
## Kafka
在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。
1)Apache Kafka是一个开源**消息**系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
2)Kafka最初是由LinkedIn公司开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
3)**Kafka** **是一个分布式消息队列。** Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。
4)无论是kafka集群,还是consumer都依赖于**zookeeper**集群保存一些meta信息,来保证系统可用性。
## Kafka架构

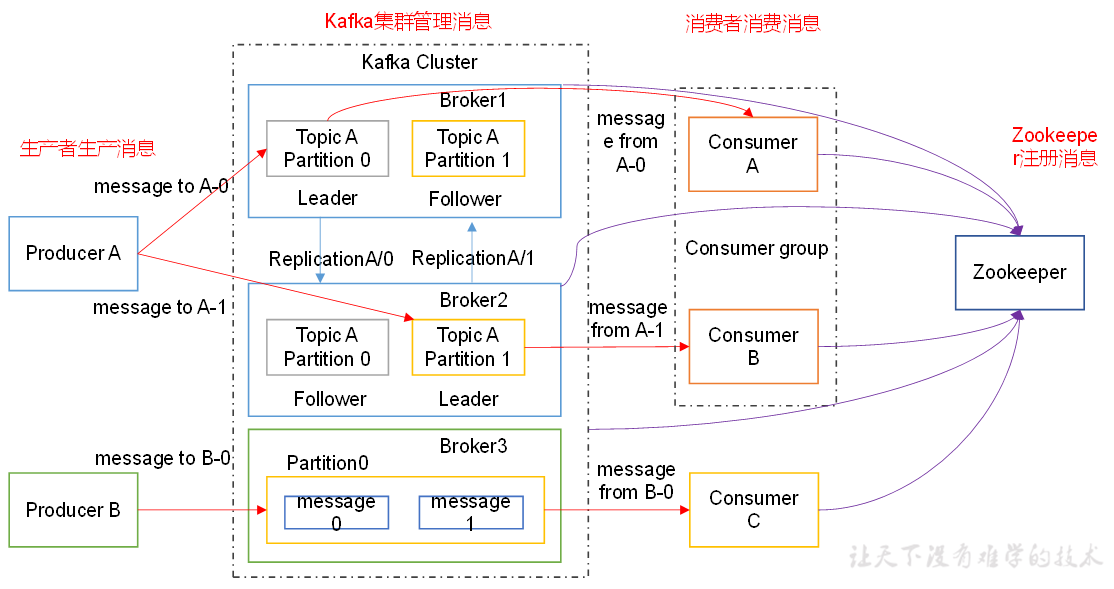
1)Producer :消息生产者,就是向kafka broker发消息的客户端;
2)Consumer :消息消费者,向kafka broker取消息的客户端;
3)Topic :可以理解为一个队列;
4) Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic;
5)Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic;
6)Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序;
7)Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka。
- 概述
- html
- 盒模型
- 块行元素及继承
- 语义化
- html5中新特性
- Doctype
- meta 标签的作用
- defer和async
- CSS
- CSS3新特性
- 选择器优先级
- 清除浮动
- 隐藏元素
- positon-overflow-lineheight-display
- 重排和重绘
- 伪类和伪元素
- BFC
- 浏览器兼容
- 布局
- 三栏布局
- 其他
- 浮动布局
- 绝对布局
- flexbox布局
- grid网格布局
- table表格布局
- 双飞翼布局
- 圣杯布局
- 居中
- 水平居中
- 垂直居中
- 水平垂直居中
- 两栏布局
- 瀑布流布局
- 响应式-自适应布局
- offsetWidth-offsetHeight-offsetLeft-offsetTop
- px-rpx-em-rem-%-vw-vh-vm
- 预处理器-Sass
- Sass代码重用
- sass循环-控制语句
- sass嵌套
- sass数据类型
- Sass基本运算
- css预处理
- Html+CSS编程
- 1px物理像素
- 实现移动端适配
- CSS创建一个三角形
- 满屏品字
- 让Chrome支持小于12px 的文字
- css旋转图
- css-sprites
- 避免CSS全局污染
- 换肤方案
- ES6
- ES6的新特性
- var, let, const
- Proxy和Object.defineProperty
- proxy
- Object.defineProperty
- 箭头函数
- class类
- class基础
- constructor方法
- Class的几个注意点
- for/forEach/for-in/for-of 的区别
- js数组方法--字符串
- js字符串操作
- promise
- Generator函数-async/await
- set/map
- 模块化-import-export
- rest与(...)
- Symbol
- 事件循环eventLoop
- json
- JavaScript
- 数据类型
- call,apply,bind
- 闭包
- 深拷贝浅拷贝
- this-new-callapplybind
- 原型/构造函数/实例
- 作用域和作用域链
- 继承
- 内存-垃圾回收
- 对象-函数创建方式
- 设计模式
- 六大原则
- 单例模式
- 策略模式
- 工厂模式
- 适配器模式
- 代理模式
- 迭代器模式
- 发布订阅模式--观察者模式
- 命令模式
- 组合模式
- 装饰器模式
- js与java区别
- 正则
- 正则案例
- 正则语法
- eval
- js专门编程
- 数组扁平化
- 随机数组
- 去掉数组中重复的数据
- promise题目
- 函数柯里化
- 获取 url 中的参数
- 手动实现map(forEach以及filter也类似)
- 函数节流和防抖函数
- TypeScript
- vue与ts
- 单-多线程
- Vue.js
- 源码原理
- 生命周期
- 组件生命周期调用顺序
- 使用场景-生命周期
- 双向绑定
- MVVM与MVC
- 虚拟DOM
- diff算法
- nextTick异步
- keep-alive
- key
- 组件
- 组件继承
- 组件通信
- props/$emit
- $emit/$on
- Vuex
- Vuex与localStorage
- $attrs/$listeners
- provide/inject
- $parent / $children与 ref
- 组件基础
- 插槽slot
- Vue实现高阶组件
- 指令
- 具体指令
- 自定义指令
- 自定义指令案例
- webpack
- 核心概念
- 打包和拆包
- Loader
- plugin
- vite
- webpack优化
- 写脚手架
- 手写loader和plugin
- vue CLI脚手架
- vue-cli 3 与 2 版本
- Runtime-Compiler和Runtime-only的区别
- run dev和npm run build
- render函数的使用
- Vue程序源码运行过程解析
- vue CLI脚手架安装
- vue-router
- route原理和SPA
- 改变路径
- 基本设置使用
- router参数传递
- 优化-懒加载,嵌套路由
- 单页面多路由
- $route 和 $router
- 导航守卫
- 动态-默认路由
- 设置404页面
- 路由脚本
- vuex
- vuex 认识
- Vuex基本使用
- vuex各模块
- 优化方法
- Mutation
- Action
- vue性能优化
- data-computed-watch
- watch的几种用法
- vue数组
- SPA单页面
- vue和react区别
- vue与angular比较
- vue3.0
- ref-reactive-toRef-toRefs
- setup()-computed()-watch()
- Teleport-Suspense-Fragment-defineAsyncComponent
- 过滤器--filter
- vue3生命周期
- ElementUI源码
- 搭建组件库
- 典型组件实现
- 微前端qiankun
- 服务端渲染nuxtJs
- render()函数
- 剑指offer
- 最小的K个数
- 字符串
- 排列字符串
- 第一个只出现一次的字符
- 和为S的字符串
- 单词翻转序列
- 把字符串转换成整数
- 表示数值的字符串
- 最长不含重复字符的子字符串
- 最长回文
- 电话号码的字母组合
- 二叉树
- 遍历二叉树
- 打印二叉树
- 镜像-翻转二叉树
- 判断平衡二叉树
- 二叉树深度
- 二叉搜索树
- 和为某值的路径
- 重建二叉树
- 判断对称二叉树
- 下一个节点
- 序列化二叉树
- 树的子结构
- 最近公共祖先
- 链表
- 链表中环的入口结点
- 两链表的公共节点
- 从头到尾打印链表
- 倒数第K个结点-链表
- 反转链表
- 合并两个排序的链表
- O(1)时间内删除链表节点
- 复杂链表的复制
- 数组
- 逆序对
- 旋转数组中的最小数字
- 奇数位于偶数前面
- 连续子数组和的最大值
- 只出现一次的数字-数组
- 和为S的两个数字
- 重复数字-数组
- 智力题
- 股票的最大利润
- 扑克牌顺子
- 孩子圆圈
- n个骰子的点数
- 滑动窗口的最大值
- 礼物的最大值
- 丑数
- 斐波那契数列
- 剪绳子
- 栈
- 两个栈实现队列
- 包含main函数的栈
- 栈的压入-弹出序列
- 数字
- 二进制中1的个数
- 数值的整数次方
- 1~n整数中1出现的次数
- 求1+2+3+...+n
- 不用加减乘除做加法
- 和为S的连续正数序列
- X的平方根
- 整数反转
- 素数的个数统计
- 41-和为S的连续正数序列
- 最小公倍数-最大公约数-质数
- 双指针
- 两数、三数之和
- 哈希表
- 字母异位词分组
- 和为K的子数组
- 前 K 个高频元素
- 回溯算法
- 数组的子集
- 全排列
- 并集查
- 岛屿数量
- reactJs
- React-router
- 生命周期-R
- 组件-R
- 组件通信-R
- react组件基础
- 组件渲染
- redux
- react-redux
- redux使用
- Redux中间件
- Redux和Vuex
- react-hook
- 前端--杂
- 原生js
- BOM-浏览器对象模型
- 事件委托
- 原生js添加事件
- js 操作DOM
- 原生js小实验
- 表单
- 点击空白关闭弹窗
- js兼容
- 前端性能优化
- 性能优化-网络
- 回流与重绘
- 图片懒加载
- 渲染几万条数据且不卡住页面
- 前端性能优化总结
- 渲染篇(浏览器渲染)
- 雪碧图
- 图片优化
- CDN
- Ajax、fetch、axios
- axios
- axios原理
- 登录验证
- token
- Session
- 认证-授权- 凭证
- JWT
- 登录-token验证
- 登录代码
- 登录退出-session验证
- cookie
- jQuery
- document load 和 document ready 的区别
- $.get()提交和$.post()提交有区别
- jquery选择器
- 判断checkbox是否选中
- 操作元素和样式--jquery
- 操作DOM-- jquery
- 事件--jquery
- 动画-- jQuery
- 过滤方法-- jQuery
- 查找方法- jQuery
- AJAX --jQuery
- 前端调试
- 监控和埋点
- 错误监控与上报
- 异常捕获问题
- 前端部署
- docker
- jenkins
- 灰度发布
- nginx
- k8s
- jest测试
- 移动端
- 跨端方案
- uni-app
- 移动端常见问题
- react-Native
- npm-yarn-pnpm
- Node.js
- Koa.js
- node汇总
- linux和git
- linux
- git
- git工作原理
- Git和SVN的区别
- rebase 与 merge的区别
- git reset、git revert 和 git checkout 有什么区别
- git pull”和“git fetch
- 解决分支合并冲突
- 代码提交和分支
- 创建配置增加删除
- 代码格式化
- 计算机网络
- 输入url到页面渲染全过程
- TCP和UDP
- 跨域
- 不跨域通信
- 跨域-新
- JSONP
- CORS
- nginx代理跨域
- WebSocket协议跨域
- postMessage跨域
- PostMessage的用法
- Node中间件代理(两次跨域)
- document.domain + iframe
- http状态码
- Http2.0-http1.1
- 七层模型
- tcp拥塞控制和流量控制
- 请求-GET和POST
- 请求报文和响应报文
- cookie-localStorage-sessionStorage
- localStorage-sessionStorage
- 强缓存-弱缓存
- HTTP缓存控制
- 缓存机制
- 具体http缓存机制
- HTTP-HTTPS
- 浏览器通讯
- 网络安全
- XSS攻击
- CSRF攻击
- sql注入原理
- ⽹络劫持
- 长连接和短连接、长轮询和短轮询
- Websocket
- socket
- socket和http
- 数据结构
- 八大排序
- 冒泡排序
- 快速排序
- 直接插入
- 希尔排序
- 堆排序
- 简单选择
- 归并排序
- 基数排序
- 数据结构1
- 数组和链表
- 哈希函数,哈希表
- 数据库
- 事务
- 视图
- insert /update/delete
- create/drop/alter
- 数据库锁
- 数据库索引
- hash-B+
- 索引类型
- select
- join 连接
- 子查询和联合查询
- 范式
- 触发器-存储过程
- 高并发环境
- 优化-数据库
- SQL语句优化
- 索引优化
- 缓存参数优化
- 分库分表
- 分表—水平分割和垂直分割
- 主键 超键 候选键 外键
- 数据库总结
- 项目整理
- 电商APP
- 商品详情
- 目录
- 菜单联动
- mixins混入--backtop回到顶部封装
- better-scroll
- 轮播图原理
- 移动适配
- 大数据开发
- cuda
- 基于深度学习快速检测老鼠脸部并测定其疼痛程度
- yolo
- 深度学习
- 基于 CUDA 并行加速的多图谱三维脑图像分割
- 各大公司笔试题
- 美团
- 一个数是否由数组里的数组成
- 字符串的最长不重复子串长度
- 正则把a字符串替换成b字符串
- 招银
- 恒生电子
- 大数据
- hadoop
- mapreduce
- map 数量 和 reduce 数量
- MapReduce的工作原理
- combiner、partition的作用
- Shuffle
- join
- wordcount例子
- MapReduce优化
- 数据倾斜-mapreduce
- 6个类-mapreduce
- Hdfs
- hdfs文件读流程
- hdfs可靠性策略
- hdfs的体系结构
- 二次排序
- hadoop调度器
- hadoop1.x和hadoop2.x的区别
- NameNode
- 你对hadoop的了解
- yarn
- 启动hadoop的进程-脚本和用法
- Hadoop 序列化和反序列化
- 安装配置hadoop
- hadoop生态圈组件
- hive
- 解决数据倾斜
- 4种排序方式
- 分区和分桶的区别
- Sort By,Order By,Cluster By,Distrbute By
- 内部表和外部表
- hive 底层与数据库交互原理
- Hbase
- rowkey以及热点问题
- habse机制
- zookeeper
- spark
- spark有什么特点
- Spark运行机制与原理
- Spark有哪些组件
- hadoop和spark的shuffle相同和差异
- 几种部署模式
- RDD
- 常见RDD
- 会导致shuffle的算子
- DAG有向无循环图
- map与mapPartitions的区别
- treeReduce与reduce的区别
- foreach和foreachPartition区别
- 宽窄依赖
- groupByKey-aggregateByKey-reduceByKey
- 存储级别StoreLevel
- stage划分过程
- Checkpoint
- 广播变量
- 数据倾斜的现象、原因、后果
- Spark的runtime
- spark内存
- Spark中的OOM问题
- task之间的内存分配
- spark的内存管理机制
- spark的性能优化
- (1)参数优化
- (2)代码优化
- spark streaming
- 从kafka中读数据的两种方式
- kafka
- 消息队列
- Kafka架构
- 另外总结
- flume
- sqoop
- 并发
- 海量数据处理
- topN词语
- 不重复的整数
- HR
- 非技术问答
- 工业互联网
- python
- python语言特点
- 封装继承多态-python
- 类定义和方法-python
- 继承-python
- 重载
- 抽象类和接口类
- 基础语法
- 数字number
- 字符串(String)
- List(列表)
- 删除list里的重复元素
- Set(集合)
- Tuple(元组)
- Dictionary(字典)
- 类型转换
- 自省-反射-is 和 == 获知对象的类型
- 字典推导式
- 单下划线和双下划线
- *args and **kwargs
- 迭代器和生成器
- 新旧式
- python单例模式
- 作用域--Python
- 深拷贝与浅拷贝--Python
- 函数式编程-- Python
- 闭包--python
- 内存管理与垃圾回收机制
- 值传递还是引用传递
- 类方法、类实例方法、静态方法
- 类变量和实例变量
- 模块Python
- Java
- 面向对象和面向过程
- 抽象、封装、继承,多态
- 重载和重写的区别
- 访问控制符public,protected,private
- String和StringBuffer、StringBuilder的区别
- 抽象类和接口的区别
- ----重要对比-----
- Concurrenthashmap实现原理
- ArrayList和LinkedList区别及使用场景
- ArrayList和vector区别
- HashMap和HashTable区别
- HashTable实现原理
- HashMap实现原理
- Collection和Collections的区别
- 多线程
- 多线程的实现方式
- 如何保证线程安全
- synchronized如何使用
- synchronized和Lock的区别
- 多线程如何进行信息交互
- sleep和wait的区别
- 死锁
- 线程的基本状态
- 线程-程序-进程
- 异常处理
- Error、Exception区别
- Java 异常类层次
- 异常处理总结
- NIO,BIO,AIO
- 序列化与反序列化
- 装箱和拆箱
- volatile关键字
- == 与 equals
- final,static,this,super 关键字
- final 关键字
- static 关键字
- this 关键字
- super 关键字
- Java 和 C++的区别
- JVM JDK 和 JRE
- hashCode 与 equals
- Java 中 IO 流
- 继承-java
- JavaWeb
- JDBC访问数据库的基本步骤
- 数据库连接池的原理
- Truncate与delete的区别
- PreparedStatement相比Statement的好处
- C++
- C和C++的区别
- C++中指针和引用的区别
- 结构体struct和共同体union(联合)的区别
- #define和const的区别
- 重载overload-覆盖override-重写overwrite的区别
- 虚函数
- 堆和栈的区别
- 关键字static的作用
- STL中的vector的实现,是怎么扩容的
- C++中volatile
- 操作系统
- 调度算法
- --死锁
- 进程
- 进程状态
- 进程间的通信方式
- 进程与线程的区别
- 进程同步
- 上下文切换
- 进程调度
- 页面置换算法
- 临界资源
- 中断与系统调用
- 分页和分段区别
- 虚拟内存
- 测试
- 黑白单元集成系统
- 黑盒
- 测试用例设计
- 测试例子
- 为什么选择软件测试