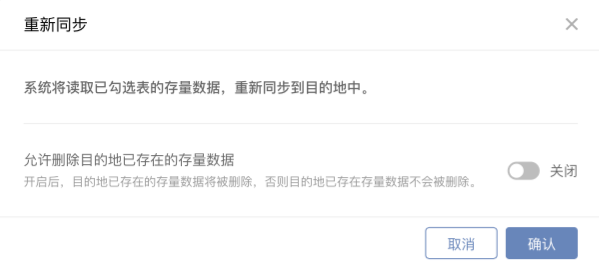
* **当用户选择定时批量读取时,是否要清理目的地数据按照任务设置的配置项来执行相应的操作**

<br/>
#### **8.错误队列支持更多错误类型**
详情见:[如何管理数据同步](yun-wei-guan-li/shu-ju-ren-wu-xiang-qing-ye/ji-ben-xin-xi.md)
在该版本中,当用户新建FTP数据源,FTP数据源设置的字段和实际字段不符时,该类数据错误会进入错误队列。
#### **9.认证方式支持HBase目的地**
详情见:[系统设置](系统设置.md)
在该版本中,用户设置的Kerberos认证方式除了支持 HDFS、Hive 数据目的地,以外新增HBase数据目的地。
<br/><br/><br/>
- DataPipeline产品手册
- 产品更新日志
- v2.7.0 版本介绍
- v2.6.5 版本介绍
- v2.6.0 版本介绍
- v2.5.5 版本介绍
- v2.5.0 版本介绍
- v2.4.5 版本介绍
- v2.4.1 版本介绍
- v2.4.0 版本介绍
- v2.3 版本介绍
- v2.2.5 版本介绍
- v2.2 版本介绍
- v2.1 版本介绍
- v2.0.5 版本介绍
- v2.0 版本介绍
- v2.0 以前版本介绍
- 环境和数据库的部署要求
- Mysql - BINLOG配置方法
- Oracle - LOGMINER配置方法
- SQL Server - Change Tracking配置方法
- Postgre SQL-decoderbufs配置方法
- Postgre SQL-wal2json配置方法
- 常见场景操作
- 场景一:实时同步异构数据库数据(例:MySQL到Oracle)
- 场景二:批量同步异构数据库数据(例:SQL Server到MySQL)
- 场景三:API数据同步到关系型数据库(例:API到MySQL)
- 场景四:Hive数据同步到关系型数据库(例:Hive到SQLServer)
- 场景五:关系型数据库数据同步到Hive(例:Oracle到Hive为例)
- 场景六:Kafka数据同步到关系型数据(例:Kafka到MySQL为例)
- 场景七:一对多场景介绍
- 产品入门
- 数据同步任务
- 创建数据同步
- 配置数据源&数据目的地
- 配置数据源
- 配置MySQL数据源
- 配置Oracle数据源
- 配置SQL Server数据源
- 配置PostgreSQL数据源
- 配置FTP数据源
- 配置S3数据源
- 配置API数据源
- 配置Kafka数据源
- 配置Hive数据源
- 配置阿里云 OSS数据源
- 配置腾讯云TDSQL数据源
- 配置自定义数据源
- 配置数据目的地
- 配置MySQL数据目的地
- 配置Oracle数据目的地
- 配置SQL Server数据目的地
- 配置Greenplum数据目的地
- 配置Redshift数据目的地
- 配置TIDB数据目的地
- 配置FTP数据目的地
- 配置HBase数据目的地
- 配置HDFS数据目的地
- 配置Hive数据目的地
- 配置AnalyticDB for PostgreSQL数据目的地
- 配置Kafka数据目的地
- 数据同步的任务设置
- 读取设置
- 数据源资源组设置
- 批量功能
- SQL类型数据源读取条件设置
- 分数据源读取设置
- MySQL读取设置
- Oracle读取设置
- SQLServer读取设置
- PostgreSQL读取设置
- FTP文件系统读取设置
- S3文件系统读取设置
- Hive读取设置
- Kafka读取设置
- 阿里云OSS读取设置
- API读取设置
- 腾讯云TDSQL读取设置
- Hive数据源读取分区设置
- 其他设置
- 错误队列设置
- 邮件通知设置
- 任务分组设置
- 写入设置
- 批量功能
- 设置清洗脚本
- 数据目的地资源组设置
- 数据目的地设置
- 子任务设置
- 数据源变化设置
- 写入端数据一致性
- 批量读取后,先写入到临时表,再转存到实际表
- 高级设置
- 子任务设置
- Hive分区设置
- Column family 设置
- 数据同步任务管理
- 数据任务监控
- 重要任务
- 故障任务
- 非激活状态
- 性能关注
- 数据任务分组
- 管理数据同步
- 复制功能
- 回滚功能
- 重新同步功能
- 错误队列
- 消息列表
- 文件同步任务
- 创建文件同步
- 配置文件源
- 配置S3文件源
- 配置FTP文件源
- 配置文件目的地
- 配置HDFS文件目的地
- 文件同步的任务设置
- 任务流
- 核心功能介绍
- 新建任务流
- 配置核心组件
- 配置开始任务组件
- 配置数据任务组件
- 配置远程命令执行组件
- 配置延时器组件
- 配置权限设置
- 激活任务流
- 元数据管理
- 查看总览
- 搜索页
- 详情页
- 系统设置
- 数据任务
- 元数据管理
- 用户管理
- 常见问题
- 部署要求
- Docker安装的集群部署方式?
- DataPipeline的并发任务是线程还是进程?
- 分布式架构指的是什么样的框架?
- 生产环境配置推荐及回答?
- DataPipeline的服务是统一管理还是私有化部署?若是私有化部署若要升级怎么操作?
- DataPipeline的Kafka如果与客户目前使用的Kafka版本不一样,是否需要适配?
- 请说明产品的HA和容灾方案 ?
- DataPipeline有多少独立的服务?各容器的作用是什么?
- 在从节点上装mysql,对单表导入1000万数据对任务有影响吗?
- 数据传输
- 数据源/数据目的地
- 基本要求
- 数据源或目的地可以重复使用吗?
- 数据源多个表是否可以写到目的地一张表?
- 数据源或目的地连接失败怎么办?
- 数据源
- MySQL
- DataPieline如何应对Mysql数据库表和字段名称大小写不敏感问题?
- DataPipeline Mysql数据源的实时处理模式下,暂时无法读取哪些字段类型?
- Mysql数据源实时处理模式下,暂不支持那些语句操作的同步?
- Oracle
- Oracle实时模式为LogMiner时,为什么还需要设置读取频率?
- SQL Server
- SQL Server数据源读取方式选择Change Tracking时需要注意什么?
- SQL Server实时模式为Change Tracking时,为什么还需要设置读取频率?
- PostgreSQL
- Hive
- Hive数据源支持哪些文件格式?
- Kafka
- FTP文件系统
- FTP数据源CSV静态表结构时,用户为什么需要确认首行是否为字段名称?
- FTP数据源静态表结构和动态表结构的区别是什么?
- FTP源的文件在不断写入的情况下,DataPipeline的读取与写入的模式是怎样的?
- FTP数据源支持哪些编码方式?
- S3文件系统
- 阿里云OSS文件系统
- API
- 腾讯云TDSQL
- 数据目的地
- MySQL目的地常见问题
- 时区问题需要注意什么?
- SQL Server目的地常见问题
- 行级的物理删除,使用Change Tracking的方式,是否获取的到?DataPipeline会如何处理这类的数据?
- 数据源实时模式是否可以同步视图?
- Oracle目的地常见问题
- TiDB目的地常见问题
- 目的地TIDB同步表时,需要注意什么?
- Redshift目的地常见问题
- Redshift 并发数设置是50,DataPipeline对100个表并发插入的方案?对Redshift 性能的影响?DataPipeline对大数据量并发插入Redshift 的处理方式?
- Hive目的地常见问题
- 如何避免Hive目的地出现小文件问题?
- DataPipeline同步数据到Hive目的地表时,数据源发生变化会怎么样?
- 我们目前对已做好Hive分区逻辑的目的地,是不是不支持继续往里写?只能写新表?
- 配置Hive目的地是需要注意哪些?
- Hive目的地时字段转换需要注意哪些问题?
- GreenPlum目的地常见问题
- Kafka目的地常见问题
- kafka目的地支持设置新的分区吗?
- 多个表结构不一致的表,可以同步至kafka的同一个topic吗?
- HDFS目的地常见问题
- FTP文件系统目的地常见问题
- 目的地FTP时,我们现在是按什么逻辑创建文件的?
- AnalyticDB for PostgreSQL目的地常见问题
- Hbase目的地常见问题
- 目的地常见问题
- 各个数据目的地的写入方式分别是采用什么形式?
- DataPipeline支持的数据库的目标端的连接方式是什么?
- DataPipeline支持的目标端冲突数据处理机制是什么?
- 任务设置
- 读取模式相关问题
- 任务设置中读取频率的实现原理是什么样的?
- 采用实时同步的情况,新建同步任务时,源端的数据表有大量的存量数据,如何通过产品实现数据同步的一致性的?
- 定时批量清目标表数据的逻辑是什么样的?
- 数据源端基于日志的实时模式,是源库推送还是我们做捕获?
- 关系型数据如MySQL,如果出现大量的数据修改,BinLog日志如何抓取,如何实现及时的消费?
- 读取与写入的速率限制是按照任务还是按照表?
- 我们的无侵入性是如何实现的?是完全无侵入性,还是侵入性很小?是否无侵入性就意味着源端服务器没有访问请求的压力,那目的端写入是否还存在压力?
- 动态限速的策略是什么?
- 读写一致性的逻辑是什么?
- v2.6版本增量的逻辑如何实现?
- 重新同步策略问题
- 如果任务激活后进行重新同步,目的地数据会清空吗?
- 读取设置
- 如何设置数据读取条件where语句?有哪些注意事项?
- 用户选择实时模式时,选表时发现有一些表置灰不能同步要想同步这些表该怎么办?
- 同步完成后暂停,取消表后又新加入此表,DataPipeline对于此表的处理策略是什么样的?
- 写入设置
- 表和字段问题
- 目的地表名称和字段名称最长字符长度有什么特定限制吗?以及表名称和字段名称的输入规则要求是什么?
- 同步数据到异构数据库,字段类型会有变化吗?
- 表结构中的精度和标度是什么意思?
- DataPipeline所支持的不同数据类型有哪些?kafka schema的数据类型和不同库间的数据库转换规则?
- 数据源端支持哪些字符集类型?
- Hive作为目的地表需要注意什么?
- Hive作为数据源且格式为parquet时需要注意什么?
- 如何新增一个字段?
- 主键相关问题
- 无主键的表的同步逻辑是怎样的?
- 选择增量识别为主键,如何保证源端和目标的数据一致性呢,如果该记录有修改,系统是怎么处理的?
- 数据目的地ODS有大量无主键表,同步时DataPipeline是如何处理的?
- 表结构变化问题
- 任务激活前后,数据源变化表结构变化有什么不同?
- 当数据源表结构更新时DataPipeline是如何处理的?
- 如果目的地端已经存在了数据库表,但表结构不相同,我们能否将数据写入到该表?
- DataPipeline是否支持将不同的数据表(在不同的数据库中,但是表结构一致,同时有主键和唯一性识别的字段),导入同一个目的端表?
- 管理数据同步
- 基本概念
- 错误通知是什么?
- 错误队列是什么?
- 哪些数据错误会进入错误队列?
- 请简述产品支持的目标端冲突数据处理机制?
- 错误队列里的原始数据是指源端读取的原始数据还是说经过清洗规则后的数据?
- 激活任务后,有哪些参数可以修改?
- 同步状态
- 部分表已读取已写入等都为0,但完成进度为100%?
- 任务详情页中的数据读写量具体含义是?为什么有时候还会减少?
- 如何去查看FTP源和FTP文件中的文件有没有同步完成?
- 数据任务激活后是不允许修改任何设置吗?
- 激活任务后,数据百分比为什么会往回条,如:从99% 跳到30%
- 同步逻辑
- 自动重启逻辑是怎样的?
- 目前数据同步的暂停重启策略是什么样的?暂停和重启后是如何读取和写入数据的?
- 目前进行数据任务的时候,读取速率远大于写入速率,其中,已读取且还未写入的数据会暂时存储在Kafka上,但是由于Kafka存储空间有限,超出后容易造成数据的丢失,这怎么办?
- 如果一条数据多次、频繁变化,在DataPipeline产品侧如何保证数据的并行和保序是如何保证的?
- 用户导入数据后,hdfs认证机制,数据哪些用户可以使用,用户数据安全如何确保?
- 请简述目标端性能可管理性(可提供的性能监控、分析、调优手段等)
- DataPipeline是否支持远程抽取数据?
- 如果一条数据多次、频繁变化,在DataPipeline产品侧如何保证数据的并行和保序是如何保证的?
- 产品到期问题
- 产品使用期限到期所有任务都会被暂停任务,那么如何提前获知产品使用期限是否到期以避免任务被暂停?
- 实际场景中,目的地服务器每周可能会有aws升级,需要暂停服务器,DataPipeline有没有对应的方案能够满足?
- 任务报错
- redis连接异常任务暂停了怎么办?
- 文件传输
- FTP文件源同步整个文件时是如何同步的?
- 任务流
- 如何使用远程命令执行脚本来调取另外一个任务流?
- 任务流开启状态下,任务此时关闭掉任务流,正在同步的组件任务的处理逻辑是什么样的?
- 任务流中上游组件有多个组件任务时,上游任务全部完成才能开启下游任务吗?
- 任务既连了开始键,又配置了依赖,执行逻辑会是什么样的?
- 任务流中新建任务为何只有读取方式为增量识别字段,没有binlog?
- 任务监控
- 什么样的实时传输任务会在性能关注中显示?