
[TOC]
在innodb的引擎实现中,为了实现事务的持久性,构建了重做日志系统。重做日志由两部分组成:内存日志缓冲区(redo log buffer)和重做日志文件。这样设计的目的显而易见,日志缓冲区是为了加快写日志的速度,而重做日志文件为日志数据提供持久化的作用。在innodb的重做日志系统中,为了更好实现日志的易恢复性、安全性和持久化性,引入了以下几个概念:LSN、log block、日志文件组、checkpoint和归档日志。
# 1.LSN
在innodb中的重做日志系统中,定义一个LSN序号,其代表的意思是日志序号。LSN真正的含义是储存引擎向重做日志系统写入的日志量(字节数)。
LSN是不会减小的,它是日志位置的唯一标记。在重做日志写入、checkpoint构建和PAGE头里面都有LSN。
# 2.重做日志结构和关系图
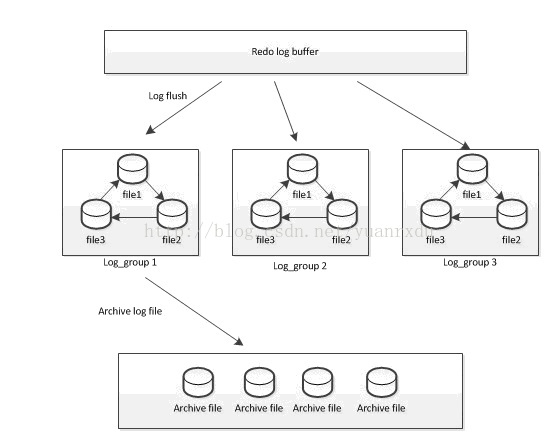
innodb在重做日志实现当中,设计了3个层模块,即redo log buffer、group files和archive files。这三个层模块的描述如下:
redo log buffer 重做日志的日志内存缓冲区,新写入的日志都是先写入到这个地方.redo log buffer中数据同步到磁盘上,必须进行刷盘操作。
group files() 重做日志文件组,一般由3个同样大小的文件组成。3个文件的写入是依次循环的,每个日志文件写满后,即写下一个,日志文件如果都写满时,会覆盖第一次重新写。重做日志组在innodb的设计上支持多个。
archive files(binlog) 归档日志文件,是对重做日志文件做增量备份,它是不会覆盖以前的日志信息。
** 以下是它们关系示意图:**
## 2.1 checkpoint
checkpoint是日志的检查点,其作用就是在数据库异常后,redo log是从这个点的信息获取到LSN,并对检查点以后的日志和PAGE做重做恢复。那么检查点是怎么生成的呢?当日志缓冲区写入的日志LSN距离上一次生成检查点的LSN达到一定差距的时候,就会开始创建检查点,创建检查点首先会将内存中的表的脏数据写入到硬盘,让后再将redo log buffer中小于本次检查点的LSN的日志也写入硬盘。
# 3.日志写入和日志保护机制
innodb有四种日志刷盘行为,分别是异步redo log buffer刷盘、同步redo log buffer刷盘、异步建立checkpoint刷盘和同步建立checkpoint刷盘。在innodb中,刷盘行为是非常耗磁盘IO的,innodb对刷盘做了一套非常完善的策略。
## 3.1重做日志刷盘选项
在innodb引擎中有个全局变量srv\_flush\_log\_at\_trx\_commit,这个全局变量是控制flushdisk的策略,也就是确定调不调用fsync这个函数,什么时候掉这个函数。这个变量有3个值。这三个值的解释如下:
0 每隔1秒由MasterThread控制重做日志模块调用log\_flush\_to\_disk来刷盘,好处是提高了效率,坏处是1秒内如果数据库崩溃,日志和数据会丢失。
1 每次写入重做日志后,都调用fsync来进行日志写入磁盘。好处是每次日志都写入了磁盘,数据可靠性大大提高,坏处是每次调用fsync会产生大量的磁盘IO,影响数据库性能。
2 每次写入重做日志后,都将日志写入日志文件的page cache。这种情况如果物理机崩溃后,所有的日志都将丢失。
## 3.2日志刷盘保护
由于重做日志是一个组内多文件重复写的一个过程,那么意味日志如果不及时写盘和创建checkpoint,就有可能会产生日志覆盖,这是一个我们不愿意看到的。在innodb定义了一个日志保护机制,在存储引擎会定时调用log\_check\_margins日志函数来检查保护机制。简单介绍如下:
引入三个变量 buf\_age、checkpoint\_age和日志空间大小.
buf\_age = lsn -oldest\_lsn;
checkpoint\_age =lsn - last\_checkpoint\_lsn;
日志空间大小 = 重做日志组能存储日志的字节数(通过log\_group\_get\_capacity获得);
当buf\_age >=日志空间大小的7/8时,重做日志系统会将red log buffer进行异步数据刷盘,这个时候因为是异步的,不会造成数据操作阻塞。
当buf\_age >=日志空间大小的15/16时,重做日志系统会将redlog buffer进行同步数据刷盘,这个时候会调用fsync函数,数据库的操作会进行阻塞。
当 checkpoint\_age >=日志空间大小的31/32时,日志系统将进行异步创建checkpoint,数据库的操作不会阻塞。
当 checkpoint\_age == 日志空间大小时,日志系统将进行同步创建checkpoint,大量的表空间脏页和log文件脏页同步刷入磁盘,会产生大量的磁盘IO操作。数据库操作会堵塞。整个数据库事务会挂起。
# 4.日志恢复的主要接口和流程
恢复日志主要的接口函数:
recv\_recovery\_from\_checkpoint\_start 从重做日志组内的最近的checkpoint开始恢复数据
recv\_recovery\_from\_checkpoint\_finish 结束从重做日志组内的checkpoint的数据恢复操作
recv\_recovery\_from\_archive\_start 从归档日志文件中进行数据恢复
recv\_recovery\_from\_archive\_finish 结束从归档日志中的数据恢复操作
recv\_reset\_logs 截取重做日志最后一段作为新的重做日志的起始位置,可能会丢失数据。
**重做日志恢复数据的流程(checkpoint方式)**
1.当MySQL启动的时候,先会从数据库文件中读取出上次保存最大的LSN。
2.然后调用recv\_recovery\_from\_checkpoint\_start,并将最大的LSN作为参数传入函数当中。
3.函数会先最近建立checkpoint的日志组,并读取出对应的checkpoint信息
4.通过checkpoint lsn和传入的最大LSN进行比较,如果相等,不进行日志恢复数据,如果不相等,进行日志恢复。
5.在启动恢复之前,先会同步各个日志组的archive归档状态
6.在开始恢复时,先会从日志文件中读取2M的日志数据到log\_sys->buf,然后对这2M的数据进行scan,校验其合法性,而后将去掉block header的日志放入recv\_sys->buf当中,这个过程称为scan,会改变scanned lsn.
7.在对2M的日志数据scan后,innodb会对日志进行mtr操作解析,并执行相关的mtr函数。如果mtr合法,会将对应的记录数据按space page\_no作为KEY存入recv\_sys->addr\_hash当中。
8.当对scan的日志数据进行mtr解析后,innodb对会调用recv\_apply\_hashed\_log\_recs对整个recv\_sys->addr\_hash进行扫描,并按照日志相对应的操作进行对应page的数据恢复。这个过程会改变recovered\_lsn。
9.如果完成第8步后,会再次从日志组文件中读取2M数据,跳到步骤6继续相对应的处理,直到日志文件没有需要恢复的日志数据。
10.innodb在恢复完成日志文件中的数据后,会调用recv\_recovery\_from\_checkpoint\_finish结束日志恢复操作,主要是释放一些开辟的内存。并进行事务和binlog的处理。
# 5.总结
Innodb的重做日志系统是相当完备的,它为数据的持久化做了很多细微的考虑,它效率直接影响MySQL的写效率,所以我们深入理解了它便以我们去优化它,尤其是在大量数据刷盘的时候。假设数据库的受理的事务速度大于磁盘IO的刷入速度,一定会出现同步建立checkpoint操作,这样数据库是堵塞的,整个数据库都在都在进行脏页刷盘。避免这样的问题发生就是增加IO能力,用多磁盘分散IO压力。也可以考虑SSD这读写速度很高的存储介质来做优化。
- CentOS运维手册
- CentOS6.9挂载额外的磁盘
- ACL(access control list)-权限控制
- 普通用户不能绑定80端口
- ssh8.1p1编译步骤
- 制作openssh8_1的rpm包
- 离线yum源维护
- 去除VIM中打开文件里有的^M字符
- Mysql运维手册
- CentOS6.9搭建Mariadb-Galera集群
- mysql编码报错
- haproxy代理mysql galera
- 常用sql
- MySQL通用知识点
- 修复断电损坏的MySQL数据表
- sync_binlog配置的分析
- Xtrabackup备份与恢复
- Innodb线程并发同步机制
- redo log
- 死锁分析
- 慢SQL分析
- nginx运维手册
- nginx日志分割
- proxy_set_header作用
- nginx优化
- url末尾不加/
- 负载均衡
- haproxy和nginx研究
- haproxy配置
- redis运维手册
- redis_5.0.8集群搭建
- Redis集群原理分析
- predixy的安装和配置
- redis优化
- NFS运维手册
- flock操作失败
- mongodb运维手册
- MongoDB开启用户认证
- shell编码规范
- HTTP
- HTTP的传输编码
- 性能分析
- java内存分析
- javaCPU分析