
## 一. 为什么会有 xss 攻击
因为前端输入的不可信,就会导致恶意代码在浏览器中执行。
1. 通过一个异常的输入,在用户的浏览器中插入恶意的 javascript 脚本。
2. 直接添加一个有恶意脚本的网页,诱导用户打开。
3. 将恶意脚本以话题的方式提交到论坛中,诱使网站管理员打开这个话题,从而获得管理员权限,控制整个网站。
## 二. xss 攻击的种类
### 1. 存储型 XSS - 存储在数据库中
* 攻击者将恶意代码提交到目标网站的数据库中。
* 用户打开目标网站时,网站服务端将恶意代码从数据库取出,拼接在 HTML 中返回给浏览器。
* 用户浏览器接收到响应后解析执行,混在其中的恶意代码也被执行。
* 恶意代码窃取用户数据并发送到攻击者的网站,或者冒充用户的行为,调用目标网站接口执行攻击者指定的操作。
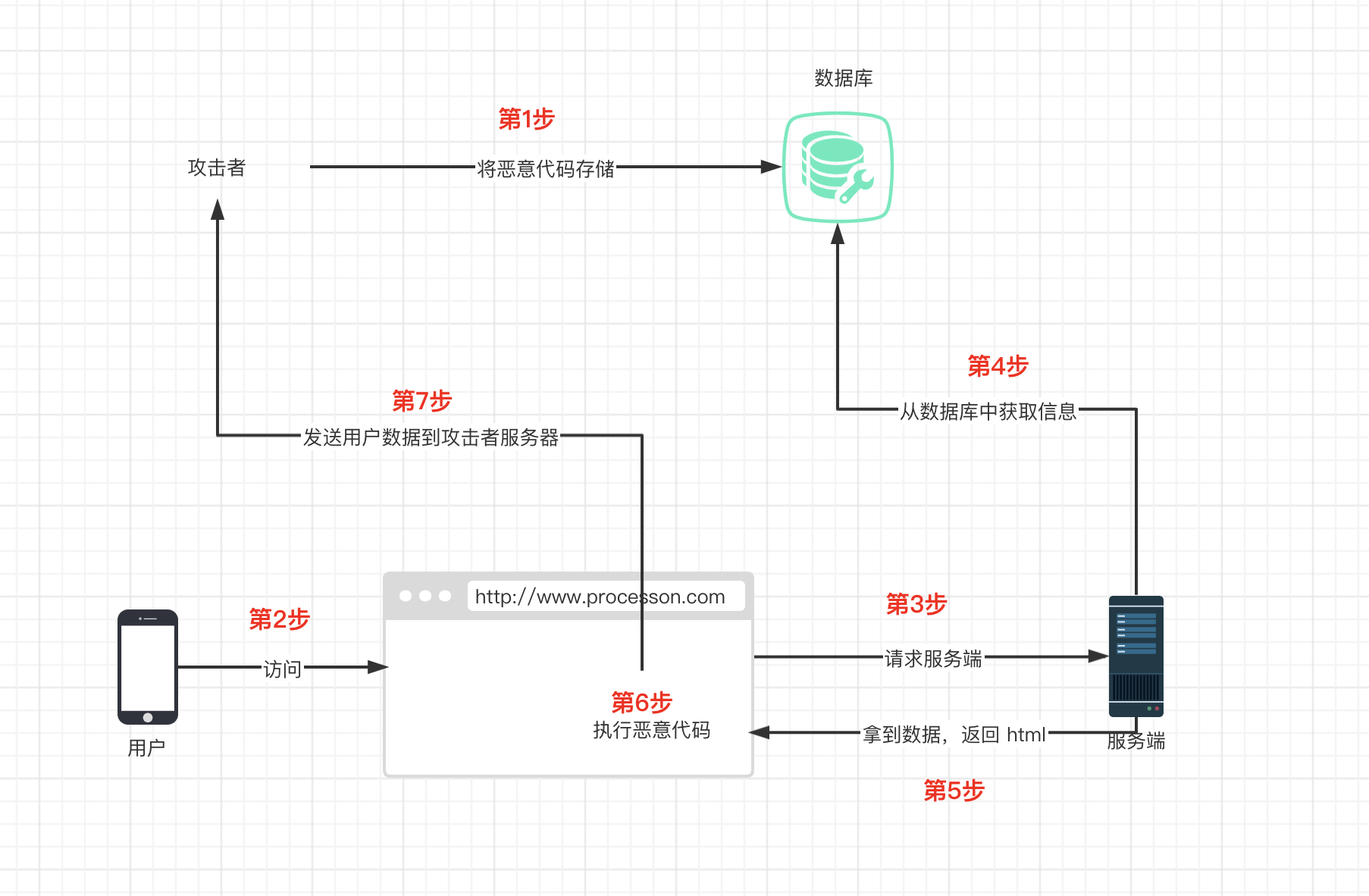
这种攻击常见于带有用户保存数据的网站功能,如论坛发帖、商品评论、用户私信等
#### 存储型 xss 案例:
1. 在UGC(User-generated Content,用户生产内容,百度贴吧,微博等)业务上,比较容易出现存储型 xss 漏洞。
#### 如何解决:
1. 属性值过滤
2. 重写
参考:腾讯安全应急响应中心:https://security.tencent.com/index.php/blog/msg/53
### 2. 反射型 XSS
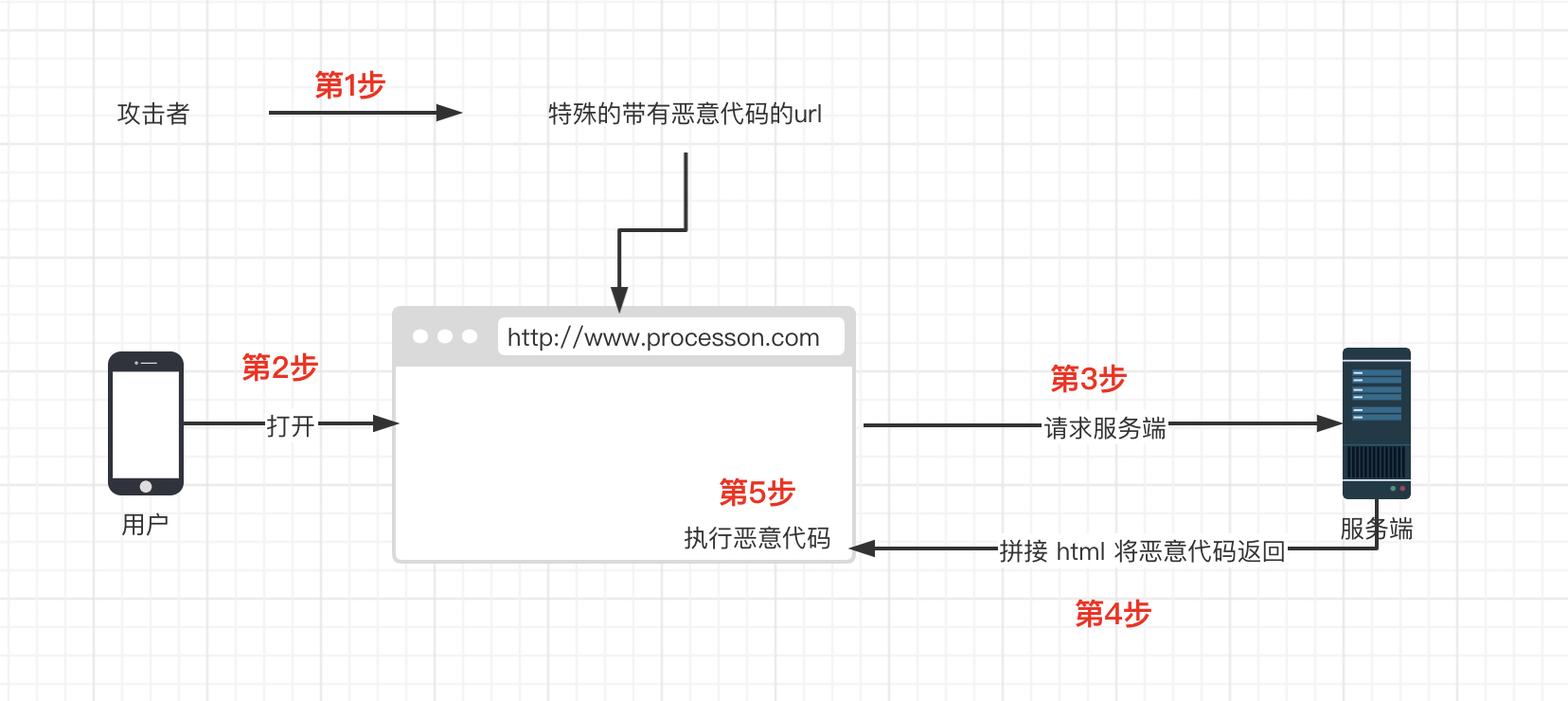
1. 攻击者构造出特殊的 URL,其中包含恶意代码。
2. 用户打开带有恶意代码的 URL 时,网站服务端将恶意代码从 URL 中取出,拼接在 HTML 中返回给浏览器。
3. 用户浏览器接收到响应后解析执行,混在其中的恶意代码也被执行。
4. 恶意代码窃取用户数据并发送到攻击者的网站,或者冒充用户的行为,调用目标网站接口执行攻击者指定的操作。
反射型 XSS 漏洞常见于通过 URL 传递参数的功能,如网站搜索、跳转等
#### 反射型 xss案例:
* script 标签出现在 url
* jacascript:代码出现在url
* jAvascRipt: 代码出现在url
解决:白名单解决法,在白名单内就返回页面,不再一律返回404
某天,公司做需要一个搜索页面,根据 URL 参数决定关键词的内容。代码如下:
```
<input type="text" value="<%= getParameter("keyword") %>">
<button> 搜索 </button>
<div>
您搜索的关键字是: <%= getParameter("keyword") %>
<div>
```
如果 黑客构造一下的url, 就可以轻易发起攻击。
```
http://xxx/search?keyword="><script>alert('XSS');</script>
```
当浏览器请求 `http://xxx/search?keyword="><script>alert('XSS');</script>` 时,服务端会解析出请求参数`keyword`,得到`"><script>alert('XSS');</script>`,拼接到 HTML 中返回给浏览器。形成了如下的 HTML:
~~~html
<input type="text" value=""><script>alert('XSS');</script>">
<button>搜索</button>
<div>
您搜索的关键词是:"><script>alert('XSS');</script>
</div>
~~~
问题的原因是,浏览器把用户的输入当成了脚本进行了执行。
解决办法:只要告诉浏览器这段内容是文本就可以解决了
于是有了下面这段代码:
```html
<input type="text" value="<%= escapeHTML(getParameter("keyword")) %>" >
<button>搜索</button>
<div>
您搜索的关键词是: <%= escapeHTML(getParameter("keyword")) %>
</div>
```
`escapeHTML()`按照如下规则进行转义:
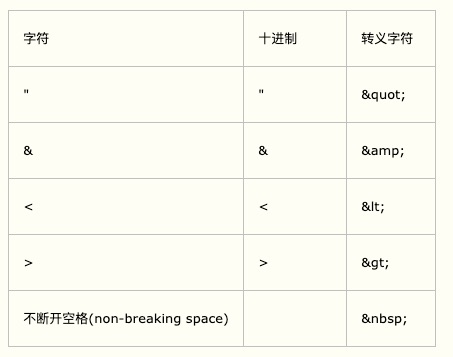
转义之后确实可以解决上面的那个利用标签闭合,进行攻击的情况。但是新的问题继续有:
如果 url 是这样的形式:`http://xxx/?redirect_to=javascript:alert('XSS')`, 展示在页面的一个 a 标签上:
~~~html
<a href="javascript:alert('XSS')">跳转...</a>
~~~
点击 a 标签,还是会弹出 xss,原来不仅仅是特殊字符,连`javascript:`这样的字符串如果出现在特定的位置也会引发 XSS 攻击。
考虑到只要 URL 的开头不是`javascript:`, 是不是就可以解决上面的问题。
代码如下:
~~~java
// 禁止 URL 以 "javascript:" 开头
xss = getParameter("redirect_to").startsWith('javascript:');
if (!xss) {
<a href="<%= escapeHTML(getParameter("redirect_to"))%>">
跳转...
</a>
} else {
<a href="/404">
跳转...
</a>
}
~~~
这样就安全了吗? 不是的。
如果 url 的链接是这样的 :`http://xxx/?redirect_to=jAvascRipt:alert('XSS')`,或 `http://xxx/?redirect_to=%20javascript:alert('XSS')`
依旧可以完成 xss 攻击。
那么如何解决呢?可以通过白名单的方法。
代码如下:
~~~java
// 根据项目情况进行过滤,禁止掉 "javascript:" 链接、非法 scheme 等
allowSchemes = ["http", "https"];
valid = isValid(getParameter("redirect_to"), allowSchemes);
if (valid) {
<a href="<%= escapeHTML(getParameter("redirect_to"))%>">
跳转...
</a>
} else {
<a href="/404">
跳转...
</a>
}
~~~
#### 总结:
* 攻击者利用用户输入片段,**拼接特殊格式的字符串**,突破原有位置的限制,形成了代码片段。
* 通过 HTML 转义,可以防止部分 XSS 攻击。(不同情况下,需要采用不同的转义规则)
* 如果数据是以 json 的形式,内联到 html 中 , 插入 json 的地方不能用 escapeHTML() 转义, 这样会破坏json格式。
* 如果 json 中包含字符串 `</script>` 时, 会闭合前一个 `<script>` 标签,通过增加一个`<script> `标签,就可以完成注入。
* 对于链接跳转,如`<a href="xxx"`或`location.href="xxx"`,要检验其内容,禁止以`javascript:`开头的链接,和其他非法的 scheme。
### 3. 基于 DOM 的 XSS(其实是一种特殊类型的反射型 xss)
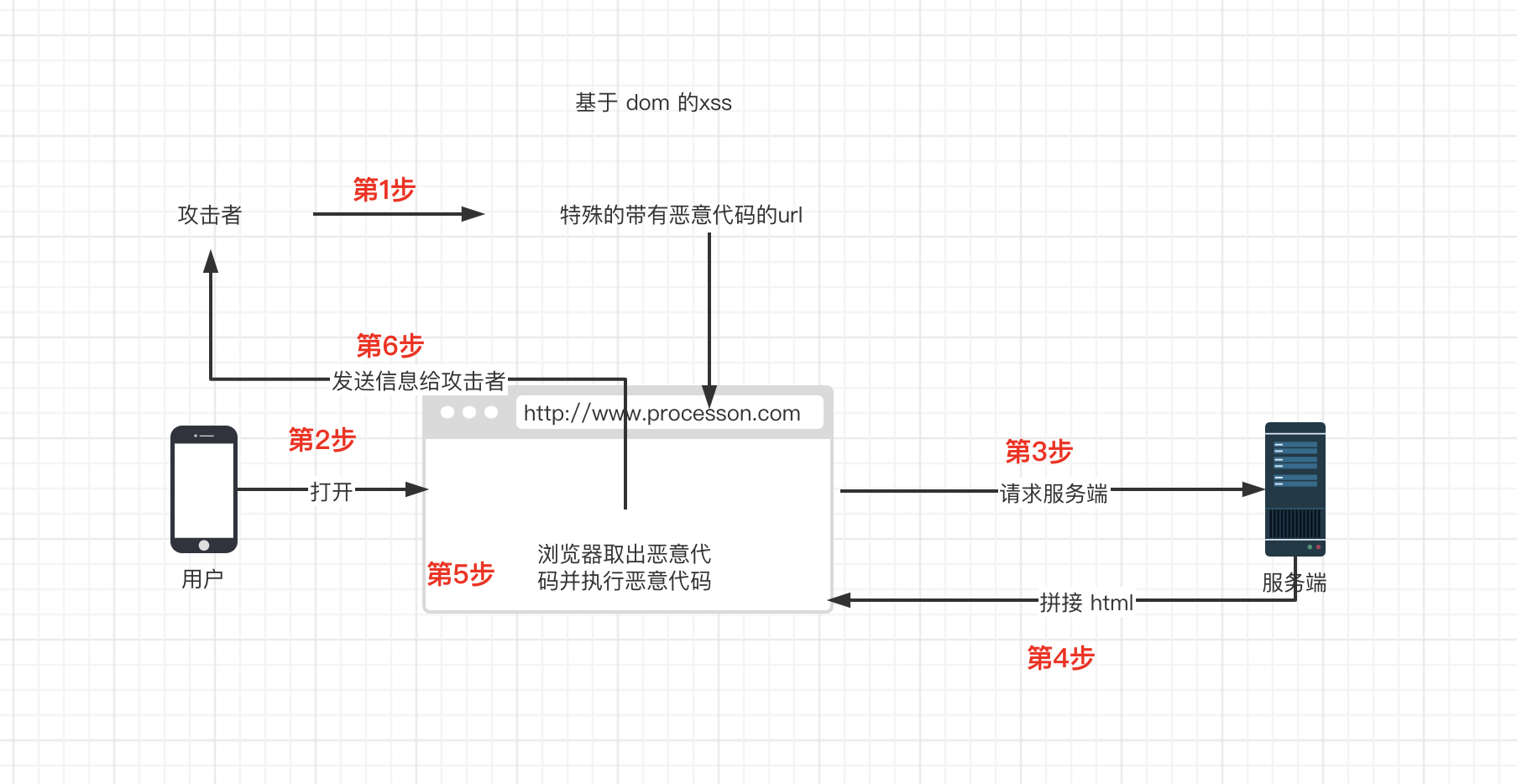
1. 攻击者构造出特殊的 URL,其中包含恶意代码。
2. 用户打开带有恶意代码的 URL。
3. 用户浏览器接收到响应后解析执行,前端 JavaScript 取出 URL 中的恶意代码并执行。
4. 恶意代码窃取用户数据并发送到攻击者的网站,或者冒充用户的行为,调用目标网站接口执行攻击者指定的操作。
**DOM 型 XSS 跟前两种 XSS 的区别**:DOM 型 XSS 攻击中,取出和执行恶意代码由浏览器端完成,属于前端 JavaScript 自身的安全漏洞,而其他两种 XSS 都属于服务端的安全漏洞。
#### dom 型 xss 案例
1. 取值写入页面或动态执行
想要在客户端实现接受参数并写入页面或动态执行,就不得不用到JavaScript“三姐妹”,她们分别是:**innerHTML、document.write、eval**。
* 直接从URL的锚参数(即位于#后面的参数)中取值,不经过任何处理直接innerHTML写入页面, 如果攻击者构造这样的 url :
`http://xxx.com/xxx.htm#msg=<img /src=x onerror=alter(1)/>`
由于整个攻击不需要像服务端发送任何数据,所以即使业务接入了 web 应用防火墙(WAF),也无法抓到这类 dom xss。
* 从 cookie中取值
直接从cookie中取值写入页面或动态执行,原理基本同从URL中的取参数值写入页面或动态执行,只是换了一个取值来源而已。
但同时我们注意到,还有一种较为特殊的业务场景,取cookie键值,动态拼接要页面引入前端资源的URL。
代码如下:

如果window.isp取到的值为`“www.attacker.com/”`,最终拼接出来的静态资源URL路径为:`http://www.attacker.com/victim.com`,因为“.”和“/”都不在转义范围内,导致攻击者可以向页面引入自己站点下的恶意js文件,进而实施DOM-XSS攻击.
* 从localStorage、Referer、Window name、SessionStorage中的取参数值写入页面或动态执行
一般情况下 window.name 容易被认为来源可信,但借助 iframe 的 name 属性,攻击者可以将页面的 window.name 设置为攻击代码,构造DOM XSS:

总结:
1. 在取值写入页面或动态执行的业务场景下,在将各种来源获取到的参数值传入JavaScript“三姐妹”函数(innerHTML、document.write、eval)处理前,对传入数据中的HTML特殊字符进行转义处理能防止大部分DOM-XSS的产生.
2. 根据不同业务的真实情况,还应使用正则表达式,针对传入的数据做更严格的过滤限制,才能保证万无一失。
3. 不到万不得已,不要使用eval函数处理不可控的外部数据。
4. 对于从cookie,还是从localStorage、Referer、Window name、SessionStorage中获取数据,都应使用安全的函数,对传入的数据做过滤后,再传递给相关函数写入页面或执行。
5. 参考/使用filter.js库
#### 2. 前端实现页面跳转
最常用的方式有 location.href 、location.replace() 、 location.assign()
也许提到页面跳转业务场景下的安全问题,你首先会想到限制不严导致任意URL跳转,而DOM XSS与此似乎“八竿子打不着”。但有一种神奇的东西叫“伪协议”,比如:“javascript:”、“vbscript:”、“data:”、“tencent:”、“mobileqqapi:”等,其中“javascript:”、“vbscript:”、“data:”在浏览器下可以执行脚本:
使用这些伪协议执行的JavaScript代码,就相当于在页面内注入了一段恶意代码
* 使用indexOf判断URL参数是否合法, 代码如下
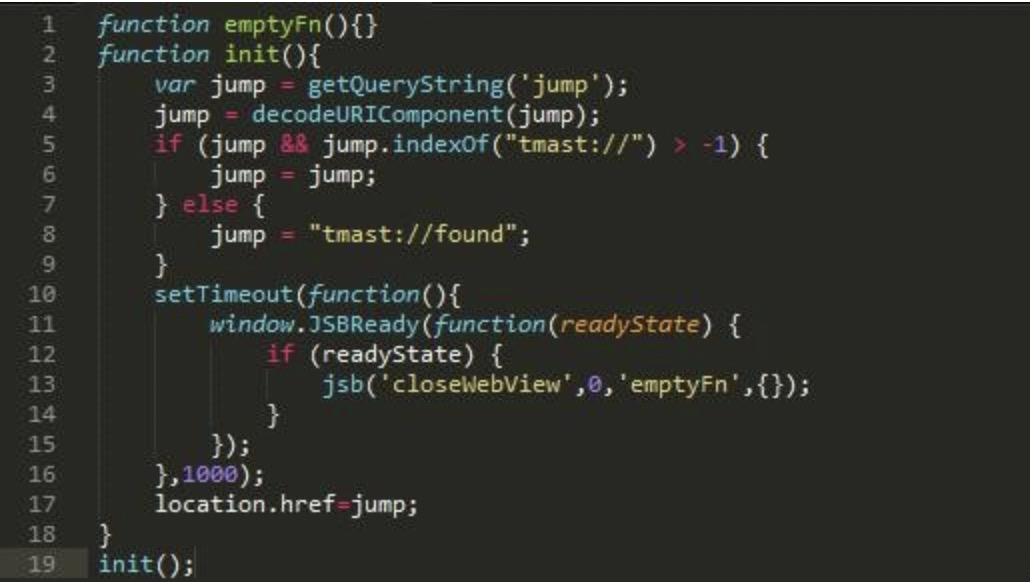
indexOf 是一个从头到尾检索字符串,查找是否有字串 xxx,如果攻击者构造 'javascript:alert(1);//xxx://' 这样的url,即可以成功让 indexOf 返回true,并进入跳转逻辑,完成攻击。又可以让 javascript 代码运行时忽略。(因为 xxx:// 位于JavaScript代码的注释部分)
* 正则表达式缺陷
由于 indexOf下藏着的深坑,想出用正则表达式解决这类问题,但是正则表达式也会有一些问题,比如:
跳转页面只能是`qq.com/paipai.com`。
认为这样就可以解决DOM-XSS和URL跳转的问题,但忘了一个神奇的符号“^”,加上和不加上,过滤的效果具有天壤之别。
(因为正则没有严格限制传入的URL开头只能是“http”或“https”,攻击者仍然可以构造“javascript:alert(1);//http://www.qq.com”来绕过看似严格的过滤。)
总结:
1. 限制能够跳转页面的协议:只能是http、https或是其他指可控协议;
2. 严格限制跳转的范围,如果业务只要跳转到指定的几个页面,可以直接从数组中取值判断是否这几个页面。
3. 如果跳转范围稍大,正确使用正则表达式将跳转URL严格限制到可控范围内。
## XSS 攻击的总结
* 防范存储型和反射型 XSS 是后端的责任
* DOM 型 XSS 攻击不发生在后端,是前端的责任。
* 不同的上下文,调用不同的转义规则
如 HTML 属性、HTML 文字内容、HTML 注释、跳转链接、内联 JavaScript 字符串、内联 CSS 样式表等,所需要的转义规则不一致。 业务 需要选取合适的转义库,并针对不同的上下文调用不同的转义规则。
## 防止 XSS 攻击
* HttpOnly 防止劫取 Cookie
* 不要相信用户的输入
* 对于服务端的返回进行编码或转义
- 计算机网络
- content-type
- cookie相关
- TCP/IP 4层模型
- HTTP2和HTTP1的区别
- http状态码
- DNS 域名解析
- URI 和 URL
- request和response
- cdn的原理
- http2和 https的区别
- 轮询 & 长轮询
- websocket 和 http 协议的区别
- 三次握手四次挥手
- https是如何加密的
- 原码、反码和补码
- Socket
- css
- 如何触发 BFC
- css 动画
- postcss-px-to-viewport、postcss-plugin-px2rem
- css 预处理器
- PostCss
- 实现一个 0.5 px的边框
- 实现10px的字体
- 实现左侧宽度固定,右侧宽度自适应的布局
- calc 的原理
- 伪类和伪元素的区别
- 层叠上下文和层叠顺序
- css 中的 meta标签
- flex
- css 画斜线
- transform 合成层
- 如何画一个三角形、正方体
- js动画和css动画的差异
- 盒模型
- 选择器的优先级
- css 选择器的解析顺序
- h5适配方案
- 适配刘海屏
- 移动端 rem 的大小是怎么计算出来的
- rem+vw
- 动态 viewport 和 REM 适配
- 深入理解viewport
- 算法
- 时间复杂度
- 排序
- 冒泡排序
- 选择排序
- 插入排序
- 快速排序
- 数组扁平化
- 二叉树
- 深度优先搜索
- 前中后序遍历
- 广度优先搜索
- 判断两个二叉树是否相等
- 计算二叉树节点个数
- 二分法查找
- 字符串
- 压缩字符串
- 一个函数,传入url和一个对象,返回以query形式的url
- 双指针算法
- 双指针算法(合并有序数组,三数求和)
- 限制同时只能并发四个请求
- 输出环形数组
- 函数坷里化
- 动态规划 - 最优解问题
- 股票利润最大
- 股票利润最大 -1
- 下台阶问题
- 连续子数组最大和
- 栈和队列
- 用两个栈模拟一个队列
- 两数求和
- 打印数组第n大的数
- 字符串包含
- 每3秒打印一个helloworld,总共执行4次
- 斐波那契
- 打印斐波那契数列前n项
- 动态规划实现输出斐波那契数列前n项
- 最长连续子字符串
- 实现一个深拷贝
- 实现一个进制转换
- js
- 基础知识整理
- for in 和 for of的区别
- js 隐式转换
- canvas
- 如何使用 Math.random() 生成 n-m,不包含 n 但包含 m 的整数?
- encodeURIComponent & encodeURI
- 为什么用 setTimeout, 不用 setInterval
- MutationObserver
- 浏览器渲染过程
- cookie
- 滚动相关
- 函数
- js有函数重载吗
- 函数柯里化的实现
- 高阶函数
- arguments
- IIFE立即执行函数
- 手写系列
- 手写 map、filter、reduce
- call、apply、bind
- 数据类型
- 基本数据类型
- 判断数据类型的typeof
- null 和 undefined
- 字符串类型
- 数字类型
- 引用数据类型
- Set、Map
- 如何判断数组类型
- instanceof 原理
- 数组的创建
- Service Worker
- JS中==、===和Object.is()的区别
- 插入节点
- 前端缓存
- script 异步加载有什么问题
- xhr 请求
- fetch
- axios
- 页面输入 url 到页面渲染都发生了什么
- 包装对象
- 错误对象
- 拖放 api
- 原型
- js new的时候都干了什么
- 屏蔽属性
- 闭包
- 应用一 - 防抖和节流
- 应用二 - 单例模式
- 创建对象
- 判断对象里是否有某个属性
- 事件循环
- node中的事件循环
- 继承
- 原型和继承的关系
- 如何基于es5实现继承
- 原型链继承
- 盗用构造函数继承
- 组合继承(函数可以重用)
- 原型式继承
- 寄生式继承
- 寄生式组合继承
- es6继承
- 继承基础
- 事件
- 自定义事件
- 事件派发
- 写一个EventEmitter类,包括on()、off()、once()、emit()方法
- 作用域
- 执行上下文
- 为什么let、const 有暂时性的死区
- 变量提升和函数声明提前
- 作用域链
- 变量提升和函数提升
- 词法作用域
- Promise
- 以往的异步编程模式
- promise的状态
- async/await
- 手写 promise
- 手写 promise all
- 输出顺序
- 垃圾回收
- 内存泄漏
- 浏览器缓存策略
- 跨域的解决方案
- options请求返回 *的弊端
- cookie 跨域
- 同源策略
- nginx反向代理时,对域名的要求
- 深浅拷贝
- Object 构造函数是深拷贝还是浅拷贝
- 手写深拷贝
- this
- 箭头函数中的this指向
- this的四种绑定机制和作用域
- 迭代器和生成器
- 文件的操作
- 文件上传
- 文件下载
- js输出题
- 操作dom为啥耗时
- 生成器
- 图片懒加载
- 前端框架类
- vuex
- getter
- mutation 和 action 的区别
- 原理分析
- vue3
- 和 vue2 key的对比
- 响应式原理
- diff 算法
- 和vue2相比 性能优化在什么地方
- 新特性
- @vue/composition-api
- 动静结合diff算法
- vue2
- 添加环境变量
- 变化侦测
- vue defineReactive 源码分析
- $delete 的原理
- $set 的原理
- $watch 的原理
- Array 的变化侦测
- object的变化侦测
- 虚拟 DOM
- patch
- vue 性能优化技巧
- vnode
- 模版编译原理
- 解析器
- 实例方法与全局api的实现原理
- 全局API实现原理
- 事件相关实例方法
- 生命周期相关实例方法
- 自定义指令是如何生效的
- 过滤器原理
- 生命周期
- 初始化阶段
- 模版编译
- 挂载阶段
- 卸载阶段
- 父子组件生命周期执行过程
- 调试源代码
- keep-live
- 组件注册原理
- render函数
- computed 原理
- 响应式是如何实现的
- errorCaptured 错误处理
- vue中的事件
- Vue中的scoped的实现原理
- 插件系统
- sync 修饰符的原理
- v-model 实现原理
- vue-router
- vue-router基础知识
- vue 路由按需加载
- vue-router 核心源码解读
- vue-router 工作原理
- 源码调试
- react-router-dom
- 基础整理
- 简介
- react(17.0.3)
- 事件机制
- react 单项数据流原理
- react diff
- react key
- react fiber
- 组件
- 受控组件和非受控组件
- 函数组件
- hooks
- useReducer
- useCallback 和 useMemo的区别
- useRef、createRef的区别
- 类组件
- pureComponent
- setState原理
- 高阶组件
- 代码分割
- 组件之间的通讯
- react 基础
- React17更新了哪些内容
- vue和react的对比
- react 生命周期
- render阶段和commit阶段
- 数据发生变更时,分别触发哪些生命周期
- context - 跨层级组件数据传递
- Profiler API
- web component
- redux
- compose 函数
- 迭代器
- useSelector
- dva-core
- redux-saga
- 性能优化
- 目的
- 常用策略
- 图片的优化
- html 的优化
- css 的优化
- js 优化
- 加载策略优化
- 关键指标
- RAIL
- 性能定位与监控
- 性能优化原则
- 长列表渲染优化
- 首屏加载优化
- 设计模式
- 策略模式
- 装饰器模式 & 如何用装饰器开发
- 观察者模式
- 如何实现发布订阅模式
- 安全相关
- DDos
- SQL 注入
- 浏览器安全
- xss 攻击
- dom 型 xss是如何攻击的
- csrf 攻击
- 服务端渲染
- next
- nuxt
- 初始化
- git
- 一个仓库里怎么同时管理了多个单独发布的包
- 常用命令
- git reset 和 git revert 的区别
- git rebase的缺点
- typescript
- typescript 之 infer
- 高级类型
- 移动端 H5
- 1. 响应式页面开发
- vw 作为css长度单位
- 响应式背景图片
- vw px rem 之间的换算
- dpr 是什么
- 背景图保持宽高比
- 动效开发
- transform + transition
- hybrid
- jsbridge 原理
- 安卓微信唤醒app
- visibilitychange
- vconsole的实现原理
- cross-env原理
- 微信小程序
- mpx
- taro
- 微信小程序底层原理
- npm
- npm 脚本
- npx
- npm link
- node
- node 单线程的优点和缺点
- 如何理解node的事件驱动、无阻塞、单线程
- 洋葱模型
- node 基础知识
- buffer
- event
- 模块机制
- 如何设置环境变量
- 网络编程
- 构建TCP服务
- 构建UDP服务
- 构建HTTP服务
- 构建WebSocket服务
- 安全
- web应用
- 内存控制
- fs
- readFile 和 createReadStream 的区别
- util
- express
- serverLess
- 微前端
- 认识微前端
- 微前端原理
- qiankun
- html entry
- 路由原理
- 整体架构
- 框架、路由开发
- 模块
- 页面的渲染
- 模块之间的耦合
- 通用的组件库
- 模块之间的通信
- store
- 性能优化部分
- 缓存机制
- 防止重复打包基础模块
- 运行、工具
- 微前端应用跟业务组件有什么区别
- 视频直播
- RTC 和 RTMP
- m3u8和mp4
- webrtc 直播
- eslint
- eslint做代码检查
- nginx
- nginx 基础知识整理
- 使用背景
- V8引擎
- 渲染进程
- event loop 、js 引擎、渲染引擎的关系
- 基础知识
- linux
- 常用 linux 命令
- 前端工程化
- webpack
- webpack 打包原理
- webpack 如何分析内部依赖图
- webpack 5个核心概念
- webpack 打包静态资源
- 打包css到单独文件
- 使用devServer
- tree shaking
- 分割代码,按需加载
- commonChunkPlugin 提取第三方库和公共模块
- webpack优化静态资源
- webpack 与 gulp 对比
- webpack周边工具
- webpack中hash、chunkhash和contenthash三者的区别
- 实现一个自己的devServer
- babel
- 词法分析和语法分析
- AST
- 核心api
- 自动在 console.log 等 api 中插入文件名和行列号的参数
- gulp
- vite
- webComponents
- lit
- 基础
- 运维
- 弹性云、物理机
- k8s
- docker
- docker 基础知识