
# :-: 前端页面性能指标数据采集架构
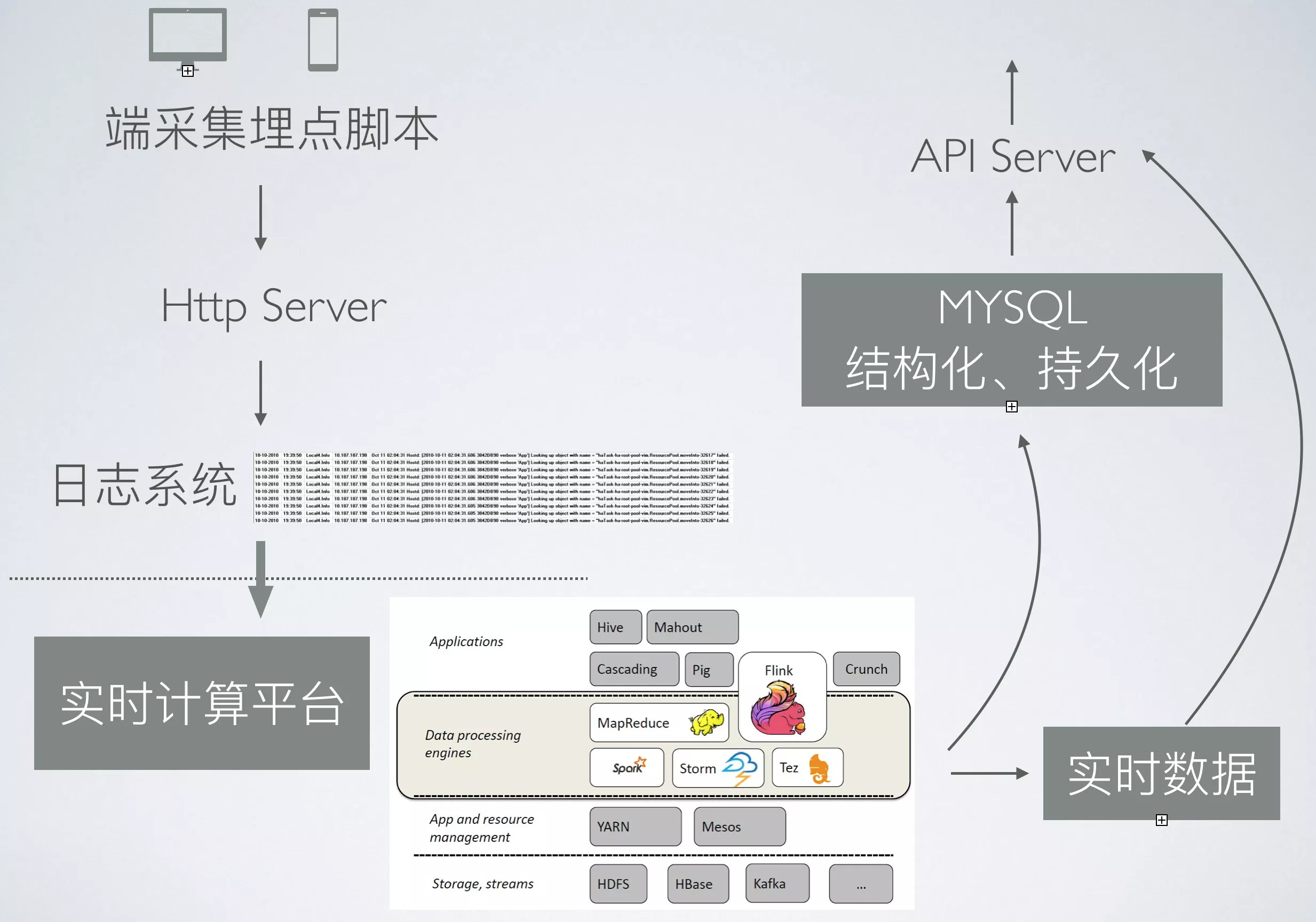
上节我们根据浏览器渲染页面的流程梳理了前端开发中常用的[性能指标和用户体验指标](https://www.fed123.com/pwa/2390.html),同时也基于浏览器的Performance API标准给出了[这些指标的计算方法](https://www.fed123.com/pwa/3301.html)。那么,剩下需要考虑的就是如何搭建这样一个前端性能监控平台的架构,各个环节如何有效运转衔接,如何扩展延伸。最重要的是如何处理数据问题。先放一张整体设计图:
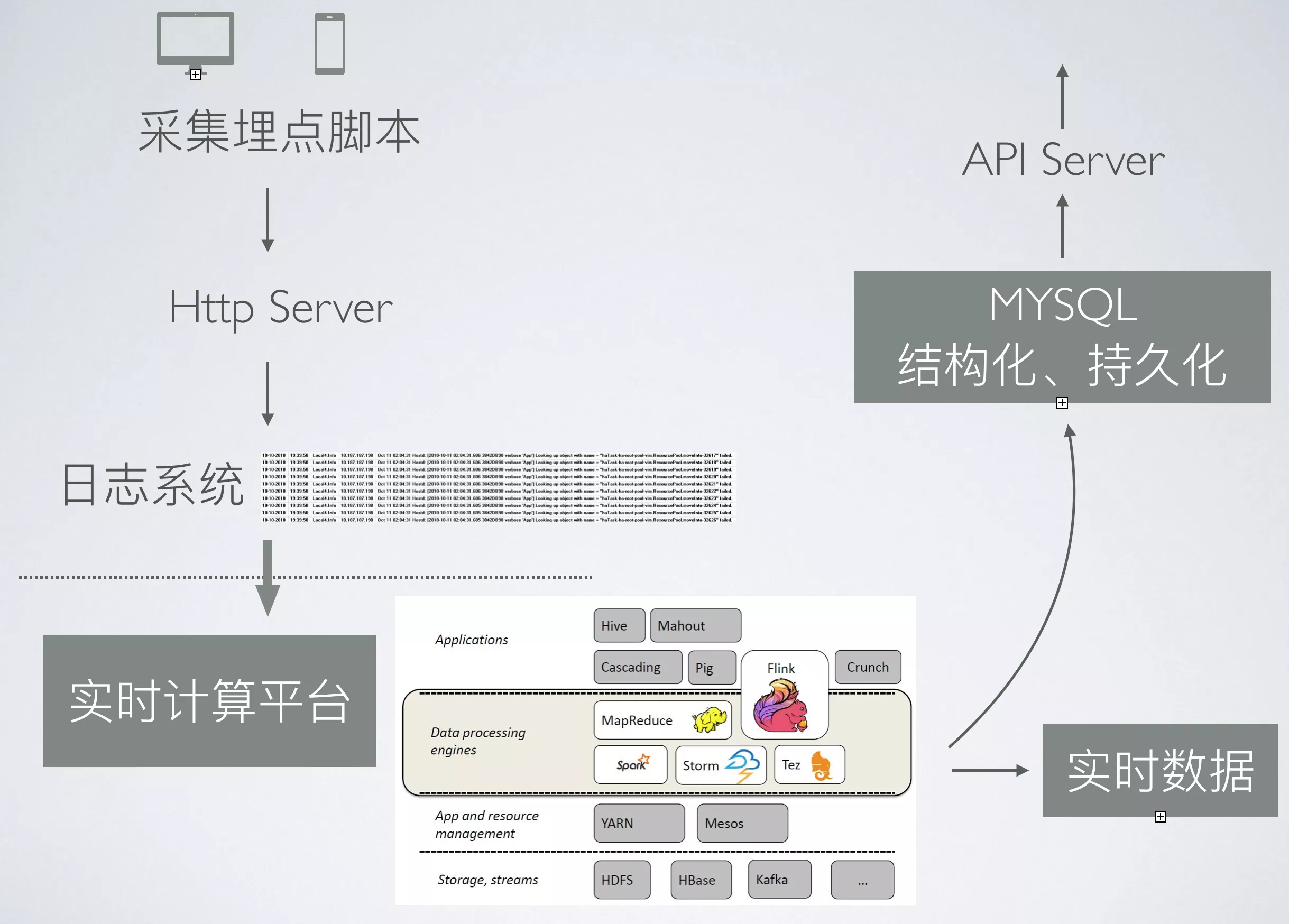
我们来慢慢梳理一下:
## 采集脚本
首先我们有一个指标数据采集的脚本,用于采集各个端的数据,注意需要处理不同端的差异性(比如app内的web view和原生webview差异,不同前端框架可能导致的差异,Android和IOS的差异),同时需要考虑数据采样
* 计算指标
* 端差异化处理
* 采样,前面介绍过了,即使用户量不大,但是叠加上时间维度,最后的数据累积起来也可能超出现有系统的处理能力。最好的方法是做采样。但是要合理选用采样策略,既要保证样本分布均匀,又要保证样本具有代表性。
总结起来,主要是上面三个方面。
## 日志系统
采集脚本采集到数据之后需要上报的,这里我们像开发页面那样简单的调用接口。要知道我们做的是性能监控,不仅随时都会收集数据上报,同时也很可能多端并发,所以一般的接口分分分钟就可能搞挂。所以,业界通用的做法是采用日至系统来承接。
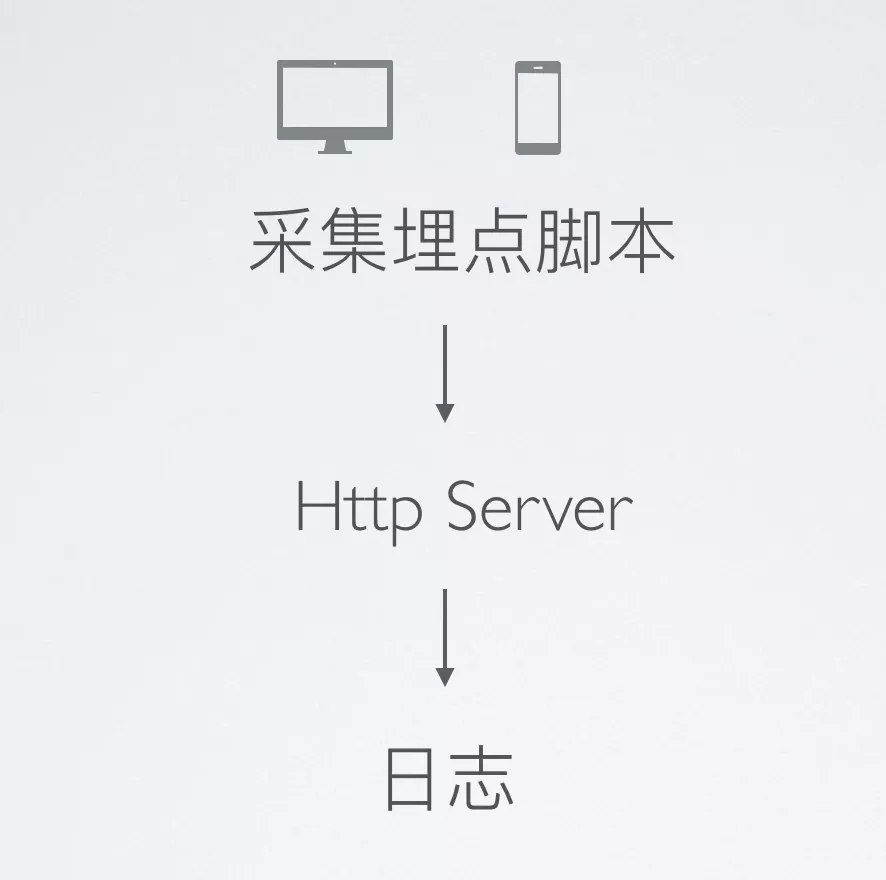
这里主要介绍发送请求和处理请求两部分。
这里主要介绍发送请求和处理请求两部分。
发送请求
像很多这种做网站数据统计的,比如百度统计,CNZZ,google等,他们都是发一个get请求,附带一些数据。而且为了处理跨域问题、提升并发,减少网页消耗,一般做法都是请求一个gif图片地址,在图片的url上带上参数。或者通过JSONP的形式。比如下图:
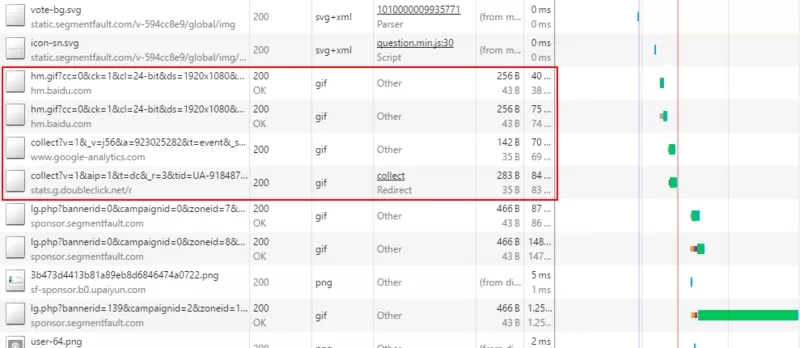
处理请求
处理请求这里其实很简单了,如果你想到的是写后端接口来处理,那么就太复杂了,主要是性能上很难达到高并发的要求。最便宜、最简洁、最通用的方法是让HTTP Server写日志。通常用的Apache或者Nginx都能很简单做到这点,配置一下拦截的url规则和日志规则就可以了。当然日志是默认写入到磁盘的,剩下的就是要保证磁盘容量够大,预算能够放得下多少时间的日志量。

## 实时计算平台
前面介绍过[流计算Flink](https://www.fed123.com/linux/3360.html),这里也就是需要这样的平台来帮我们实时汇总计算数据。
- 第1章 介绍
- 01 介绍与基础要求
- 02 章节内容介绍
- 第2章 性能体验评判模型
- 03 RAIL 评估模型介绍
- 04 RAIL评估模型解析
- 05 加载性能指标
- 06 稳定性和操作体验指标
- 07 Performance High Resolution Time API
- 08 Performance Navigation Timing API
- 09 Performance User Timing API
- 10 Performance Resource Timing 和 Timeline API
- 11 Performance Timing 参数介绍和 FID 指标
- 12 性能和体验指标计算
- 13 页面性能指标数据采集架构
- 第3章 前端网页加载链路优化
- 14 静态资源链路优化
- 15 资源加载过程优化
- 16 浏览器解析渲染过程优化
- 17 Memory/Client/Http/Net/WebViewCache 方案介绍
- 18 Memory/Client/Http/Net/WebViewCache 应用实例
- 19 数据埋点反馈优化和常用软件
- 第4章 前端极致性能体验编码优化
- 20 优化策略和首屏渲染 PRPL 方案
- 21 LazyLoad 懒加载策略与组件案例
- 22 滚动加载分页组件案例
- 23 web worker 思路与方案案例
- 24 task 拆分原理和方案
- 25 代码分割与打包优化
- 26 前端项目架构优化思路与 ES6 原生模块架构案例
- 27 web components 和轻 React 、Vue 和微前端架构思想