
[TOC]
## 1\. 时间效率[¶](https://blog.yorek.xyz/leetcode/code_interviews_5/#1 "Permanent link")
### 1.1 (39)数组中出现次数超过一半的数字[¶](https://blog.yorek.xyz/leetcode/code_interviews_5/#11-39 "Permanent link")
> 数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。例如输入一个长度为9的数组{1, 2, 3, 2, 2, 2, 5, 4, 2}。由于数字2在数组中出现了5次,超过数组长度的一半,因此输出2。
**解法一:基于partition函数的时间复杂度为O(n)的算法**
题目所给数组的特性:数组中有一个数字出现的次数超过了数组长度的一半。如果把这个数组排序,那么排序之后位于数组中间的数字一定就是那个出现次数超过数组长度一半的数字。也就是说,**这个数字是统计学上的中位数**,即长度为n的数组中第n/2大的数字。我们可以使用时间复杂度为O(n)的`partition`算法得到数组中任意第k大的数字。
这种算法受快速排序算法的启发。在随机快速排序算法中,我们先在数组中随机选择一个数字,然后调整数组中数字的顺序,使得比选中的数字小的数字都排在它的左边,比选中的数字大的数字都排在它的右边。如果这个选中的数字的下标刚好是n/2,那么这个数字就是数组的中位数;如果它的下标大于n/2,那么中位数应该位于它的左边,我们可以接着在它的左边部分的数组中查找;如果它的下标小于n/2,那么中位数应该位于它的右边,我们可以接着在它的右边部分的数组中查找。这是一个典型的递归过程。
~~~
private int moreThanHalfNum1(int[] numbers) {
if (numbers == null) {
throw new IllegalArgumentException("numbers不能为空");
}
int middle = numbers.length >> 1;
int start = 0;
int end = numbers.length - 1;
int index = QuickSort.partition(numbers, start, end);
while (index != middle) {
if (index > middle) {
end = index - 1;
index = QuickSort.partition(numbers, start, end);
} else {
start = index + 1;
index = QuickSort.partition(numbers, start, end);
}
}
int result = numbers[middle];
if (!checkMoreThanHalf(numbers, result)) {
throw new IllegalArgumentException("结果不对");
}
return result;
}
~~~
**解法二:根据数组特点找出时间复杂度为O(n)的算法**
接下来我们从另外一个角度来解决这个问题。数组中有一个数字出现的次数超过数组长度的一半,也就是说出现的次数比其他所有数字出现次数的和还要多。因此,我们可以考虑在遍历数组的时候保存两个值:一个是数组中的一个数字;另一个是次数。当我们遍历到下一个数字的时候,如果下一个数字和我们之前保存的数字相同,则次数加1;如果下一个数字和我们之前保存的数字不同,则次数减1。如果次数为零,那么我们需要保存下一个数字,并把次数设为1。由于我们要找的数字出现的次数比其他所有数字出现的次数之和还要多,那么要找的数字肯定是最后一次把次数设为1时对应的数字。
~~~
private int moreThanHalfNum2(int[] numbers) {
if (numbers == null) {
throw new IllegalArgumentException("numbers不能为空");
}
int result = numbers[0];
int cnt = 1;
for (int i = 1; i < numbers.length; i++) {
if (cnt == 0) {
result = numbers[i];
cnt++;
} else if (numbers[i] == result) {
cnt++;
} else {
cnt--;
}
}
if (!checkMoreThanHalf(numbers, result)) {
throw new IllegalArgumentException("结果不对");
}
return result;
}
~~~
解法比较
上述两种算法的时间复杂度都是O(n)。基于partition函数的算法的时间复杂度的分析不是很直观,本书限于篇幅不作详细讨论,感兴趣的读者可以参考《算法导论》等书籍的相关章节。我们注意到,在第一种解法中,需要交换数组中数字的顺序,这就会修改输入的数组。是不是可以修改输入的数组呢?在面试的时候,我们可以和面试官讨论,让他明确需求。如果面试官说不能修改输入的数组,那就只能采用第二种解法了。
另外,此题还可以采用笨方法,使用HashMap保存每个数出现的个数,时间复杂度也是O(n)。
### 1.2 (40)最小的k个数[¶](https://blog.yorek.xyz/leetcode/code_interviews_5/#12-40k "Permanent link")
> 输入n个整数,找出其中最小的k个数。例如输入4、5、1、6、2、7、3、8这8个数字,则最小的4个数字是1、2、3、4。
**解法一:时间复杂度为O(n),但需要修改输入的数组**
我们同样可以基于`partition`函数来解决这个问题。如果基于数组的第k个数字来调整,则使得比第k个数字小的所有数字都位于数组的左边,比第k个数字大的所有数字都位于数组的右边。这样调整之后,位于数组中左边的k个数字就是最小的k个数字(这k个数字不一定是排序的)。下面是基于这种思路的参考代码:
~~~
private int[] getLeastNumbers1(int[] input, int k) {
if (input == null || input.length < k || k <= 0) {
return null;
}
int start = 0;
int end = input.length - 1;
int index = QuickSort.partition(input, start, end);
while (index != k - 1) {
if (index > k - 1) {
end = index - 1;
index = QuickSort.partition(input, start, end);
} else {
start = index + 1;
index = QuickSort.partition(input, start, end);
}
}
int[] result = new int[k];
System.arraycopy(input, 0, result, 0, k);
return result;
}
~~~
**解法二:时间复杂度为O(nlogk)的算法,特别适合处理海量数据**
我们可以先创建一个大小为k的数据容器来存储最小的k个数字,接下来每次从输入的n个整数中读入一个数。如果容器中已有的数字少于k个,则直接把这次读入的整数放入容器之中;如果容器中已有k个数字了,也就是容器已满,此时我们不能再插入新的数字而只能替换已有的数字。找出这已有的k个数中的最大值,然后拿这次待插入的整数和最大值进行比较。如果待插入的值比当前已有的最大值小,则用这个数替换当前已有的最大值;如果待插入的值比当前已有的最大值还要大,那么这个数不可能是最小的k个整数之一,于是我们可以抛弃这个整数。
因此,当容器满了之后,我们要做3件事情:一是在k个整数中找到最大数;二是有可能在这个容器中删除最大数;三是有可能要插入一个新的数字。如果用一棵二叉树来实现这个数据容器,那么我们能在O(logk)时间内实现这3步操作。因此,对于n个输入数字而言,总的时间效率就是O(nlogk)。
我们可以选择用不同的二叉树来实现这个数据容器。由于每次都需要找到k个整数中的最大数字,我们很容易想到用最大堆。在最大堆中,根节点的值总是大于它的子树中任意节点的值。于是我们每次可以在O(1)时间内得到已有的k个数字中的最大值,但需要O(logk)时间完成删除及插入操作。
在Java中可以利用`PriorityQueue`实现最小堆、最大堆。
~~~
// 最小堆
PriorityQueue<Integer> minHeap = new PriorityQueue<Integer>();
// 最大堆
PriorityQueue<Integer> maxHeap = new PriorityQueue<Integer>(n, new Comparator<Integer>(){
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
~~~
算法如下:
~~~
private int[] getLeastNumbers2(int[] input, int k) {
if (input == null || input.length < k || k <= 0) {
return null;
}
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(k, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
for (int number: input) {
if (maxHeap.size() < k) {
maxHeap.offer(number);
} else {
if (number < maxHeap.peek()) {
maxHeap.poll();
maxHeap.add(number);
}
}
}
int[] result = new int[k];
int index = 0;
for (Object number: maxHeap.toArray()) {
result[index++] = (Integer) number;
}
return result;
}
~~~
### 1.3 (41)数据流中的中位数[¶](https://blog.yorek.xyz/leetcode/code_interviews_5/#13-41 "Permanent link")
> 如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。
由于数据是从一个数据流中读出来的,因而数据的数目随着时间的变化而增加。如果用一个数据容器来保存从流中读出来的数据,则当有新的数据从流中读出来时,这些数据就插入数据容器。这个数据容器用什么数据结构定义最合适呢?
数组是最简单的数据容器。如果数组没有排序,则可以用`partition`函数找出数组中的中位数(详见39)。在没有排序的数组中插入一个数字和找出中位数的时间复杂度分别是O(1)和O(n)。
我们还可以在往数组里插入新数据时让数组保持排序。这时由于可能需要移动O(n)个数,因此需要O(n)时间能完成插入操作。在已经排好序的数组中找出中位数是一个简单的操作,只需要O(1)时间即可完成。
排序的链表是另外一种选择。我们需要O(n)时间才能在链表中找到合适的位置插入新的数据。如果定义两个指针指向链表中间的节点(如果链表的节点数目是奇数,那么这两个指针指向同一个节点),那么可以在O(1)时间内得出中位数。此时的时间复杂度与基于排序的数组的时间复杂度一样。
二叉搜索树可以把插入新数据的平均时间降低到O(logn)。但是,当二叉搜索树极度不平衡从而看起来像一个排序的链表时,插入新数据的时间仍然是O(n)。为了得到中位数,可以在二叉树节点中添加一个表示子树节点数目的字段。有了这个字段,可以在平均O(logn)时间内得到中位数,但最差情况仍然需要O(n )时间。
为了避免二叉搜索树的最差情况,还可以利用平衡的二叉搜索树,即AVL树。通常AVL树的平衡因子是左、右子树的高度差。可以稍作修改,把AVL的平衡因子改为左、右子树节点数目之差。有了这个改动,可以用O(logn)时间往AVL树中添加一个新节点,同时用O(1)时间得到所有节点的中位数。
AVL树的时间效率很高,但大部分编程语言的函数库中都没有实现这个数据结构。应聘者在短短几十分钟内实现AVL树的插入操作是非常困难的。所以我们不得不分析还有没有其他方法。
如下图所示,如果数据在容器中已经排序,那么中位数可以由P1和P2指向的数得到。如果容器中数据的数目是奇数,那么P1和P2指向同一个数据。
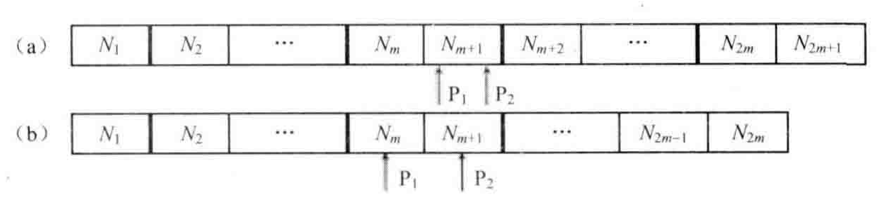
容器中数据被中间的一个或两个数据分隔成为两部分
我们注意到整个数据容器被分隔成两部分。位于容器左边部分的数据比右边的数据小。另外,P1指向的数据是左边部分最大的数,P2指向的数据是左边部分最小的数。
如果能够保证数据容器左边的数据都小于右边的数据,那么即使左、右两边内部的数据没有排序,也可以根左边最大的数及右边最小的数得到中位数。如何快速从一个数据容器中找出最大数?用最大堆实现这个数据容器,因为位于堆顶的就是最大的数据。同样,也可以快速从最小堆中找出最小数。
因此,可以用如下思路来解决这个问题:用一个最大堆实现左边的数据容器,用一个最小堆实现右边的数据容器。往堆中插入一个数据的时间效率是O(logn)。由于只需要O(1)时间就可以得到位于堆顶的数据,因此得到中位数的时间复杂度是O(1)。
下表总结了使用没有排序的数组、排序的数组、排序的链表、二叉搜索树、AVL数、最大堆和最小堆几种不同的数据结构的时间复杂度。
| 数据结构 | 插入的时间复杂度 | 得到中位数的时间复杂度 |
| --- | --- | --- |
| 没有排序的数据 | O(1) | O(n) |
| 排序的数组 | O(n) | O(1) |
| 排序的链表 | O(n) | O(1) |
| 二叉搜索树 | 平均O(logn),最差O(n) | 平均O(logn),最差O(n) |
| AVL树 | O(logn) | O(1) |
| 最大堆和最小堆 | O(logn) | O(1) |
**接下来考虑用最大堆和最小堆实现的一些细节。**
首先要保证数据平均分配到两个堆中,因此两个堆中数据的数目之差不能超过1。为了实现平均分配,可以在数据的总数目是偶数时把新数据插入最小堆,否则插入最大堆。
还要保证最大堆中的所有数据都要小于最小堆中的数据。当数据的总数目是偶数时,按照前面的分配规则会把新的数据插入最小堆。如果此时这个新的数据比最大堆中的一些数据要小,那该怎么办呢?
可以先把这个新的数据插入最大堆,接着把最大堆中最大的数字拿出来插入最小堆。由于最终插入最小堆的数字是原最大堆中最大的数字,这样就保证了最小堆中所有数字都大于最大堆中的数字。
当需要把一个数据插入最大堆,但这个数据小于最小堆里的一些数据时,这个情形和前面类似。
~~~
private PriorityQueue<Double> maxHeap = new PriorityQueue<>(new Comparator<Double>() {
@Override
public int compare(Double o1, Double o2) {
if (o1.equals(o2)) return 0;
else return o2 - o1 > 0 ? 1 : -1;
}
});
private PriorityQueue<Double> minHeap = new PriorityQueue<>();
private void insert(Double num) {
if (((minHeap.size() + maxHeap.size()) & 1) == 0) {
if (maxHeap.size() > 0 && num < maxHeap.peek()) {
maxHeap.offer(num);
num = maxHeap.poll();
}
minHeap.offer(num);
} else {
if (minHeap.size() > 0 && num > minHeap.peek()) {
minHeap.offer(num);
num = minHeap.poll();
}
maxHeap.offer(num);
}
}
private double getMedian() {
int size = maxHeap.size() + minHeap.size();
if (size == 0) {
throw new IllegalStateException("No numbers are available");
}
double median;
if ((size & 1) == 1) {
median = minHeap.peek();
} else {
median = (minHeap.peek() + maxHeap.peek()) / 2;
}
return median;
}
~~~
### 1.4 (42)连续子数组的最大和[¶](https://blog.yorek.xyz/leetcode/code_interviews_5/#14-42 "Permanent link")
> 输入一个整型数组,数组里有正数也有负数。数组中一个或连续的多个整数组成一个子数组。求所有子数组的和的最大值。要求时间复杂度为O(n)。
例如,输入的数组为{1,-2,3,10,-4,7,2,5},和最大的子数组为{3,10,-4,7,2},因此输出为该子数组的和18。
此题同[LC-53-Maximum Subarray](https://blog.yorek.xyz/leetcode/leetcode51-60/#53-maximum-subarray)
**解法一:举例分析数组的规律**
在分析上面例子的过程中,我们发现如果某步累加的结果不是正数,那么这些累加是可以抛弃的;否则可正常进行累加。在每步累加结束后存下这步最大的值。
~~~
private int findGreatestSumOfSubArray(int[] data) {
if (data == null || data.length == 0) {
throw new IllegalArgumentException("data is empty");
}
int currentSum = 0;
int result = Integer.MIN_VALUE;
for (int num: data) {
if (currentSum <= 0)
currentSum = num;
else
currentSum += num;
if (currentSum > result)
result = currentSum;
}
return result;
}
~~~
**解法二:应用动态规划法**
如果算法的功底足够扎实,那么我们还可以用动态规划的思想来分析这个问题。如果用函数f(i)表示以第i个数字结尾的子数组的最大和,那么我们需要求出max\[f(i)\],其中0≤i<n。我们可用如下递归公式求f(i):
f(i)=\\begin{cases} data\[i\] & i=0或者f(i-1) \\leq 0 \\\\ f(i-1)+data\[i\] & i \\ne 0并且f(i-1)>0 \\end{cases}
这个公式的意义:当以第i-1个数字结尾的子数组中所有数字的和小于0时,如果把这个负数与第i个数累加,则得到的结果比第i个数字本身还要小,所以这种情况下以第i个数字结尾的子数组就是第i个数字本身。如果以第i-1个数字结尾的子数组中所有数字的和大于0,则与第i个数字累加就得到以第i个数字结尾的子数组中所有数字的和。
虽然通常我们用递归的方式分析动态规划的问题,但最终都会基于循环去编码。上述公式对应的代码和前面给出的代码一致。递归公式中的f(i)对应的变量是currentSum,而max\[f(i)\]就是result。因此,可以说这两种思路是异曲同工的。
### 1.5 (43)从1到n整数中1出现的次数[¶](https://blog.yorek.xyz/leetcode/code_interviews_5/#15-431n1 "Permanent link")
> 输入一个整数n,求从1到n这n个整数的十进制表示中1出现的次数。例如输入12,从1到12这些整数中包含1的数字有1、10、11和12,1一共出现了5次。
**不考虑时间效率的解法,不推荐**
最直观的方法,也就是累加1~n中每个整数1出现的次数。我们可以每次通过对10求余树判断整数的个位数字是不是1。如果这个数大于10,则除以10之后再判断个位数字是不是1。
如果输入数字n,n有O(logn)位,我们需要判断每一位是不是1,那么它的时间复杂度是O(nlogn)。
~~~
private int numberOf1Between1AndN_Solution1(int n) {
if (n <= 0)
return 0;
int number = 0;
for (int i = 1; i <= n; i++) {
number += countNumber(i);
}
return number;
}
private int countNumber(int n) {
int cnt = 0;
while (n != 0) {
if (n % 10 == 1) {
cnt++;
}
n /= 10;
}
return cnt;
}
~~~
**从数字规律着手明显提高时间效率的解法**
如果希望不用计算每个数字的1的个数,那就只能去寻找1在数字中出现的规律了。为了找到规律,我们不妨用一个稍微大一点的数字如21345作为例子来分析。我们把1~21345的所有数字分为两段:一段是1~1345另一段是1346~21345。
我们先看1346~21345中1出现的次数。1的出现分为两种情况。**首先分析1出现在最高位(本例中是万位)的情况**。在1346~21345的数字中,1出现在10000~19999这10000个数字的万位中,一共出现了10000(10^4)次。
值得注意的是,并不是对所有5位数而言在万位出现的次数都是10000次。对于万位是1的数字如输入12345,1只出现在10000~12345的万位,出现的次数不是10^4次,而是2346次,也就是除去最高数字之后剩下的数字再加上1(2345+1=2346次)。
**接下来分析1出现在除最高位之外的其他4位数中的情况**。例子中1346~21345这20000个数字中后4位中1出现的次数是8000次。由于最高位是2,我们可以再把1346~21345分成两段:1346~11345和11346~21345。每一段剩下的4位数字中,选择其中一位是1,其余三位可以在0~9这10个数字中任意选择,因此根据排列组合原则,总共出现的次数是2×4×10^3=8000次。
**至于在1~1345中1出现的次数**,我们就可以用递归求得了。这也是我们为什么要把1~21345分成1~134和1346~21345两段的原因。因为把21345的最高位去掉就变成1345,便于我们采用递归的思路。
这种思路是每次去掉最高位进行递归递归的次数和位数相同。一个数字n有O(logn)位,因此这种思路的时间复杂度是O(logn),比前面的原始方法要好很多。
~~~
private int numberOf1Between1AndN_Solution2(int n) {
if (n <= 0)
return 0;
char[] strN = String.valueOf(n).toCharArray();
return numberOf1(strN, 0);
}
private int numberOf1(char[] str, int begin) {
if (str == null || str.length <= begin || str[begin] < '0' || str[begin] > '9') {
return 0;
}
int first = str[begin] - '0';
int length = str.length - begin;
if (length == 1 && first == 0)
return 0;
if (length == 1 && first > 0)
return 1;
// 最高位为1的情况
int numberFirstDigit = 0;
if (first > 1)
numberFirstDigit = (int) Math.pow(10, length - 1);
else if (first == 1)
numberFirstDigit = Integer.parseInt(new String(str, begin + 1, length - 1)) + 1;
// 其他位置为1的情况
int numOtherDigit = first * (length - 1) * (int) Math.pow(10, length - 2);
// 递归部分
int numRecursive = numberOf1(str, begin + 1);
return numberFirstDigit + numOtherDigit + numRecursive;
}
~~~
### 1.6 (44)数字序列中某一位的数字[¶](https://blog.yorek.xyz/leetcode/code_interviews_5/#16-44 "Permanent link")
> 数字以0123456789101112131415…的格式序列化到一个字符序列中。在这个序列中,第5位(从0开始计数)是5,第13位是1,第19位是4,等等。请写一个函数求任意位对应的数字。
*题目意思是将从0至正无穷的整数依次排列到一个字符串中,求这个字符串的第n位是什么数字。*
我们用一个具体的例子来分析如何解决这个问题。比如,序列的第1001位是什么?
序列的前10位是0~9这10个只有一位的数字。显然第1001位在这10个数字之后,因此这10个数字可以直接跳过。我们再从后面紧跟着的序列中找第991(991=1001-10)位的数字。
接下来180位数字是90个10~99的两位数。由于991>180,所以第991位在所有的两位数之后。我们再跳过90个两位数,继续从后面找881(881=991-180)位。
接下来的2700位是900个100~999的三位数。由于811<2700,所以第811位是某个三位数中的一位。由于811=270×3+1,这意味着第811位是从100开始的第270个数字即370的中间一位,也就是7。
算法如下:
~~~
private int digitAtIndex(int index) {
if (index < 0)
return -1;
int digits = 1;
while (true) {
int numbers = countOfIntegers(digits);
if (index < numbers * digits)
return digitAtIndex(index, digits);
index -= digits * numbers;
digits++;
}
}
/**
* digits位数的数字总共有多少个
* 2(10~99) -> 90
* 3(100~999) -> 900
*/
private int countOfIntegers(int digits) {
if (digits == 1)
return 10;
int count = (int) Math.pow(10, digits - 1);
return 9 * count;
}
/**
* 要找的数在digits位数中的位置
*/
private int digitAtIndex(int index, int digits) {
// 先获取到所求位置对应的整数
int number = beginNumber(digits) + index / digits;
// 计算所求位置是整数的第几位
int indexFromRight = digits - index % digits;
// 获取对应位置的数字
for (int i = 1; i < indexFromRight; i++)
number /= 10;
return number % 10;
}
/**
* digits位数的第一个数字
*/
private int beginNumber(int digits) {
if (digits == 1) return 0;
return (int) Math.pow(10, digits - 1);
}
~~~
### 1.7 (45)把数组排成最小的数[¶](https://blog.yorek.xyz/leetcode/code_interviews_5/#17-45 "Permanent link")
> 输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。例如输入数组{3, 32, 321},则打印出这3个数字能排成的最小数字321323。
这道题最直接的解法应该是先求出这个数组中所有数字的全排列,然后把每个排列拼起来,最后求出拼起来的数字的最小值。求数组的排列和第38题“字符串的排列”非常类似,这里不再详细介绍。根据排列组合的知识,n个数字总共有n!个排列。我们再来看一种更快的算法。
这道题其实是希望我们能找到一个排序规则,数组根据这个规则排序之后能排成一个最小的数字。要确定排序规则,就要比较两个数字,也就是给出两个数字m和n,我们需要确定一个规则判断m和n哪个应该排在前面,而不是仅仅比较这两个数字的值哪个更大。
根据题目的要求,两个数字m和n能拼接成数字mn和nm。如果mn”及“=”表示常规意义的数值的大小关系,而文字“大于”、“小于”、“等于”表示我们新定义的大小关系。
接下来考虑怎么去拼接数字,即给出数字m和n,怎么得到数字mn和nm并比较它们的大小。直接用数值去计算不难办到,但需要考虑的一个潜在问题就是m和n都在int型能表达的范围内,但把它们拼接起来的数字mn和nm用int型表示就有可能溢出了,**所以这还是一个隐形的大数问题**。
一个非常直观的解决大数问题的方法就是把数字转换成字符串。另外,由于把数字m和n拼接起来得到mn和nm,它们的位数肯定是相同的,因此比较它们的大小只需要按照字符串大小的比较规则就可以了。
~~~
private void printMinNumber(int[] numbers) {
if (numbers == null || numbers.length == 0) {
return;
}
final int n = numbers.length;
String[] strNumbers = new String[n];
for (int i = 0; i < n; i++)
strNumbers[i] = String.valueOf(numbers[i]);
Arrays.sort(strNumbers, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
String str1 = o1 + o2;
String str2 = o2 + o1;
return str1.compareTo(str2);
}
});
for (String str: strNumbers)
System.out.printf("%s", str);
System.out.println();
}
~~~
在上述代码中,我们先把数组中的整数通过`String.valueOf(int)`转换成字符串,然后在调用`Arrays.sort(T[], Comparator<? super T>)`排序,最后把排好序的数组中的数字依次打印出来,就是该数组中数字能拼接出来的最小数字。这种思路的时间复杂度和快速排序的时间复杂度相同,也就是O(nlogn),这比用n!的时间求出所有排列的思路要好很多。
在上述思路中,我们定义了一种新的比较两个数字大小的规则,这种规则是不是有效的?另外,我们只是定义了比较两个数字大小的规则,却用它来排序一个含有多个数字的数组,最终拼接数组中的所有数字得到的是不是真的就是最小的数字?一些严格的面试官还会要求我们给出严格的数学证明,以确保我们的解决方案是正确的。
我们首先证明之前定义的比较两个数字大小的规则是有效的。一个有效的比较规则需要3个条件:自反性、对称性和传递性。我们分别予以证明。
1. 自反性:显然有aa=aa,所以a等于a。
2. 对称性:如果a小于b,则abab,因此b大于a。
3. 传递性:如果a小于b,则ab<ba。假设a和b用十进制表示时分别有l位和m位,于是ab=a\\times10^m+b,ba=b\\times10^l+a。
ab<ba→a\\times10^m+b<b\\times10^l+a→a\\times10^m-a<b\\times10^l-b→
a(10^m-1)<b(10^l-1)→a/(10^l-1)<b/(10^m-1)
同理,如果b小于c,则bc<cb。假设c用十进制表示时有n位,和前面的证明过程一样,可以得到b/(10^m-1)<c/(10^n-1)。
a/(10^l-1)<b/(10^m-1) 且 b/(10^m-1)<c/(10^n-1)→\\\\a/(10^l-1)<c/(10^n-1)→a(10^n-1)<c(10^l-1)→
a\\times10^n+c<c\\times10^l+a→ac<ca→a<c
于是我们证明了这种比较规则满足自反性、对称性和传递性,是一种有效的比较规则。接下来我们证明根据这种比较规则把数组排序之后,把数组中的所有数字拼接起来得到的数字的确是最小的。直接证明不是很容易,我们不妨用反证法来证明。
我们把n个数按照前面的排序规则排序之后,表示为A\_1A\_2A\_3 \\ldots A\_n。假设这样拼接出来的数字并不是最小的,即至少存在两个x和y(0<x<y<n),交换第x个数和第y个数后,A\_1A\_2 \\ldots A\_y \\ldots A\_x \\ldots A\_n<A\_1A\_2 \\ldots A\_x \\ldots A\_y \\ldots A\_n。
由于A\_1A\_2 \\ldots A\_x \\ldots A\_y \\ldots A\_n是按照前面的规则排好的序列,所以有A\_x小于A\_{x+1}小于A\_{x+2}\\ldots 小于A\_{y-2}小于A\_{y-1}小于A\_y。
由于A\_{y-1}小于A\_y,所以A\_{y-1}A\_y<A\_yA\_{y-1}。我们在序列A\_1A\_2 \\ldots A\_x \\ldots A\_{y-1}A\_y \\ldots A\_n中交换A\_{y-1}和A\_y,有A\_1A\_2 \\ldots A\_x \\ldots A\_{y-1}A\_y \\ldots A\_n<A\_1A\_2 \\ldots A\_x \\ldots A\_yA\_{y-1} \\ldots A\_n(这个实际上也需要证明,感兴趣的读者可以自己试着证明)。我们就这样一直把A\_y和前面的数字交换,直到和A\_x交换为止。于是就有
A\_1A\_2 \\ldots A\_x \\ldots A\_{y-1}A\_y \\ldots A\_n<A\_1A\_2 \\ldots A\_x \\ldots A\_yA\_{y-1} \\ldots A\_n< \\\\ A\_1A\_2 \\ldots A\_x \\ldots A\_yA\_{y-2}A\_{y-1} \\ldots A\_n< \\ldots <A\_1A\_2 \\ldots A\_yA\_x \\ldots A\_{y-2}A\_{y-1} \\ldots A\_n
同理,由于A\_x小于A\_{x+1},所以A\_xA\_{x+1}<A\_{x+1}A\_x。我们在序列A\_1A\_2 \\ldots A\_yA\_xA\_{x+1} \\ldots A\_{y-2}A\_{y-1} \\ldots A\_n中只交换A\_x和A\_{x+1},有A\_1A\_2 \\ldots A\_yA\_xA\_{x+1} \\ldots A\_{y-2}A\_{y-1} \\ldots An<A\_1A\_2 \\ldots A\_yA\_{x+1}A\_x \\ldots A\_{y-2}A\_{y-1} \\ldots An。接下来一直拿A\_x和它后面的数字交换,直到和A\_{y-1}交换为止。于是就有
A\_1A\_2 \\ldots A\_yA\_xA\_{x+1} \\ldots A\_{y-2}A\_{y-1} \\ldots An<A\_1A\_2 \\ldots A\_yA\_{x+1}A\_x \\ldots A\_{y-2}A\_{y-1} \\ldots An<\\\\ \\ldots <A\_1A\_2 \\ldots A\_yA\_{x+1}A\_{x+2} \\ldots A\_{y-2}A\_{y-1}A\_x \\ldots A\_n。
所以A\_1A\_2 \\ldots A\_x \\ldots A\_y \\ldots A\_n<A\_1A\_2 \\ldots A\_y \\ldots A\_x \\ldots A\_n,这和我们的假设A\_1A\_2 \\ldots A\_y \\ldots A\_x \\ldots A\_n<A\_1A\_2 \\ldots A\_x \\ldots A\_y \\ldots A\_n相矛盾。
所以假设不成立,我们的算法是正确的。
### 1.8 (46)把数字翻译成字符串[¶](https://blog.yorek.xyz/leetcode/code_interviews_5/#18-46 "Permanent link")
> 给定一个数字,我们按照如下规则把它翻译为字符串:0翻译成"a",1翻译成"b",……,11翻译成"l",……,25翻译成"z"。一个数字可能有多个翻译。例如12258有5种不同的翻译,它们分别是"bccfi"、"bwfi"、"bczi"、"mcfi"和"mzi"。请编程实现一个函数用来计算一个数字有多少种不同的翻译方法。
我们以12258为例分析如何从数字的第一位开始一步步计算不同翻译方法的数目。我们有两种不同的选择来翻译第一位数字1。第一种选择是数字1单独翻译成“b”,后面剩下数字2258;第二种选择是1和紧挨着的2一起翻译成“m”,后面剩下数字258。
当最开始的一个或者两个数字被翻译成一个字符之后,我们接着翻译后面剩下的数字。显然,我们可以写个递归函数来计算翻译的数目。
我们定义函数f(i)表示从第i位数字开始的不同翻译的数目,那么f(i)=f(i+1)+g(i,i+1) \\times f(i+2)。当第i位和第i+1位两位数字拼接起来的数字在10~25的范围内时,函数g(i, i+1)的值为1;否则为0。
尽管我们用递归的思路来分析这个问题,但由于存在重复的子问题,递归并不是解决这个问题的最佳方法。还是以12258为例。如前所述,翻译12258可以分解成两个子问题:翻译1和2258,以及翻译12和258。接下来我们翻译第一个子问题中剩下的2258,同样也可以分解成两个自问题:翻译2和258,以及翻译22和58。注意到子问题翻译258重复出现了。
**递归从最大的问题开始自上而下解决问题。我们也可以从最小的子问题开始自下而上解决问题,这样就可以消除重复的子问题**。 也就是说,我们从数字的末尾开始,然后从右到左翻译并计算不同翻译的数目。
~~~
private int getTranslationCount(int number) {
if (number < 0)
return 0;
return getTranslationCount(String.valueOf(number).toCharArray());
}
private int getTranslationCount(char[] number) {
int length = number.length;
int[] counts = new int[length];
int count;
for (int i = length - 1; i >= 0; i--) {
if (i < length - 1)
count = counts[i + 1];
else
count = 1;
if (i < length - 1) {
int digit1 = number[i] - '0';
int digit2 = number[i + 1] - '0';
int converted = digit1 * 10 + digit2;
if (converted >= 10 && converted <= 25) {
if (i < length - 2)
count += counts[i + 2];
else
count++;
}
}
counts[i] = count;
}
count = counts[0];
return count;
}
~~~
### 1.9 (47)礼物的最大价值[¶](https://blog.yorek.xyz/leetcode/code_interviews_5/#19-47 "Permanent link")
> 在一个m×n的棋盘的每一格都放有一个礼物,每个礼物都有一定的价值(价值大于0)。你可以从棋盘的左上角开始拿格子里的礼物,并每次向左或者向下移动一格直到到达棋盘的右下角。给定一个棋盘及其上面的礼物,请计算你最多能拿到多少价值的礼物?
[LC-64-Minimum Path Sum](https://blog.yorek.xyz/leetcode/leetcode61-70/#64-minimum-path-sum)
例如,在下面的棋盘中,如果沿着带下画线的数字的线路(1、12、5、7、7、16、5),那么我们能拿到最大价值为53的礼物。

这是一个典型的能用动态规划解决的问题。我们先用递归的思路来分析。我们先定义第一个函数f(i,j)表示到达坐标为(i,j)的格子时能拿到的礼物总和的最大值。根据题目要求,我们有两种可能的途径到达坐标为(i,j)的格 子:通过格子(i-1,j)或者(i,j-1).所以f(i,j)\=max(f(i-1,j),f(i,j-1))+gift\[i,j\]。gift\[i,j\]表示坐标为(i,j)的格子里礼物的价值。
尽管我们用递归来分析问题,但由于有大量重复的计算,导致递归的代码并不是最优的。相对而言,基于循环的代码效率要高很多。为了缓存中间计算结果,我们需要一个辅助的二维数组。数组中坐标为(i,j)的元素表示到达坐标为(i,j)的格子时能拿到的礼物价值总和的最大值。
~~~
int getMaxValue_solution1(int[][] values, int rows, int cols) {
if (values == null || rows <= 0 || cols <= 0)
return 0;
int[][] maxValues = new int[rows][cols];
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
int up = 0;
int left = 0;
if (i > 0)
up = maxValues[i - 1][j];
if (j > 0)
left = maxValues[i][j - 1];
maxValues[i][j] = Math.max(up, left) + values[i][j];
}
}
return maxValues[rows - 1][cols - 1];
}
~~~
接下来我们考虑进一步的优化。前面我们提到,到达坐标为(i,j)的格子时能够拿到的礼物的最大价值只依赖坐标为(i-1,j)和(i,j-1)的两个格子,因此第i-2行及更上面的所有格子礼物的最大价值实际上没有必要保存下来。我们可以用一个一维数组来替代前面代码中的二维矩阵maxValues。该一维数组的长度为棋盘的列数n。当我们计算到达坐标为(i,j)的格子时能够拿到的礼物的最大价值f(i,j),数组中前j个数字分别是f(i,0),f(i,1), \\ldots ,f(i,j-1),数组从下标为j的数字开始到最后一个数字,分别为f(i-1,j),f(i-1,j+1), \\ldots ,f(i-1,n-1)。也就是说,该数组前面j个数字分别是当前第i行前面j个格子礼物的最大价值,而之后的数字分别保存前面第i-1行n-j个格子礼物的最大价值。
~~~
int getMaxValue_solution2(int[][] values, int rows, int cols) {
if (values == null || rows <= 0 || cols <= 0)
return 0;
int[] maxValues = new int[cols];
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
int up = 0, left = 0;
if (i > 0)
up = maxValues[j];
if (j > 0)
left = maxValues[j - 1];
maxValues[j] = Math.max(up, left) + values[i][j];
}
}
return maxValues[cols - 1];
}
~~~
### 1.10 (48)最长不含重复字符的子字符串[¶](https://blog.yorek.xyz/leetcode/code_interviews_5/#110-48 "Permanent link")
> 请从字符串中找出一个最长的不包含重复字符的子字符串,计算该最长子字符串的长度。假设字符串中只包含从'a'到'z'的字符。
此题同[LC-3-Longest Substring Without Repeating Characters](https://blog.yorek.xyz/leetcode/leetcode1-10/#3-longest-substring-without-repeating-characters)
直接上对应代码
~~~
private int longestSubstringWithoutDuplication(String str) {
if (str == null || str.length() == 0) {
return 0;
}
final int n = str.length();
Set<Character> set = new HashSet<>();
int ans = 0, i = 0, j = 0;
while (i < n && j < n) {
// try to extend the range [i, j]
if (!set.contains(str.charAt(j))){
set.add(str.charAt(j++));
ans = Math.max(ans, j - i);
}
else {
set.remove(str.charAt(i++));
}
}
return ans;
}
~~~
## 2\. 时间效率与空间效率的平衡[¶](https://blog.yorek.xyz/leetcode/code_interviews_5/#2 "Permanent link")
硬件的发展一直遵循摩尔定律,内存的容量基本上每隔18个月就会翻一番。由于内存的容量增加迅速,在软件开发的过程中我们允许以牺牲一定的空间为代价来优化时间性能,以尽可能地缩短软件的响应时间。这就是我们通常所说的“以空间换时间”。
在面试的时候,如果我们分配少量的辅助空间来保存计算的中间结果以提高时间效率,则通常是可以被接受的。本书中收集的面试题中有不少这种类型的题目,比如在面试题49“丑数”中用一个数组按照从小到大的顺序保存已经求出的丑数;在面试题60“n个骰子的点数”中交替使用两个数组求骰子每个点数出现的次数。
值得注意的是,“以空间换时间”的策略并不一定都是可行的,在面试的时候要具体问题具体分析。我们都知道在n个无序的元素里执行查找操作,需要O(n)的时间。但如果我们把这些元素放进一个哈希表,那么在哈希表内就能实现时间复杂度为O(1)的查找。但同时实现一个哈希表是有空间消耗的,是不是值得以多消耗空间为前提来换取时间性能的提升,我们需要根据实际情况仔细权衡。在面试题50“第一个只出现一次的字符”中,我们用数组实现了一个简易哈希表,有了这个哈希表就能实现在O(1)时间内查找任意字符。对于ASCI码的字符而言,总共只有256个字符,因此只需要1KB的辅助内存。这点内存消耗对于绝大多数硬件来说是完全可以接受的。但如果是16位的 Unicode的字符,创建这样一个长度为216的整型数组需要4×216也就是256KB的内存。这对于个人计算机来说也是可以接受的,但对于一些嵌入式的开发就要慎重了。
很多时候时间效率和空间效率存在类似于鱼与熊掌的关系,我们需要在它们之间有所取舍。在面试的时候究竟是“以时间换空间”还是“以空间换时间”,我们可以和面试官进行探讨。多和面试官进行这方面的讨论是很有必要的,这既能显示我们的沟通能力,又能展示我们对软件性能全方位的把握能力。
### 2.1 (49)丑数[¶](https://blog.yorek.xyz/leetcode/code_interviews_5/#21-49 "Permanent link")
> 我们把只包含因子2、3和5的数称作丑数(Ugly Number)。求按从小到大的顺序的第1500个丑数。例如6、8都是丑数,但14不是,因为它包含因子7。习惯上我们把1当做第一个丑数。
**逐个判断每个整数是不是丑数的解法,直观但不够高效**
所谓一个数m是另一个数n的因子,是指n能被m整除,也就是n%m=0。根据丑数的定义,丑数只能被2、3和5整除。也就是说,如果一个数能被2整除,就连续除以2;如果能被3整除,就连续除以3;如果能被5整除,就除以连续5。如果最后得到的1,那么这个数就是丑数;否则不是。
我们可以得到下面的代码:
~~~
private int getUglyNumber1(int number) {
if (number <= 0)
return 0;
int cnt = 0;
int index = 0;
while (cnt < number) {
index++;
if (isUgly(index)) {
cnt++;
}
}
return index;
}
private boolean isUgly(int number) {
while (number % 2 == 0)
number /= 2;
while (number % 3 == 0)
number /= 3;
while (number % 5 == 0)
number /= 5;
return number == 1;
}
~~~
**创建数组保存已经找到的丑数,用空间换时间的解法**
前面的算法之所以效率低,很大程度上是因为不管一个数是不是丑数,我们都要对它进行计算。接下来我们试着找到一种只计算丑数的方法,而不在非丑数的整数上花费时间。**根据丑数的定义,丑数应该是另一个丑数乘以2、3或者5的结果(1除外)**。因此,我们可以创建一个数组,里面的数字是排好序的丑数,每个丑数都是前面的丑数乘以2、3或者5得到的。
这种思路的关键在于怎样确保数组里面的丑数是排好序的。假设数组中已经有若干个排好序的丑数,并且把已有最大的丑数记作M,接下来分析如何生成下一个丑数。该丑数肯定是前面某一个丑数乘以2、3或者5的结果,所以我们首先考虑把已有的每个丑数乘以2。在乘以2的时候,能得到若干个小于或等于M的结果。由于是按照顺序生成的,小于或者等于M肯定已经在数组中了,我们不需再次考虑;还会得到若干个大于M的结果,但我们只需要第一个大于M的结果,因为我们希望丑数是按从小到大的顺序生成的,其他更大的结果以后再说。我们把得到的第一个乘以2后大于M的结果记为M\_2。同样,我们把已有的每个丑数乘以3和5,能得到第一个大于M的结果M\_3和M\_5。那么下一个丑数应该是M\_2、M\_3和M\_5这3个数的最小者。
在前面分析的时候提到把已有的每个丑数分别乘以2、3和5事实上这不是必需的,因为已有的丑数是按顺序存放在数组中的。对于乘以2而言,肯定存在某一个丑数T\_2,排在它之前的每个丑数乘以2得到的结果都会小于已有最大的丑数,在它之后的每个丑数乘以2得到的结果都会太大。我们只需记下这个丑数的位置,同时每次生成新的丑数的时候去更新这个T\_2即可。对于乘以3和5而言,也存在同样的T\_3和T\_5。
~~~
private int getUglyNumber2(int number) {
if (number <= 0)
return 0;
int[] uglyNumbers = new int[number];
uglyNumbers[0] = 1;
int nextUglyIndex = 1;
int index2 = 0, index3 = 0, index5 = 0;
while (nextUglyIndex < number) {
int min = min(uglyNumbers[index2] * 2, uglyNumbers[index3] * 3, uglyNumbers[index5] * 5);
uglyNumbers[nextUglyIndex] = min;
while (uglyNumbers[index2] * 2 <= min)
index2++;
while (uglyNumbers[index3] * 3 <= min)
index3++;
while (uglyNumbers[index5] * 5 <= min)
index5++;
nextUglyIndex++;
}
return uglyNumbers[nextUglyIndex - 1];
}
private int min(int a, int b, int c) {
return Math.min(Math.min(a, b), c);
}
~~~
和第一种思路相比,第二种思路不需要在非丑数的整数上进行任何计算,因此时间效率有明显提升。但也需要指出,第二种算法由于需要保存已经生成的丑数,则因此需要一个数组,从而增加了空间消耗。如果是求第1500个丑数,则将创建一个能容纳1500个丑数的数组,这个数组占据6KB的内容空间。而第一种思路没有这样的内存开销。总的来说,第二种思路相当于用较小的空间消耗换取了时间效率的提升。
### 2.2 (50)第一个只出现一次的字符[¶](https://blog.yorek.xyz/leetcode/code_interviews_5/#22-50 "Permanent link")
#### 2.2.1 字符串中第一个只出现一次的字符[¶](https://blog.yorek.xyz/leetcode/code_interviews_5/#221 "Permanent link")
> 在字符串中找出第一个只出现一次的字符。如输入"abaccdeff",则输出'b'。
由于题目与字符出现的次数相关,那么我们是不是可以统计每个字符在该字符串中出现的次数?要达到这个目的,我们需要一个数据容器来存放每个字符的出现次数。在这个数据容器中,可以根据字符来查找它出现的次数,也就是说这个容器的作用是把一个字符映射成一个数字。在常用的数据容器中,哈希表正是这个用途。
为了解决这个问题,我们可以定义哈希表的键值(key)是字符,而值(value)是该字符出现的次数。同时我们还需要从头开始扫描字符串两次。第一次扫描字符串时,每扫描到一个字符,就在哈希表的对应项中把次数加1。接下来第二次扫描时,每扫描到一个字符,就能从哈希表中得到该字符出现的次数。这样,第一个只出现一次的字符就是符合要求的输出。
由于本题的特殊性,我们其实只需要一个非常简单的哈希表就能满足要求,因此我们可以考虑实现一个简单的哈希表。字符(char)是一个长度为8的数据类型,因此总共有256种可能。于是我们创建一个长度为256的数组,每个字母根据其ASCII码值作为数组的下标对应数组的一个数字,而数组中存储的是每个字符出现的次数。这样我们就创建了一个大小为256、以字符ASCII码为键值的哈希表。
第一次扫描时,在哈希表中更新一个字符出现的次数的时间是O(1)。如果字符串长度为n,那么第一次扫描的时间复杂度是O(n)。第二次扫描时,同样在O(1)时间内能读出一个字符出现的次数,所以时间复杂度仍然是O(n)。这样算起来,总的时间复杂度是O(n)。同时,我们需要一个包含256个字符的辅助数组,它的大小是1KB由于这个数组的大小是一个常数,因此可以认为这种算法的空间复杂度是O(1)。
Warning
**注意**:本书原版是C语言编写的,char在Java中占用两个byte,共16个bit。
下面的解法要求每个字符都是小写字母,如果出现其他字符那么该解法不适用。可以将n设置成2^16或者使用完整的哈希表代替自己实现的简单哈希表。
~~~
private char firstNotRepeatingChar(String str) {
if (str == null || str.length() == 0) {
return ' ';
}
final int n = 26;
int[] hashTable = new int[n];
for (int i = 0; i < str.length(); i++) {
char ch = str.charAt(i);
hashTable[ch - 'a']++;
}
for (int i = 0; i < str.length(); i++) {
char ch = str.charAt(i);
if (hashTable[ch - 'a'] == 1) {
return ch;
}
}
return ' ';
}
~~~
本题扩展
在前面的例子中,我们之所以可以把哈希表的大小设为256,是因为字符(char)是8bit的类型,总共只有256个字符。但实际上字符不只是256个,比如中文就有几千个汉字。如果题目要求考虑汉字,那么前面的算法是不是有问题?如果有,则可以怎么解决?
*在Java中汉字也可以使用char表示,此时将n设置成2^16或者使用完整的哈希表代替自己实现的简单哈希表都可以。如果加大n,在映射时直接使用hashTable\[ch\]即可。*
相关题目
定义一个函数,输入两个字符串,从第一个字符串中删除在第二个字符串中出现过的所有字符。例如,从第一个字符串"We are student."中删除在第二个字符串"saeiou"出现过的字符得到的结果是"Wr Stdnts."。
*为了解决这个问题,我们可以创建一个用数组实现的简单哈希表来存储第二个字符串。这样我们从头到尾扫描第一个字符串的每个字符时,用O(1)时间就能判断出该字符是不是在第二个字符串中。如果第一个字符串的长度是n,那么总的时间复杂度是O(n)。*
相关题目
定义一个函数,删除字符串中所有重复出现的字符。例如,输入"google",删除重复的字符之后的结果是"gole"。
*这道题目和上面的问题比较类似,我们可以创建一个用布尔型数组实现的简单的哈希表。数组中的元素的意义是其下标看作ASCII码后对应的字母在字符串中是否已经出现。我们先把数组中所有的元素都设为false。以"google"为例,当扫描到第一个g时,g的ASCII码是103,那么我们把数组中下标为103的元素设为true。当扫描到第二个g时,我们发现数组中下标为103的元素的值是true,就知道g在前面经出现过。也就是说,我们用O(1)时间就能判断出每个字符是否在前面已经出现过。如果字符串的长度n,那么总的时间复杂度是O(n)。*
相关题目
在英语中,如果两个单词中出现的字母相同,并且每个字母出现的次数也相同,那么这两个单词互为变位词(Anagram)。例如,silent与listen、evil与live等互为变位词。请完成一个函数,判断输入的两个字符串是不是互为变位词。
*我们可以创建一个用数组实现的简单哈希表,用来统计字符串中每个字符出现的次数。当扫描到第一个字符串中的每个字符时,为哈希表对应的项的值增加1。接下来扫描第二个字符串,当扫描到每个字符时,为哈希表对应的项的值减去1。如果扫描完第二个字符串后,哈希表中所有的值都是0,那么这两个字符串就互为变位词。*
举一反三
如果需要判断多个字符是不是在某个字符串里出现过或者统计多个字符在某个字符串中出现的次数,那么我们可以考虑基于数组创建一个简单的哈希表,这样可以用很小的空间消耗换来时间效率的提升。
Java中char与int可以这么互相转换
int i = ch;
char ch = (char) i;
#### 2.2.2 字符流中第一个只出现一次的字符[¶](https://blog.yorek.xyz/leetcode/code_interviews_5/#222 "Permanent link")
> 请实现一个函数用来找出字符流中第一个只出现一次的字符。例如,当从字符流中只读出前两个字符"go"时,第一个只出现一次的字符是'g'。当从该字符流中读出前六个字符"google"时,第一个只出现一次的字符是'l'。
字符只能一个接着一个从字符流中读出来。可以定义一个数据容器来保存字符在字符流中的位置。当一个字符第一次从字符流中读出来时,把它在字符流中的位置保存到数据容器里。当这个字符再次从字符流中读出来时,那么它就不是只出现一次的字符,也就可以被忽略了。这时把它在数据容器里保存的值更新成一个特殊的值(如负数值)。
为了尽可能高效地解决这个问题,需要在O(1)时间内往数据容器里插入一个字符,以及更新一个字符对应的值。受面试题50的启发,这个数据容器可以用哈希表来实现。用字符的ASCII码作为哈希表的键值,而把字符对应的位置作为哈希表的值。实现这种思路的参考代码如下:
~~~
// occurrence[i]: A character with ASCII value i;
// occurrence[i] = -1: The character has not found;
// occurrence[i] = -2: The character has been found for mutlple times
// occurrence[i] >= 0: The character has been found only once
private int[] occurrence;
private int index;
_5002() {
occurrence = new int[256];
Arrays.fill(occurrence, -1);
}
private void insert(char ch) {
int value = occurrence[ch];
if (value == -1) {
occurrence[ch] = index;
} else if (value >= 0)
occurrence[ch] = -2;
index++;
}
private char firstAppearingOnce() {
int minIndex = Integer.MAX_VALUE;
char ch = ' ';
for (int i = 0; i < occurrence.length; i++) {
if (occurrence[i] >= 0 && occurrence[i] < minIndex) {
ch = (char) i;
minIndex = occurrence[i];
}
}
return ch;
}
~~~
在上述代码中,哈希表用数组occurrence实现。数组中的元素 occurrence\[i\]和ASCII码的值为i的字符相对应。最开始的时候,数组中的所有元素都初始化为-1。当一个ASCII码为i的字符第一次从字符流中读出时,occurrence\[i\]的值更新为它在字符流中的位置。当这个字符再次从字符流中读出时(occurrence\[i\]大于或等于0),occurrence\[i\]的值更新为-2。
当我们需要找出到目前为止从字符流里读出的所有字符中第一个不重复的字符时,只需要扫描整个数组,并从中找出最小的大于等于0的值对应的字符即可。这就是函数`firstAppearingOnce`的功能。
### 2.3 (51)数组中的逆序对[¶](https://blog.yorek.xyz/leetcode/code_interviews_5/#23-51 "Permanent link")
> 在数组中的两个数字如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。例如,在数组{7,5,6,4}中,一共存在5个逆序对,分别是(7,6)、(7,5)、(7,4)、(6,4)和(5,4)。
看到这道题目,我们的第一反应是顺序扫描整个数组。每扫描到一个数字,逐个比较该数字和它后面的数字的大小。如果后面的数字比它小,则这两个数字就组成一个逆序对。假设数组中含有n个数字。由于每个数字都要和O(n)个数字进行比较,因此这种算法的时间复杂度是O(n^2)。我们再尝试找找更快的算法。
我们以数组{7,5,6,4}为例来分析统计逆序对的过程。每扫描到一个数字的时候,我们不能拿它和后面的每一个数字进行比较,否则时间复杂度就是O(n^2),因此,我们可以考虑先比较两个相邻的数字。
如下图(a)和(b)所示,我们先把数组分解成两个长度为2的子数组,再把这两个子数组分别拆分成两个长度为1的子数组。接下来一边合并相邻的子数组,一边统计逆序对的数目。在第一对长度为1的子数组{7}、{5}中,7大于5,因此(7, 5)组成一个逆序对。同样,在第二对长度为1的子数组{6}、{4}中,也有逆序对(6,4)。由于我们已经统计了这两对子数组内部的逆序对,因此需要把这两对子数组排序,如图©所示,以免在以后的统计过程中再重复统计。

统计数组{7,5,6,4}中逆序对的过程
接下来我们统计两个长度为2的子数组之间的逆序对。我们在下图中细分上图(d)的合并子数组及统计逆序对的过程。
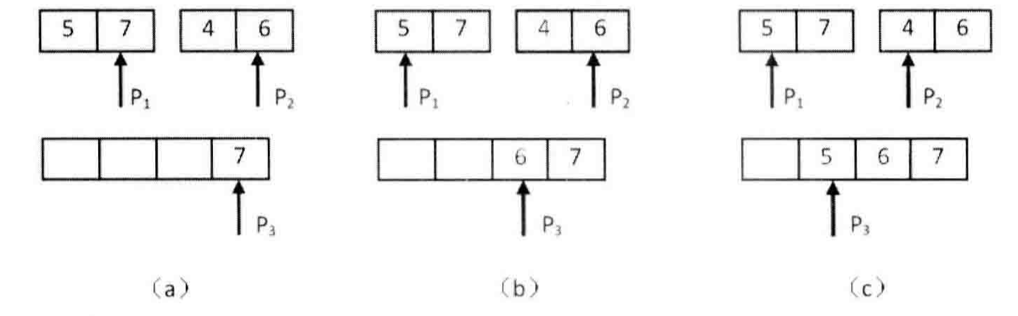
(d)的合并子数组及统计逆序对的过程
*注:图中省略了最后一步,即复制第二个子数组最后剩余的4到辅助数组。*
*a) P1指向的数字大于P2指向的数字表明数组中存在逆序对。P2指向的数字是第二个子数组的第二个数字,因此第二个子数组中有两个数字比7小。把逆序对数目加2,并把7复制到辅助数组,向前移动P1和P3。*
*b) P1指向的数字小于P2指向的数字,没有逆序对。把P2指向的数字复制到辅助数组,并向前移动P2和P3。*
*c) P1指向的数字大于P2指向的数字,因此存在逆序对。由于P2指向的数字是第二个子数组的第一个数字,子数组中只有一个数字比5小。把逆序对数目加1,并把5复制到辅助数组,向前移动P1和P3。*
我们先用两个指针分别指向两个子数组的末尾,并每次比较两个指针指向的数字。如果第一个子数组中的数字大于第二个子数组中的数字,则构成逆序对,并且逆序对的数目等于第二个子数组中剩余数字的个数,如(a)和©所示。如果第一个数组中的数字小于或等于第二个数组中的数字,则不构成逆序对,如图(b)所示。每次比较的时候,我们都把较大的数字从后往前复制到一个辅助数组,确保辅助数组中的数字是递增排序的。在把较大的数字复制到辅助数组之后,把对应的指针向前移动一位,接下来进行下一轮比较。
经过前面详细的讨论,我们可以总结出统计逆序对的过程:先把数组分隔成子数组,统计出子数组内部的逆序对的数目,然后再统计出两个相邻子数组之间的逆序对的数目。在统计逆序对的过程中,还需要对数组进行排序。如果对排序算法很熟悉,那么我们不难发现这个排序的过程实际上就是归并排序。我们可以基于归并排序写出如下代码:
~~~
private int inversePairs(int[] data) {
if (data == null || data.length == 0)
return 0;
final int n = data.length;
int[] copy = new int[n];
System.arraycopy(data, 0, copy, 0, n);
int count = inversePairsCore(data, copy, 0, n - 1);
return count;
}
private int inversePairsCore(int[] data, int[] copy, int start, int end) {
if (start == end) {
copy[start] = data[start];
return 0;
}
int length = (end - start) >> 1;
// copy与data每次都需要交换位置
// 使得每次递归后data的left、right段都是有序的
int left = inversePairsCore(copy, data, start, start + length);
int right = inversePairsCore(copy, data, start + length + 1, end);
// i初始化为前半段最后一个数字的下标
int i = start + length;
// j初始化为后半段最后一个数字的下标
int j = end;
int indexCopy = end;
int count = 0;
while (i >= start && j >= start + length + 1) {
if (data[i] > data[j]) {
copy[indexCopy--] = data[i--];
count += j - start - length;
} else {
copy[indexCopy--] = data[j--];
}
}
for (; i >= start; i--)
copy[indexCopy--] = data[i];
for (; j >= start + length + 1; j--)
copy[indexCopy--] = data[j];
return left + right + count;
}
~~~
我们知道,归并排序的时间复杂度是O(nlogn),比最直观的O(n^2)要快,但同时归并排序需要一个长度为n的辅助数组,相当于我们用O(n)的空间消耗换来了时间效率的提升,因此这是一种用空间换时间的算法。
### 2.4 (52)两个链表的第一个公共节点[¶](https://blog.yorek.xyz/leetcode/code_interviews_5/#24-52 "Permanent link")
> 输入两个链表,找出它们的第一个公共结点。
**蛮力法不可取**
在第一链表上顺序遍历每个节点,每遍历到一个节点,就在第二个链表上顺序遍历每个节点。如果在第二个链表上有一个节点和第一个链表上的节点一样,则说明两个链表在这个节点上重合于是就找到了它们的公共节点。如果第一个链表的长度为m,第二个链表的长度为n,那么,显然该方法的时间复杂度是O(mn)。
**使用栈**
从链表节点的定义可以看出,这两个链表是单向链表。如果两个单向链表有公共的节点,那么这两个链表从某一节点开始,它们的next都指向同一个节点。但由于是单向链表的节点,每个节点只有一个next,因此从第一个公共节点开始,之后它们所有的节点都是重合的,不可能再出现分叉。所以两个有公共节点而部分重合的链表,其拓扑形状看起来像一个Y,而不可能像X,如图所示。
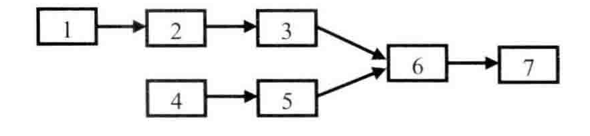
两个链表在值为6的节点处交汇
经过分析我们发现,如果两个链表有公共节点,那么公共节点出现在两个链表的尾部。如果我们从两个链表的尾部开始往前比较,那么最后一个相同的节点就是我们要找的节点。可问题是,在单向链表中,我们只能从头节点开始按顺序遍历,最后才能到达尾节点。最后到达的尾节点却要最先被比较,这听起来是不是像“后进先出”?于是我们就能想到用栈的特点来解决这个问题:分别把两个链表的节点放入两个栈里,这样两个链表的尾节点就位于两个栈的栈顶,接下来比较两个栈顶的节点是否相同。如果相同,则把栈顶弹出接着比较下一个栈顶,直到找到最后一个相同的节点。
在上述思路中,我们需要用两个辅助栈。如果链表的长度分别为m和n,那么空间复杂度是O(m+n)。这种思路的时间复杂度也是O(m+n)。和最开始的蛮力法相比,时间效率得到了提高,相当于用空间消耗换取了时间效率。
**推荐解法,时间复杂度为O(m+n),不需要辅助栈**
之所以需要用到栈,是因为我们想同时遍历到达两个栈的尾节点。当两个链表的长度不相同时,如果我们从头开始遍历,那么到达尾节点的时间就不一致。其实解决这个问题还有一种更简单的办法:首先遍历两个链表得到它们的长度,就能知道哪个链表比较长,以及长的链表比短的链表多几个节点。在第二次遍历的时候,在较长的链表上先走若干步,接着同时在两个链表上遍历,找到的第一个相同的节点就是它们的第一个公共节点。比如在图的两个链表中,我们可以先遍历一次得到它们的长度分别为5和4,也就是较长的链表与较短的链表相比多一个节点。第二次先在长的链表上走1步,到达节点2。接下来分别从节点2和节点4出发同时遍历两个节点,直到找到它们第一个相同的节点6,这就是我们想要的结果。第三种思路和第二种思路相比,时间复杂度都是O(m+n),但我们不再需要辅助栈,因此提高了空间效率。
~~~
private ListNode findFirstCommonNode(ListNode head1, ListNode head2) {
if (head1 == null || head2 == null) {
return null;
}
// 得到两个链表的长度
int m = length(head1), n = length(head2);
ListNode headLong = head1, headShort = head2;
// 使headLong指向长链表,headShort指向短链表
int length = Math.abs(m - n);
if (m < n) {
headLong = head2;
headShort = head1;
}
// 先在长链表上走几步
for (int i = 0; i < length; i++) {
headLong = headLong.next;
}
// 再同时在两个链表上遍历
while (headLong != null && headShort != null && headLong != headShort) {
headLong = headLong.next;
headShort = headShort.next;
}
// 此时有两种可能,一种确实是公共节点,另一种则是没有公共节点(null)
return headLong;
}
private int length(ListNode node) {
ListNode p = node;
int cnt = 0;
while (p != null) {
p = p.next;
cnt++;
}
return cnt;
}
~~~
相关题目
如果把图逆时针旋转90°,我们就会发现两个链表的拓扑形状和一棵树的形状非常相似,只是这里的指针是从叶节点指向根节点的。两个链表的第一个公共节点正好就是二叉树中两个叶节点的最低公共祖先。在后面,我们将详细讨论如何求两个节点的最低公共祖先。
- Java
- Object
- 内部类
- 异常
- 注解
- 反射
- 静态代理与动态代理
- 泛型
- 继承
- JVM
- ClassLoader
- String
- 数据结构
- Java集合类
- ArrayList
- LinkedList
- HashSet
- TreeSet
- HashMap
- TreeMap
- HashTable
- 并发集合类
- Collections
- CopyOnWriteArrayList
- ConcurrentHashMap
- Android集合类
- SparseArray
- ArrayMap
- 算法
- 排序
- 常用算法
- LeetCode
- 二叉树遍历
- 剑指
- 数据结构、算法和数据操作
- 高质量的代码
- 解决问题的思路
- 优化时间和空间效率
- 面试中的各项能力
- 算法心得
- 并发
- Thread
- 锁
- java内存模型
- CAS
- 原子类Atomic
- volatile
- synchronized
- Object.wait-notify
- Lock
- Lock之AQS
- Lock子类
- 锁小结
- 堵塞队列
- 生产者消费者模型
- 线程池