[TOC]
# 读写流程
## 日志写
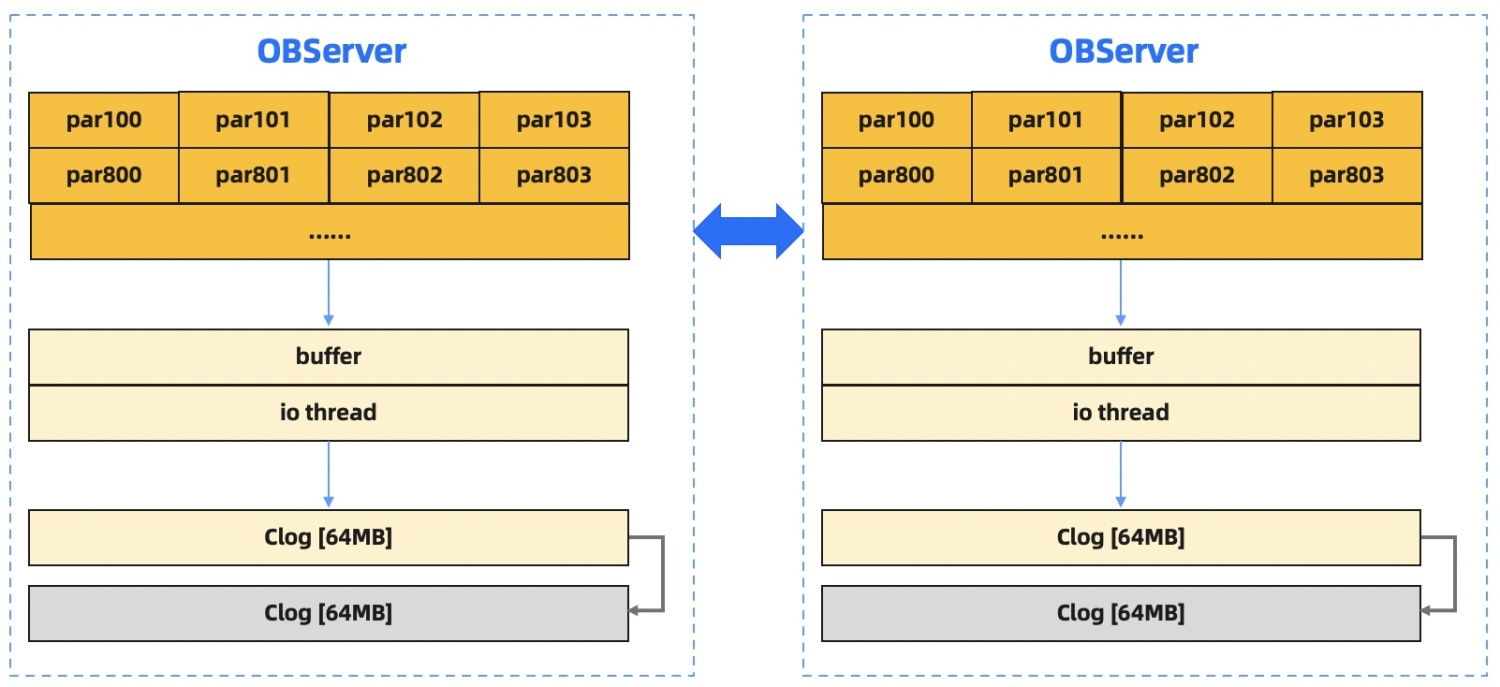
在执行 DML 操作时,为了保证事务性,会产生对应的 redo log,记录对数据行的插入/更新/删除操作,我们将这些日志称之为 clog。
OceanBase 数据库单台物理机上启动一个 observer 进程,有几万~十万 partition,所有 partition 同时共用一个 clog 文件,当写入的 clog 文件超过配置的阈值(默认为 64MB)时,会打开新的 clog 文件进行写入。
observer 收到的某个 partition leader 的写请求产生的 clog、其他节点 observer 同步过来的 clog(存在 partition 同在一个 paxos group),都写入 log buffer 中,由单个 IO thread 批量刷入 clog 文件。
写请求在 partition leader 所在 observer 上等待落盘同时并行同步给其他 observer, 多数派成功后返回 client 成功。
## 数据写
与传统数据库的刷脏页机制不同,OceanBase 数据库的存储引擎基于 LSM Tree 架构,对于数据块的写主要是在转储和合并阶段。在 MemTable 转储为 SSTable 时,也会在静态数据中记录当前的 clog 日志回放点,在转储完成之后,对应 clog 日志回放点之前的日志在理论上就可以被回收了,但通常这些日志文件并不会被立即删除,而是等到日志空间不足时再进行日志文件的重用。
在进行转储/合并时,对于一些较大的 SSTable,我们可能会将一个 SSTable 的数据拆分到多个线程中并行进行转储/合并,对于一张用户表,可以通过表级参数 tablet\_size 来调整并行合并的粒度,当 SSTable 的大小超过表的 tablet\_size 时,就会按照 tablet\_size 对数据进行拆分,开启并行合并;但一般来说,并行合并的并行度不会超过配置的合并线程数。
## 查询流程
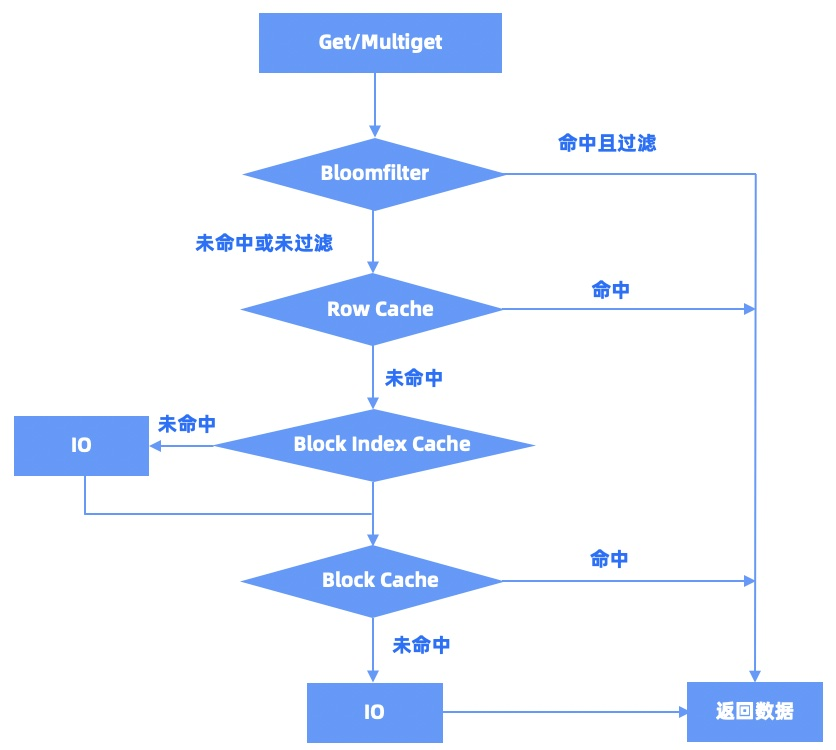
对于数据查询,大体上可以分为以下这么几种:单点查询 Get、多点查询 MultiGet、单 range 扫描、多 range 扫描,以及对于插入操作需要处理的 Exist 查询。
Get/MultiGet/Exist 的查询流程是类似的,如下图所示:
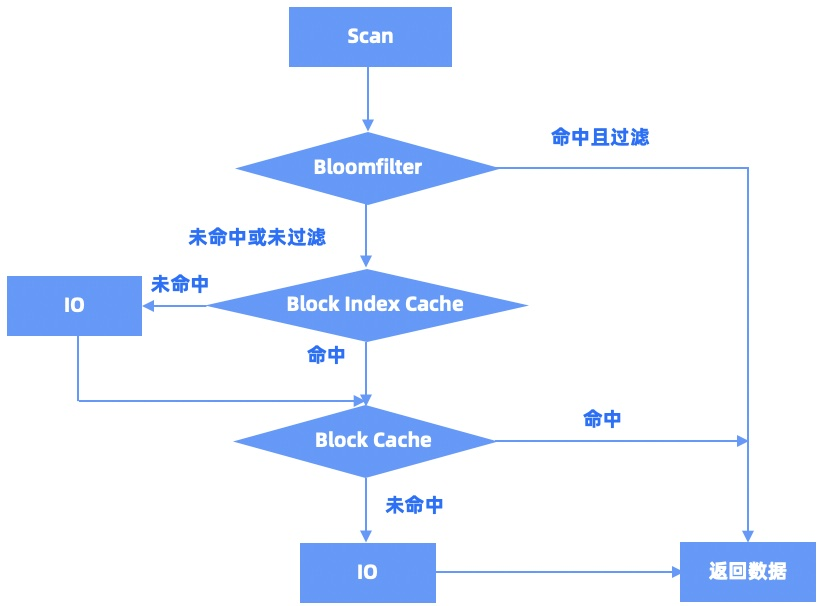
Scan/MultiScan的查询流程是类似的,如下图所示:
- 前言
- 1.说明
- 2.文档更新说明
- docker
- 01.docker安装
- 02.docker加速器
- 03.docker基本使用
- 04.docker 镜像与容器
- 05.Dockerfile
- 06.docker阿里镜像仓库
- 07.docker私有镜像仓库harbor
- 08.docker网络
- 09.docker项目实战01
- 10.docker项目实战02
- 11.docker componse
- 12.docker-compose常用命令
- 13.docker compose 案例
- 14.docker swarm集群
- 15.docker swarm常用命令
- 16.docker swarm 案例
- 17.volume
- 18.network
- 19.idea中部署项目到docker
- 20.docker目录方式挂载sqlite
- 21.docker常用命令补充
- 22.nginx容器代理静态文件403解决
- 23.docker集群管理平台
- k8s
- 01.Kubernetes介绍
- 02.K8s基本概念
- 03.K8s架构图
- 04.Minikube单节点环境搭建
- 05.kubeadm集群安装1.14.0
- 06.虚拟机静态网络配置
- 07.kubeadm高可用集群安装1.14.0
- 08 高可用VIP配置(keepalived+haproxy)
- 09.高可用免密登录
- 10.kubeadm init流程
- 11.k8s体验
- 12.网络插件
- 13.Ingress
- 14.Ingress分类
- 15.Dashboard
- 16.存储
- 01.Volumes
- 02.nfs
- 03.PV PVC
- 04.StorageClass
- 17.基础组件
- 01.Pod
- 02.Service
- 03.ReplicaSet(RS)
- 04.Deployment
- 06.Namespace
- 02.DaemonSet
- 03.StatefulSet
- 04.ReplicationController(RC)
- 06.Job
- 09.PetSet
- 10.StatefulSets
- 11.Federation
- 12.Secret
- 05.Resources
- 13.UserAccount/ServiceAccount
- 14.RBAC
- 18.核心组件
- Master组件
- 01.kube-apiserver
- 02.etcd
- 03.kube-controller-manager
- 04.cloud-controller-manager
- 05.kube-scheduler
- 06.DNS
- Node组件
- 01.kubelet
- 02.kube-proxy
- 03.docker
- 04.RKT
- 05.supervisord
- 06.fluentd
- kubectl
- 19.K8S服务更新部署
- 20.CI/CD
- 01.java安装
- 02.maven安装
- 03.gitlab安装
- 04.git安装
- 05.jenkins安装
- 06.k8s集群
- 07.DockerHub
- 08.实战
- 21.日志
- 01.不同组件日志
- 02.LogPilot+ES+Kibana
- 22.监控
- 23.k8s部署ocp项目[mysql]
- 01.ocp介绍
- 02.环境准备
- 03.镜像准备
- 04.部署说明
- 05.eureka-server
- 06.mysql
- 07.redis
- 08.auth-server
- 09.user-center
- 10.new-api-gateway
- 11.back-center
- 飞致云kubeoperator
- 01.kubeoperator介绍
- 02.kubeoperator安装
- 飞致云DataEase
- 项目介绍
- 系统架构
- 安装部署
- 在线安装
- 离线安装
- 用户手册
- 通用功能
- 数据源
- 数据集
- 视图
- 仪表板
- 系统管理
- 用户管理
- 飞致云JumpServer
- TIDB
- 网络
- 交换机
- ISO/OSI协议模型详解
- 交换CCNP
- RSTP快速生成树协议
- MST多生成树协议
- 以太网信道【应用广泛】
- 广播和多播抑制
- 多层交换
- ARP地址解析协议抑制
- VLAN间路由
- 热备份路由协议HSRP【思科私有】
- 虚拟路由器冗余协议VRRP
- linux
- 01.时间同步
- linux时间不能同步
- Linux挂载磁盘
- 安装ftp
- linux环境ftp账号
- HTTP状态码
- 宝塔
- Centos安装vsftp
- nginx ssl 配置
- datax
- 1.geom类型迁移扩展
- python安装
- 消息中间件
- 1.RocketMQ
- 1.RocketMQ单机环境安装
- 前端
- node踩坑之npm
- 数据库
- Mysql安装
- ClickHouse
- OceanBase数据库
- OceanBase介绍
- OceanBase数据库整体架构
- 快速入门
- 资源准备
- 安装 OBD部署 OceanBase 数据库
- 基本操作
- 数据库操作
- 表操作
- 索引操作
- 插入数据
- 删除数据
- 更新数据
- 提交事务
- 回滚事务
- 安装部署
- 使用 RPM 包安装 OceanBase 数据库
- 使用源码构建 OceanBase 数据库
- 设置无密码 SSH 登录
- 配置时钟源
- 数据分布
- 集群管理
- 租户与资源管理
- 数据分布1
- 数据副本与服务
- 数据均衡
- 数据模型
- 多租户架构
- 系统租户
- 普通租户
- 表格和表组
- 二级索引
- 无主键表
- 视图
- 高可用
- 高可用方案
- 部署模式
- redo 日志管理控制
- 事务管理
- 隔离级别
- 并发控制
- 全局时间戳服务
- 本地事务
- 分布式事务
- 分布式查询
- 存储架构
- LSM Tree 架构
- 内存表 MemTable
- 块存储 SSTable
- 转储和合并
- 缓存机制
- 读写流程
- DDL
- SQL 引擎
- SQL 请求执行流程
- 查询改写
- 基于规则的查询改写
- 基于代价的查询改写
- 查询优化
- 访问路径
- 基于规则的路径选择
- 基于代价的路径选择
- 联接算法
- 联接算法
- 联接顺序
- SQL 执行计划
- 执行计划算子
- TABLE SCAN
- TABLE LOOKUP
- JOIN
- COUNT
- GROUP BY
- WINDOW FUNCTION
- SUBPLAN FILTER
- DISTINCT
- SEQUENCE
- MATERIAL
- SORT
- LIMIT
- FOR UPDATE
- SELECT INTO
- SUBPLAN SCAN
- UNION
- INTERSECT
- EXCEPT/MINUS
- INSERT
- DELETE
- UPDATE
- MERGE
- EXCHANGE
- GI
- 执行计划缓存
- 快速参数化
- 实时执行计划展示
- 分布式执行计划
- 分布式执行和并行查询
- 分布式计划的生成
- 分布式执行计划调度
- 分布式执行计划管理
- 并行查询的执行
- 并行查询的参数调优
- 备份与恢复
- 备份架构
- 恢复架构
- Backup Set
- Archive Log Round
- 管理员指南
- 数据库基础组件介绍
- 数据库管理工具介绍
- OceanBase 客户端
- MySQL 客户端
- 数据库基础管理
- OceanBase 集群管理
- 集群参数管理
- 查询集群参数
- 修改集群参数
- Zone 管理
- 增加或删除 Zone
- 启动或停止 Zone
- 修改 Zone
- OBServer 管理
- 查看 OBServer 状态
- 停止 OBServer
- 启动 OBServer
- 管理 OBServer 节点状态
- 资源管理
- 创建资源单元
- 查看资源单元
- 修改资源单元
- 删除资源单元
- 创建资源池
- 查看资源配置
- 修改资源池
- 删除资源池
- 租户管理
- 创建用户租户
- 新建租户
- 查看租户
- 修改租户
- 删除租户
- 查看租户会话
- 终止租户会话
- 租户管理变量
- 内存管理
- OceanBase 内存结构
- OceanBase 数据库内存上限
- 系统内部内存管理
- 租户内部内存管理
- 执行计划缓存
- 常见内存问题
- 数据库对象管理
- 管理表
- 关于表
- 创建表
- 定义自增列
- 定义列的约束类型
- 查看表的定义
- 更改表
- 清空表
- 删除表
- 管理表组
- 关于表组
- 表组管理命令
- 管理索引
- 关于索引
- 创建索引
- 查看索引
- 删除索引
- 视图和同义词管理
- 管理视图
- 管理同义词
- 数据分布和链路管理
- 分区表和分区索引管理
- 关于分区
- 分区策略
- 创建分区表
- 一级分区表
- 二级分区表
- 维护分区表
- 一级分区表
- 二级分区表
- 分区裁剪
- 分区命名与查询
- 在分区表上建立索引
- 局部索引
- 全局索引
- 使用索引
- 副本管理
- 表级副本的使用
- Locality 管理
- 修改租户的 Locality
- 事务管理
- 提交事务
- 回滚事务
- 事务隔离级别
- 用户权限管理
- 创建用户
- 修改用户权限
- 查看白名单
- 锁定和解锁用户
- 删除用户
- 数据高可用
- 回收站管理
- 回收站支持的对象
- 数据库、表和索引级回收站
- 租户级回收站
- 物理备份与恢复管理
- 部署 NFS
- 备份数据
- 通过命令行备份
- 查看备份进度
- 停止备份
- 删除过期的备份
- 清理备份数据
- 取消清理备份数据
- 恢复数据
- 执行恢复
- 查看恢复进度和结果
- 备份维护
- 开发者指南
- 关于OceanBase数据库
- OceanBase 集群简介
- OceanBase 租户简介
- MySQL 租户数据库对象
- MySQL 客户端
- OceanBase 客户端(obclient)
- 关于结构化查询语言
- Java 数据库连接驱动(JDBC)
- 连接OceanBase数据库
- 通过 MySQL 客户端连接 OceanBase 租户
- 通过 obclient 连接 OceanBase 租户
- 创建 OceanBase 示例数据库 TPCC
- 通过 obclient 探索 OceanBase MySQL 租户
- 查询表数据
- 关于查询语句
- 查询表里符合特定搜索条件的数据
- 对查询的结果进行排序
- 从多个表里查询数据
- 在查询中使用操作符和函数
- 查看查询执行计划
- 在查询中使用 SQL Hint
- 关于查询超时设计
- 关于 DML 语句和事务
- 关于 DML 语句
- 关于 INSERT 语句
- 关于 UPDATE 语句
- 关于 DELETE 语句
- 关于 REPLACE INTO 语句
- 关于事务控制语句
- 提交事务
- 回滚事务
- 事务保存点
- 关于事务超时
- 创建和管理数据库对象
- 关于 DDL 语句
- 创建数据库
- 创建和管理表
- 关于 SQL 数据类型
- 创建表
- 关于自增列
- 关于列的约束类型
- 关于表的索引
- 闪回被删除的表
- 创建和管理分区表
- 分区路由
- 分区策略
- 分区表的索引
- 分区表使用建议
- 创建和管理表组
- 关于表组
- 创建表时指定表组
- 查看表组信息
- 向表组中增加表
- 删除表组
- 创建和管理视图
- 创建视图
- 修改视图
- 删除视图
- 向 OceanBase 迁移数据
- DataX
- 不同数据源的 DataX 读写插件示例
- OceanBase 数据加载技术
- 附录
- OceanBase 常用参数和变量
- OceanBase 常用 SQL
- SQL参考
- 基本元素
- 运算符
- 函数
- 函数
- 聚集函数
- 分析函数
- 信息函数
- 其它函数
- 查询和子查询
- 连接
- 集合
- SQL语句
- 通用语法
- ALTER DATABASE
- ALTER OUTLINE
- ALTER RESOURCE POOL
- ALTER RESOURCE UNIT
- ALTER SYSTEM
- ALTER TABLE
- ALTER TABLEGROUP
- ALTER TENANT
- ALTER USER
- CREATE DATABASE
- CREATE INDEX
- CREATE OUTLINE
- CREATE RESOURCE POOL
- CREATE RESOURCE UNIT
- CREATE RESTORE POINT
- CREATE SYNONYM
- CREATE TABLE
- CREATE TABLEGROUP
- CREATE TENANT
- CREATE USER
- CREATE VIEW
- DELETE
- DROP DATABASE
- DROP INDEX
- DROP OUTLINE
- DROP RESOURCE POOL
- DROP RESOURCE UNIT
- DROP RESTORE POINT
- DROP TABLE
- DROP TABLEGROUP
- DROP TENANT
- DROP SYNONYM
- DROP USER
- DROP VIEW
- EXPLAIN
- FLASHBACK DATABASE
- FLASHBACK TABLE
- FLASHBACK TENANT
- GRANT
- INSERT
- KILL
- PURGE DATABASE
- PURGE INDEX
- PURGE RECYCLEBIN
- PURGE TABLE
- PURGE TENANT
- RENAME TABLE
- RENAME USER
- REPLACE
- REVOKE
- SAVEPOINT
- SCHEMA
- SELECT
- SESSION
- SET PASSWORD
- SHOW GRANTS
- SHOW RECYCLEBIN
- TRANSACTION
- TRUNCATE TABLE
- UPDATE
- SQL调优指南
- SQL请求执行流程
- SQL 执行计划
- SQL 执行计划简介
- 执行计划算子
- TABLE SCAN
- TABLE LOOKUP
- JOIN
- COUNT
- GROUP BY
- WINDOW FUNCTION
- SUBPLAN FILTER
- DISTINCT
- SEQUENCE
- MATERIAL
- SORT
- LIMIT
- FOR UPDATE
- SELECT INTO
- SUBPLAN SCAN
- UNION
- INTERSECT
- EXCEPT/MINUS
- INSERT
- DELETE
- UPDATE
- MERGE
- EXCHANGE
- GI
- 执行计划缓存
- 快速参数化
- 实时执行计划展示
- 分布式执行计划
- 分布式执行和并行查询
- 分布式计划的生成
- 分布式执行计划调度
- 分布式执行计划管理
- 并行查询的执行
- 并行查询的参数调优
- 参考指南
- 系统视图
- 概述
- 字典视图
- mysql.help_topic
- mysql.help_category
- mysql.help_keyword
- mysql.help_relation
- mysql.db
- mysql.proc
- mysql.time_zone
- mysql.time_zone_name
- mysql.time_zone_transition
- mysql.time_zone_transition_type
- mysql.user
- information_schema.CHARACTER_SETS
- information_schema.COLLATIONS
- information_schema.COLLATION_CHARACTER_SET_APPLICABILITY
- information_schema.COLUMNS
- information_schema.DBA_OUTLINES
- information_schema.ENGINES
- information_schema.GLOBAL_STATUS
- information_schema.GLOBAL_VARIABLES
- information_schema.KEY_COLUMN_USAGE
- information_schema.PARAMETERS
- information_schema.PARTITIONS
- information_schema.PROCESSLIST
- information_schema.REFERENTIAL_CONSTRAINTS
- information_schema.ROUTINES
- information_schema.SCHEMATA
- information_schema.SCHEMA_PRIVILEGES
- information_schema.SESSION_STATUS
- information_schema.SESSION_VARIABLES
- information_schema.STATISTICS
- information_schema.TABLES
- information_schema.TABLE_CONSTRAINTS
- information_schema.TABLE_PRIVILEGES
- information_schema.USER_PRIVILEGES
- information_schema.USER_RECYCLEBIN
- information_schema.VIEWS
- oceanbase.CDB_OB_BACKUP_ARCHIVELOG_SUMMARY
- oceanbase.CDB_OB_BACKUP_JOB_DETAILS
- oceanbase.CDB_OB_BACKUP_SET_DETAILS
- oceanbase.CDB_OB_BACKUP_PROGRESS
- oceanbase.CDB_OB_BACKUP_SET_EXPIRED
- oceanbase.CDB_OB_BACKUP_ARCHIVELOG_PROGRESS
- oceanbase.CDB_OB_BACKUP_CLEAN_HISTORY
- oceanbase.CDB_OB_BACKUP_TASK_CLEAN_HISTORY
- oceanbase.CDB_OB_RESTORE_PROGRESS
- oceanbase.CDB_OB_RESTORE_HISTORY
- oceanbase.CDB_CKPT_HISTORY
- oceanbase.CDB_OB_BACKUP_VALIDATION_JOB
- oceanbase.CDB_OB_BACKUP_VALIDATION_JOB_HISTORY
- oceanbase.CDB_OB_TENANT_BACKUP_VALIDATION_TASK
- oceanbase.CDB_OB_BACKUP_VALIDATION_TASK_HISTORY
- oceanbase.CDB_OB_BACKUP_BACKUP_ARCHIVELOG_SUMMARY
- oceanbase.CDB_OB_BACKUP_BACKUPSET_TASK_HISTORY
- oceanbase.CDB_OB_BACKUP_BACKUPSET_TASK
- oceanbase.CDB_OB_BACKUP_BACKUPSET_JOB_HISTORY
- oceanbase.CDB_OB_BACKUP_BACKUPSET_JOB
- oceanbase.CDB_OB_BACKUP_SET_OBSOLETE
- 性能视图
- gv$plan_cache_stat
- gv$plan_cache_plan_stat
- gv$session_event
- gv$session_wait
- gv$session_wait_history
- gv$system_event
- gv$sesstat
- gv$sysstat
- gv$sql_audit
- gv$latch
- gv$memory
- gv$memstore
- gv$memstore_info
- gv$plan_cache_plan_explain
- gv$obrpc_outgoing
- gv$obrpc_incoming
- gv$sql
- gv$sql_plan_monitor
- gv$outline
- gv$concurrent_limit_sql
- gv$sql_plan_statistics
- gv$server_memstore
- gv$unit_load_balance_event_history
- gv$tenant
- gv$database
- gv$table
- gv$unit
- gv$partition
- gv$lock_wait_stat
- gv$session_longops
- gv$tenant_memstore_allocator_info
- gv$minor_merge_info
- gv$tenant_px_worker_stat
- gv$partition_audit
- gv$ps_stat
- gv$ps_item_info
- gv$sql_workarea
- gv$sql_workarea_histogram
- gv$ob_sql_workarea_memory_info
- gv$server_schema_info
- gv$merge_info
- gv$lock
- gv$sstable
- gv$ob_trans_table_status
- v$statname
- v$event_name
- v$session_event
- v$session_wait
- v$session_wait_history
- v$sesstat
- v$sysstat
- v$system_event
- v$memory
- v$memstore
- v$memstore_info
- v$plan_cache_stat
- v$plan_cache_plan_stat
- v$plan_cache_plan_explain
- v$sql_audit
- v$obrpc_outgoing
- v$obrpc_incoming
- v$sql
- v$sql_monitor
- v$sql_plan_monitor
- v$sql_plan_statistics
- v$unit
- v$partition
- v$lock_wait_stat
- v$session_longops
- v$latch
- v$tenant_memstore_allocator_info
- v$tenant_px_worker_stat
- v$partition_audit
- v$ob_cluster
- v$ob_standby_status
- v$ob_cluster_stats
- v$ob_cluster_event_history
- v$ps_stat
- v$ps_item_info
- v$sql_workarea
- v$sql_workarea_active
- v$sql_workarea_histogram
- v$ob_sql_workarea_memory_info
- v$ob_timestamp_service
- v$server_schema_info
- v$merge_info
- v$lock
- v$sql_monitor_statname
- v$restore_point
- v$ob_cluster_failover_info
- v$encrypted_tables
- v$encrypted_tablespaces
- v$sstable
- v$ob_trans_table_status
- 系统变量
- 系统变量概述
- auto_increment_increment
- auto_increment_offset
- autocommit
- character_set_client
- character_set_connection
- character_set_database
- character_set_results
- character_set_server
- character_set_system
- collation_connection
- collation_database
- collation_server
- interactive_timeout
- last_insert_id
- max_allowed_packet
- sql_mode
- time_zone
- tx_isolation
- version_comment
- wait_timeout
- binlog_row_image
- character_set_filesystem
- connect_timeout
- datadir
- debug_sync
- div_precision_increment
- explicit_defaults_for_timestamp
- group_concat_max_len
- identity
- lower_case_table_names
- net_read_timeout
- net_write_timeout
- read_only
- sql_auto_is_null
- sql_select_limit
- timestamp
- tx_read_only
- version
- sql_warnings
- max_user_connections
- init_connect
- license
- net_buffer_length
- system_time_zone
- query_cache_size
- query_cache_type
- sql_quote_show_create
- max_sp_recursion_depth
- sql_safe_updates
- ob_proxy_partition_hit
- ob_log_level
- ob_max_parallel_degree
- ob_query_timeout
- ob_read_consistency
- ob_enable_transformation
- ob_trx_timeout
- ob_enable_plan_cache
- ob_enable_index_direct_select
- ob_proxy_set_trx_executed
- ob_enable_aggregation_pushdown
- ob_last_schema_version
- ob_global_debug_sync
- ob_proxy_global_variables_version
- ob_enable_trace_log
- ob_enable_hash_group_by
- ob_enable_blk_nestedloop_join
- ob_bnl_join_cache_size
- ob_org_cluster_id
- ob_plan_cache_percentage
- ob_plan_cache_evict_high_percentage
- ob_plan_cache_evict_low_percentage
- recyclebin
- ob_capability_flag
- ob_stmt_parallel_degree
- is_result_accurate
- error_on_overlap_time
- ob_compatibility_mode
- ob_create_table_strict_mode
- ob_sql_work_area_percentage
- ob_route_policy
- ob_enable_transmission_checksum
- foreign_key_checks
- ob_enable_truncate_flashback
- ob_tcp_invited_nodes
- sql_throttle_current_priority
- sql_throttle_priority
- sql_throttle_rt
- sql_throttle_network
- auto_increment_cache_size
- ob_enable_jit
- ob_timestamp_service
- plugin_dir
- undo_retention
- ob_sql_audit_percentage
- ob_enable_sql_audit
- optimizer_use_sql_plan_baselines
- optimizer_capture_sql_plan_baselines
- parallel_max_servers
- parallel_servers_target
- ob_trx_idle_timeout
- block_encryption_mode
- ob_reserved_meta_memory_percentage
- ob_check_sys_variable
- tracefile_identifier
- transaction_isolation
- ob_trx_lock_timeout
- validate_password_check_user_name
- validate_password_length
- validate_password_mixed_case_count
- validate_password_number_count
- validate_password_policy
- validate_password_special_char_count
- default_password_lifetime
- ob_trace_info
- secure_file_priv
- ob_pl_block_timeout
- performance_schema
- transaction_read_only
- resource_manager_plan
- 系统配置项
- 系统配置项概述
- auto_leader_switch_interval
- auto_delete_expired_backup
- autoinc_cache_refresh_interval
- audit_sys_operations
- audit_trail
- balancer_idle_time
- balancer_log_interval
- balancer_timeout_check_interval
- balancer_task_timeout
- balancer_tolerance_percentage
- balancer_emergency_percentage
- balance_blacklist_failure_threshold
- balance_blacklist_retry_interval
- backup_concurrency
- backup_dest
- backup_net_limit
- backup_recovery_window
- backup_region
- builtin_db_data_verify_cycle
- bf_cache_miss_count_threshold
- bf_cache_priority
- cache_wash_threshold
- clog_cache_priority
- clog_sync_time_warn_threshold
- clog_disk_usage_limit_percentage
- clog_transport_compress_all
- clog_transport_compress_func
- clog_persistence_compress_func
- clog_max_unconfirmed_log_count
- cluster
- cluster_id
- cpu_count
- cpu_quota_concurrency
- cpu_reserved
- config_additional_dir
- data_copy_concurrency
- data_dir
- datafile_disk_percentage
- dtl_buffer_size
- datafile_size
- debug_sync_timeout
- default_compress_func
- default_compress
- default_progressive_merge_num
- default_row_format
- devname
- data_disk_usage_limit_percentage
- disk_io_thread_count
- dead_socket_detection_timeout
- enable_clog_persistence_compress
- election_cpu_quota
- enable_one_phase_commit
- enable_sys_unit_standalone
- enable_pg
- enable_smooth_leader_switch
- election_blacklist_interval
- enable_election_group
- enable_auto_leader_switch
- enable_global_freeze_trigger
- enable_manual_merge
- enable_merge_by_turn
- enable_perf_event
- enable_rebalance
- enable_record_trace_log
- enable_record_trace_id
- enable_early_lock_release
- enable_rereplication
- enable_rich_error_msg
- enable_rootservice_standalone
- enable_sql_audit
- enable_sql_operator_dump
- enable_async_syslog
- enable_syslog_recycle
- enable_syslog_wf
- enable_upgrade_mode
- enable_separate_sys_clog
- enable_ddl
- enable_major_freeze
- enable_rebuild_on_purpose
- enable_log_archive
- enable_monotonic_weak_read
- external_kms_info
- freeze_trigger_percentage
- flush_log_at_trx_commit
- fuse_row_cache_priority
- force_refresh_location_cache_interval
- force_refresh_location_cache_threshold
- get_leader_candidate_rpc_timeout
- global_major_freeze_residual_memory
- global_write_halt_residual_memory
- ignore_replay_checksum_error
- global_index_build_single_replica_timeout
- high_priority_net_thread_count
- ignore_replica_checksum_error
- ignore_replay_checksum_error
- index_cache_priority
- index_clog_cache_priority
- index_info_block_cache_priority
- internal_sql_execute_timeout
- large_query_worker_percentage
- large_query_threshold
- leak_mod_to_check
- lease_time
- location_cache_cpu_quota
- location_cache_expire_time
- location_cache_priority
- location_cache_refresh_min_interval
- location_fetch_concurrency
- location_refresh_thread_count
- log_archive_checkpoint_interval
- log_archive_concurrency
- log_restore_concurrency
- major_freeze_duty_time
- max_kept_major_version_number
- max_string_print_length
- max_syslog_file_count
- merge_stat_sampling_ratio
- major_compact_trigger
- memory_chunk_cache_size
- memory_limit
- memory_limit_percentage
- memory_reserved
- merge_thread_count
- merger_check_interval
- merger_completion_percentage
- merger_switch_leader_duration_time
- merger_warm_up_duration_time
- max_px_worker_count
- migration_disable_time
- min_observer_version
- minor_deferred_gc_time
- minor_freeze_times
- minor_warm_up_duration_time
- mysql_port
- minor_merge_concurrency
- multiblock_read_gap_size
- multiblock_read_size
- micro_block_merge_verify_level
- migrate_concurrency
- minor_compact_trigger
- memstore_limit_percentage
- net_thread_count
- obconfig_url
- ob_enable_batched_multi_statement
- partition_table_check_interval
- partition_table_scan_batch_count
- plan_cache_evict_interval
- px_task_size
- px_workers_per_cpu_quota
- replica_safe_remove_time
- resource_hard_limit
- resource_soft_limit
- rootservice_async_task_queue_size
- rootservice_async_task_thread_count
- rootservice_list
- rootservice_ready_check_interval
- row_compaction_update_limit
- row_purge_thread_count
- rpc_port
- rpc_timeout
- restore_concurrency
- rootservice_memory_limit
- rebuild_replica_data_lag_threshold
- schema_history_expire_time
- ssl_client_authentication
- server_check_interval
- server_data_copy_in_concurrency
- server_data_copy_out_concurrency
- server_permanent_offline_time
- stack_size
- server_balance_critical_disk_waterlevel
- server_balance_disk_tolerance_percent
- system_memory
- server_balance_cpu_mem_tolerance_percent
- server_cpu_quota_max
- server_cpu_quota_min
- sql_audit_memory_limit
- sys_bkgd_io_high_percentage
- sys_bkgd_io_low_percentage
- sys_bkgd_io_timeout
- sys_bkgd_net_percentage
- sys_bkgd_migration_change_member_list_timeout
- sys_bkgd_migration_retry_num
- syslog_level
- switchover_process_thread_count
- system_cpu_quota
- sys_cpu_limit_trigger
- syslog_io_bandwidth_limit
- tablet_size
- tableapi_transport_compress_func
- tenant_task_queue_size
- tenant_groups
- trace_log_slow_query_watermark
- trace_log_sampling_interval
- trx_2pc_retry_interval
- trx_force_kill_threshold
- tde_method
- token_reserved_percentage
- unit_balance_resource_weight
- user_block_cache_priority
- user_row_cache_priority
- user_tab_col_stat_cache_priority
- user_iort_up_percentage
- use_large_pages
- virtual_table_location_cache_expire_time
- workers_per_cpu_quota
- wait_leader_batch_count
- writing_throttling_maximum_duration
- writing_throttling_trigger_percentage
- weak_read_version_refresh_interval
- workarea_size_policy
- zone
- zone_merge_concurrency
- zone_merge_order
- zone_merge_timeout
- ob_ssl_invited_common_names
- ssl_external_kms_info
- ob_event_history_recycle_interval
- backup_log_archive_checkpoint_interval
- plsql_ccflags
- plsql_code_type
- plsql_debug
- plsql_optimize_level
- plsql_v2_compatibility
- plsql_warnings
- recyclebin_object_expire_time
- log_archive_batch_buffer_limit
- clog_disk_utilization_threshold
- backup_backup_archive_log_batch_count
- backup_backup_archivelog_retry_interval
- backup_backupset_batch_count
- backup_backupset_retry_interval
- open_cursors
- fast_recovery_concurrency
- 预留关键字
- 部署实践
- 设置无密码 SSH 登录
- 单机安装
- 本地安装
- 分布式安装
- 创建租户
- OceanBaseDeploy(OBD)常用命令
- 大数据
- 数据仓库分层
- 数据仓库分层实践
- hive安装
- hive命令
- hadoop安装
- jdk安装
- 应龙inlong
- 网关
- apisix
- apisix2.7源码安装
- apisix rpm2.6安装
- apisix-dashboard2.7 rpm安装
- apisix-dashboard使用
- apisix-dashboard进阶