
#近实时搜索
因为`per-segment search`机制,索引和搜索一个文档之间是有延迟的。新的文档会在几分钟内可以搜索,但是这依然不够快。
磁盘是瓶颈。提交一个新的段到磁盘需要`fsync`操作,确保段被物理地写入磁盘,即时电源失效也不会丢失数据。但是`fsync`是昂贵的,它不能在每个文档被索引的时就触发。
所以需要一种更轻量级的方式使新的文档可以被搜索,这意味这移除`fsync`。
位于Elasticsearch和磁盘间的是文件系统缓存。如前所说,在内存索引缓存中的文档(图1)被写入新的段(图2),但是新的段首先写入文件系统缓存,这代价很低,之后会被同步到磁盘,这个代价很大。但是一旦一个文件被缓存,它也可以被打开和读取,就像其他文件一样。
**图1:内存缓存区有新文档的Lucene索引**
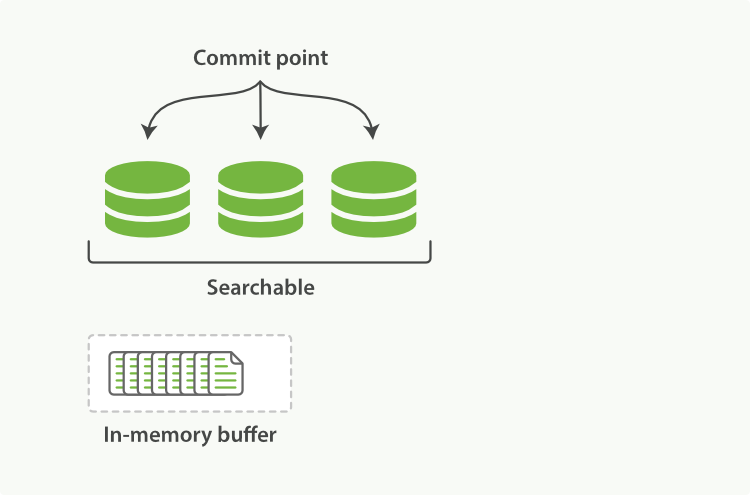
Lucene允许新段写入打开,好让它们包括的文档可搜索,而不用执行一次全量提交。这是比提交更轻量的过程,可以经常操作,而不会影响性能。
**图2:缓存内容已经写到段中,但是还没提交**
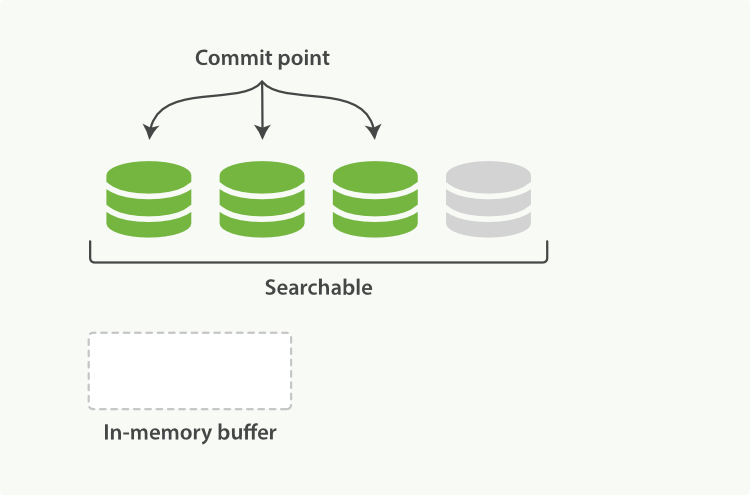
##refeash API
在Elesticsearch中,这种写入打开一个新段的轻量级过程,叫做refresh。默认情况下,每个分片每秒自动刷新一次。这就是为什么说Elasticsearch是近实时的搜索了:文档的改动不会立即被搜索,但是会在一秒内可见。
这会困扰新用户:他们索引了个文档,尝试搜索它,但是搜不到。解决办法就是执行一次手动刷新,通过API:
```Javascript
POST /_refresh <1>
POST /blogs/_refresh <2>
```
- <1> refresh所有索引
- <2> 只refresh 索引`blogs`
>虽然刷新比提交更轻量,但是它依然有消耗。人工刷新在测试写的时有用,但是不要在生产环境中每写一次就执行刷新,这会影响性能。相反,你的应用需要意识到ES近实时搜索的本质,并且容忍它。
不是所有的用户都需要每秒刷新一次。也许你使用ES索引百万日志文件,你更想要优化索引的速度,而不是进实时搜索。你可以通过修改配置项`refresh_interval`减少刷新的频率:
```Javascript
PUT /my_logs
{
"settings": {
"refresh_interval": "30s" <1>
}
}
```
- <1> 每30s refresh一次`my_logs`
`refresh_interval`可以在存在的索引上动态更新。你在创建大索引的时候可以关闭自动刷新,在要使用索引的时候再打开它。
```Javascript
PUT /my_logs/_settings
{ "refresh_interval": -1 } <1>
PUT /my_logs/_settings
{ "refresh_interval": "1s" } <2>
```
- <1> 禁用所有自动refresh
- <2> 每秒自动refresh
- Introduction
- 入门
- 是什么
- 安装
- API
- 文档
- 索引
- 搜索
- 聚合
- 小结
- 分布式
- 结语
- 分布式集群
- 空集群
- 集群健康
- 添加索引
- 故障转移
- 横向扩展
- 更多扩展
- 应对故障
- 数据
- 文档
- 索引
- 获取
- 存在
- 更新
- 创建
- 删除
- 版本控制
- 局部更新
- Mget
- 批量
- 结语
- 分布式增删改查
- 路由
- 分片交互
- 新建、索引和删除
- 检索
- 局部更新
- 批量请求
- 批量格式
- 搜索
- 空搜索
- 多索引和多类型
- 分页
- 查询字符串
- 映射和分析
- 数据类型差异
- 确切值对决全文
- 倒排索引
- 分析
- 映射
- 复合类型
- 结构化查询
- 请求体查询
- 结构化查询
- 查询与过滤
- 重要的查询子句
- 过滤查询
- 验证查询
- 结语
- 排序
- 排序
- 字符串排序
- 相关性
- 字段数据
- 分布式搜索
- 查询阶段
- 取回阶段
- 搜索选项
- 扫描和滚屏
- 索引管理
- 创建删除
- 设置
- 配置分析器
- 自定义分析器
- 映射
- 根对象
- 元数据中的source字段
- 元数据中的all字段
- 元数据中的ID字段
- 动态映射
- 自定义动态映射
- 默认映射
- 重建索引
- 别名
- 深入分片
- 使文本可以被搜索
- 动态索引
- 近实时搜索
- 持久化变更
- 合并段
- 结构化搜索
- 查询准确值
- 组合过滤
- 查询多个准确值
- 包含,而不是相等
- 范围
- 处理 Null 值
- 缓存
- 过滤顺序
- 全文搜索
- 匹配查询
- 多词查询
- 组合查询
- 布尔匹配
- 增加子句
- 控制分析
- 关联失效
- 多字段搜索
- 多重查询字符串
- 单一查询字符串
- 最佳字段
- 最佳字段查询调优
- 多重匹配查询
- 最多字段查询
- 跨字段对象查询
- 以字段为中心查询
- 全字段查询
- 跨字段查询
- 精确查询
- 模糊匹配
- Phrase matching
- Slop
- Multi value fields
- Scoring
- Relevance
- Performance
- Shingles
- Partial_Matching
- Postcodes
- Prefix query
- Wildcard Regexp
- Match phrase prefix
- Index time
- Ngram intro
- Search as you type
- Compound words
- Relevance
- Scoring theory
- Practical scoring
- Query time boosting
- Query scoring
- Not quite not
- Ignoring TFIDF
- Function score query
- Popularity
- Boosting filtered subsets
- Random scoring
- Decay functions
- Pluggable similarities
- Conclusion
- Language intro
- Intro
- Using
- Configuring
- Language pitfalls
- One language per doc
- One language per field
- Mixed language fields
- Conclusion
- Identifying words
- Intro
- Standard analyzer
- Standard tokenizer
- ICU plugin
- ICU tokenizer
- Tidying text
- Token normalization
- Intro
- Lowercasing
- Removing diacritics
- Unicode world
- Case folding
- Character folding
- Sorting and collations
- Stemming
- Intro
- Algorithmic stemmers
- Dictionary stemmers
- Hunspell stemmer
- Choosing a stemmer
- Controlling stemming
- Stemming in situ
- Stopwords
- Intro
- Using stopwords
- Stopwords and performance
- Divide and conquer
- Phrase queries
- Common grams
- Relevance
- Synonyms
- Intro
- Using synonyms
- Synonym formats
- Expand contract
- Analysis chain
- Multi word synonyms
- Symbol synonyms
- Fuzzy matching
- Intro
- Fuzziness
- Fuzzy query
- Fuzzy match query
- Scoring fuzziness
- Phonetic matching
- Aggregations
- overview
- circuit breaker fd settings
- filtering
- facets
- docvalues
- eager
- breadth vs depth
- Conclusion
- concepts buckets
- basic example
- add metric
- nested bucket
- extra metrics
- bucket metric list
- histogram
- date histogram
- scope
- filtering
- sorting ordering
- approx intro
- cardinality
- percentiles
- sigterms intro
- sigterms
- fielddata
- analyzed vs not
- 地理坐标点
- 地理坐标点
- 通过地理坐标点过滤
- 地理坐标盒模型过滤器
- 地理距离过滤器
- 缓存地理位置过滤器
- 减少内存占用
- 按距离排序
- Geohashe
- Geohashe
- Geohashe映射
- Geohash单元过滤器
- 地理位置聚合
- 地理位置聚合
- 按距离聚合
- Geohash单元聚合器
- 范围(边界)聚合器
- 地理形状
- 地理形状
- 映射地理形状
- 索引地理形状
- 查询地理形状
- 在查询中使用已索引的形状
- 地理形状的过滤与缓存
- 关系
- 关系
- 应用级别的Join操作
- 扁平化你的数据
- Top hits
- Concurrency
- Concurrency solutions
- 嵌套
- 嵌套对象
- 嵌套映射
- 嵌套查询
- 嵌套排序
- 嵌套集合
- Parent Child
- Parent child
- Indexing parent child
- Has child
- Has parent
- Children agg
- Grandparents
- Practical considerations
- Scaling
- Shard
- Overallocation
- Kagillion shards
- Capacity planning
- Replica shards
- Multiple indices
- Index per timeframe
- Index templates
- Retiring data
- Index per user
- Shared index
- Faking it
- One big user
- Scale is not infinite
- Cluster Admin
- Marvel
- Health
- Node stats
- Other stats
- Deployment
- hardware
- other
- config
- dont touch
- heap
- file descriptors
- conclusion
- cluster settings
- Post Deployment
- dynamic settings
- logging
- indexing perf
- rolling restart
- backup
- restore
- conclusion