# 基础的数据结构
这篇文章不是讲解数据结构的文章,而是结合现实的场景帮助大家`理解和复习`数据结构与算法,如果你的数据结构基础很差,建议先去看一些基础教程,再转过来看。
本篇文章的定位是侧重于前端的,通过学习前端中实际场景的数据结构,从而加深大家对数据结构的理解和认识。
## 线性结构
数据结构我们可以从逻辑上分为线性结构和非线性结构。线性结构有数组,栈,链表等, 非线性结构有树,图等。
> 其实我们可以称树为一种半线性结构。
需要注意的是,线性和非线性不代表存储结构是线性的还是非线性的,这两者没有任何关系,它只是一种逻辑上的划分。
比如我们可以用数组去存储二叉树。
一般而言,有前驱和后继的就是线性数据结构。比如数组和链表。
> 其实一叉树就是链表。
### 数组
数组是最简单的数据结构了,很多地方都用到它。 比如有一个数据列表等,用它是再合适不过了。
其实后面的数据结构很多都有数组的影子。
我们之后要讲的栈和队列其实都可以看成是一种`受限`的数组,怎么个受限法呢?我们后面讨论。
我们来讲几个有趣的例子来加深大家对数组这种数据结构的理解。
#### React Hooks
Hooks 的本质就是一个数组, 伪代码:

那么为什么 hooks 要用数组? 我们可以换个角度来解释,如果不用数组会怎么样?
```js
function Form() {
// 1. Use the name state variable
const [name, setName] = useState("Mary");
// 2. Use an effect for persisting the form
useEffect(function persistForm() {
localStorage.setItem("formData", name);
});
// 3. Use the surname state variable
const [surname, setSurname] = useState("Poppins");
// 4. Use an effect for updating the title
useEffect(function updateTitle() {
document.title = name + " " + surname;
});
// ...
}
```
基于数组的方式,Form 的 hooks 就是 [hook1, hook2, hook3, hook4]。
进而我们可以得出这样的关系, hook1 就是 [name, setName] 这一对,hook2 就是 persistForm 这个。
如果不用数组实现,比如对象,Form 的 hooks 就是
```js
{
'key1': hook1,
'key2': hook2,
'key3': hook3,
'key4': hook4,
}
```
那么问题是 key1,key2,key3,key4 怎么取呢?这就是个问题了。更多关于 React hooks 的本质研究,请查看 [React hooks: not magic, just arrays](https://medium.com/@ryardley/react-hooks-not-magic-just-arrays-cd4f1857236e)
不过使用数组也有一个问题, 那就是 React 将`如何确保组件内部 hooks 保存的状态之间的对应关系`这个工作交给了开发人员去保证,即你必须保证 HOOKS 的顺序严格一致,具体可以看 React 官网关于 Hooks Rule 部分。
### 队列
队列是一种受限的序列,它只能够操作队尾和队首,并且只能只能在队尾添加元素,在队首删除元素。
队列作为一种最常见的数据结构同样有着非常广泛的应用, 比如消息队列
> "队列"这个名称,可类比为现实生活中排队(不插队的那种)
在计算机科学中,一个 队列 (queue) 是一种特殊类型的抽象数据类型或集合,集合中的实体按顺序保存。
队列基本操作有两种:
- 向队列的后端位置添加实体,称为入队
- 从队列的前端位置移除实体,称为出队。
队列中元素先进先出 FIFO (first in, first out) 的示意:
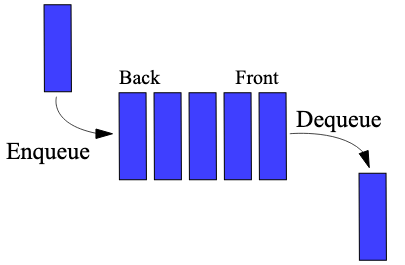
(图片来自 https://github.com/trekhleb/javascript-algorithms/blob/master/src/data-structures/queue/README.zh-CN.md)
我们前端在做性能优化的时候,很多时候会提到的一点就是“HTTP 1.1 的队头阻塞问题”,具体来说
就是 HTTP2 解决了 HTTP1.1 中的队头阻塞问题,但是为什么 HTTP1.1 有队头阻塞问题,HTTP2 究竟怎么解决的这个问题,很多人都不清楚。
其实`队头阻塞`是一个专有名词,不仅仅在 HTTP 有,交换器等其他地方也都涉及到了这个问题。实际上引起这个问题的根本原因是使用了`队列`这种数据结构。
协议规定, 对于同一个 tcp 连接,所有的 http1.0 请求放入队列中,只有前一个`请求的响应`收到了,才能发送下一个请求,这个时候就发生了阻塞,并且这个阻塞主要发生在客户端。
这就好像我们在等红绿灯,即使旁边绿灯亮了,你的这个车道是红灯,你还是不能走,还是要等着。

`HTTP/1.0` 和 `HTTP/1.1`:
在`HTTP/1.0` 中每一次请求都需要建立一个 TCP 连接,请求结束后立即断开连接。
在`HTTP/1.1` 中,每一个连接都默认是长连接 (persistent connection)。对于同一个 tcp 连接,允许一次发送多个 http1.1 请求,也就是说,不必等前一个响应收到,就可以发送下一个请求。这样就解决了 http1.0 的客户端的队头阻塞,而这也就是`HTTP/1.1`中`管道 (Pipeline)`的概念了。
但是,`http1.1 规定,服务器端的响应的发送要根据请求被接收的顺序排队`,也就是说,先接收到的请求的响应也要先发送。这样造成的问题是,如果最先收到的请求的处理时间长的话,响应生成也慢,就会阻塞已经生成了的响应的发送,这也会造成队头阻塞。可见,http1.1 的队首阻塞是发生在服务器端。
如果用图来表示的话,过程大概是:

`HTTP/2` 和 `HTTP/1.1`:
为了解决`HTTP/1.1`中的服务端队首阻塞,`HTTP/2`采用了`二进制分帧` 和 `多路复用` 等方法。
帧是`HTTP/2`数据通信的最小单位。在 `HTTP/1.1` 中数据包是文本格式,而 `HTTP/2` 的数据包是二进制格式的,也就是二进制帧。
采用帧的传输方式可以将请求和响应的数据分割得更小,且二进制协议可以更地被高效解析。`HTTP/2`中,同域名下所有通信都在单个连接上完成,该连接可以承载任意数量的双向数据流。每个数据流都以消息的形式发送,而消息又由一个或多个帧组成。多个帧之间可以乱序发送,根据帧首部的流标识可以重新组装。
`多路复用`用以替代原来的序列和拥塞机制。在`HTTP/1.1`中,并发多个请求需要多个 TCP 链接,且单个域名有 6-8 个 TCP 链接请求限制(这个限制是浏览器限制的,不同的浏览器也不一定一样)。在`HTTP/2`中,同一域名下的所有通信在单个链接完成,仅占用一个 TCP 链接,且在这一个链接上可以并行请求和响应,互不干扰。
> [此网站](https://http2.akamai.com/demo) 可以直观感受 `HTTP/1.1` 和 `HTTP/2` 的性能对比。
### 栈
栈也是一种受限的序列,它只能够操作栈顶,不管入栈还是出栈,都是在栈顶操作。
在计算机科学中,一个栈 (stack) 是一种抽象数据类型,用作表示元素的集合,具有两种主要操作:
- push, 添加元素到栈的顶端(末尾)
- pop, 移除栈最顶端(末尾)的元素
以上两种操作可以简单概括为**后进先出 (LIFO = last in, first out)**。
此外,应有一个 peek 操作用于访问栈当前顶端(末尾)的元素。(只返回不弹出)
> "栈"这个名称,可类比于一组物体的堆叠(一摞书,一摞盘子之类的)。
栈的 push 和 pop 操作的示意:

(图片来自 https://github.com/trekhleb/javascript-algorithms/blob/master/src/data-structures/stack/README.zh-CN.md)
栈在很多地方都有着应用,比如大家熟悉的浏览器就有很多栈,其实浏览器的执行栈就是一个基本的栈结构,从数据结构上说,它就是一个栈。
这也就解释了,我们用递归的解法和用循环+栈的解法本质上是差不多的。
比如如下 JS 代码:
```js
function bar() {
const a = 1;
const b = 2;
console.log(a, b);
}
function foo() {
const a = 1;
bar();
}
foo();
```
真正执行的时候,内部大概是这样的:

> 我画的图没有画出执行上下文中其他部分(this 和 scope 等), 这部分是闭包的关键,而我这里不是讲闭包的,是为了讲解栈的。
> 社区中有很多“执行上下文中的 scope 指的是执行栈中父级声明的变量”说法,这是完全错误的, JS 是词法作用域,scope 指的是函数定义时候的父级,和执行没关系
栈常见的应用有进制转换,括号匹配,栈混洗,中缀表达式(用的很少),后缀表达式(逆波兰表达式)等。
合法的栈混洗操作也是一个经典的题目,这其实和合法的括号匹配表达式之间存在着一一对应的关系,也就是说 n 个元素的栈混洗有多少种,n 对括号的合法表达式就有多少种。感兴趣的可以查找相关资料。
### 链表
链表是一种最基本数据结构,熟练掌握链表的结构和常见操作是基础中的基础。

(图片来自: https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/linked-list/traversal)
#### React Fiber
很多人都说 fiber 是基于链表实现的,但是为什么要基于链表呢,可能很多人并没有答案,那么我觉得可以把这两个点(fiber 和链表)放到一起来讲下。
fiber 出现的目的其实是为了解决 react 在执行的时候是无法停下来的,需要一口气执行完的问题的。

> 图片来自 Lin Clark 在 ReactConf 2017 分享
上面已经指出了引入 fiber 之前的问题,就是 react 会阻止优先级高的代码(比如用户输入)执行。因此他们打算自己自建一个`虚拟执行栈`来解决这个问题,这个虚拟执行栈的底层实现就是链表。
Fiber 的基本原理是将协调过程分成小块,一次执行一块,然后将运算结果保存起来,并判断是否有时间继续执行下一块(react 自己实现了一个类似 requestIdleCallback 的功能)。如果有时间,则继续。 否则跳出,让浏览器主线程歇一会,执行别的优先级高的代码。
当协调过程完成(所有的小块都运算完毕), 那么就会进入提交阶段, 执行真正的进行副作用(side effect)操作,比如更新 DOM,这个过程是没有办法取消的,原因就是这部分有副作用。
问题的关键就是将协调的过程划分为一块块的,最后还可以合并到一起,有点像 Map/Reduce。
React 必须重新实现遍历树的算法,从依赖于`内置堆栈的同步递归模型`,变为`具有链表和指针的异步模型`。
> Andrew 是这么说的: 如果你只依赖于 [内置] 调用堆栈,它将继续工作直到堆栈为空。
如果我们可以随意中断调用堆栈并手动操作堆栈帧,那不是很好吗?
这就是 React Fiber 的目的。 `Fiber 是堆栈的重新实现,专门用于 React 组件`。 你可以将单个 Fiber 视为一个`虚拟堆栈帧`。
react fiber 大概是这样的:
```js
let fiber = {
tag: HOST_COMPONENT,
type: "div",
return: parentFiber,
children: childFiber,
sibling: childFiber,
alternate: currentFiber,
stateNode: document.createElement("div"),
props: { children: [], className: "foo" },
partialState: null,
effectTag: PLACEMENT,
effects: [],
};
```
从这里可以看出 fiber 本质上是个对象,使用 parent,child,sibling 属性去构建 fiber 树来表示组件的结构树,
return, children, sibling 也都是一个 fiber,因此 fiber 看起来就是一个链表。
> 细心的朋友可能已经发现了, alternate 也是一个 fiber, 那么它是用来做什么的呢?
> 它其实原理有点像 git, 可以用来执行 git revert ,git commit 等操作,这部分挺有意思,我会在我的《从零开发 git》中讲解
想要了解更多的朋友可以看 [这个文章](https://github.com/dawn-plex/translate/blob/master/articles/the-how-and-why-on-reacts-usage-of-linked-list-in-fiber-to-walk-the-components-tree.md)
如果可以翻墙, 可以看 [英文原文](https://medium.com/react-in-depth/the-how-and-why-on-reacts-usage-of-linked-list-in-fiber-67f1014d0eb7)
[这篇文章](https://engineering.hexacta.com/didact-fiber-incremental-reconciliation-b2fe028dcaec) 也是早期讲述 fiber 架构的优秀文章
我目前也在写关于《从零开发 react 系列教程》中关于 fiber 架构的部分,如果你对具体实现感兴趣,欢迎关注。
## 非线性结构
那么有了线性结构,我们为什么还需要非线性结构呢? 答案是为了高效地兼顾静态操作和动态操作。大家可以对照各种数据结构的各种操作的复杂度来直观感受一下。
### 树
树的应用同样非常广泛,小到文件系统,大到因特网,组织架构等都可以表示为树结构,而在我们前端眼中比较熟悉的 DOM 树也是一种树结构,而 HTML 作为一种 DSL 去描述这种树结构的具体表现形式。如果你接触过 AST,那么 AST 也是一种树,XML 也是树结构。树的应用远比大多数人想象的要多得多。
树其实是一种特殊的`图`,是一种无环连通图,是一种极大无环图,也是一种极小连通图。
从另一个角度看,树是一种递归的数据结构。而且树的不同表示方法,比如不常用的`长子 + 兄弟`法,对于
你理解树这种数据结构有着很大用处, 说是一种对树的本质的更深刻的理解也不为过。
树的基本算法有前中后序遍历和层次遍历,有的同学对前中后这三个分别具体表现的访问顺序比较模糊,其实当初我也是一样的,后面我学到了一点,你只需要记住:`所谓的前中后指的是根节点的位置,其他位置按照先左后右排列即可`。比如前序遍历就是`根左右`, 中序就是`左根右`,后序就是`左右根`, 很简单吧?
我刚才提到了树是一种递归的数据结构,因此树的遍历算法使用递归去完成非常简单,幸运的是树的算法基本上都要依赖于树的遍历。
但是递归在计算机中的性能一直都有问题,因此掌握不那么容易理解的"命令式地迭代"遍历算法在某些情况下是有用的。如果你使用迭代式方式去遍历的话,可以借助上面提到的`栈`来进行,可以极大减少代码量。
> 如果使用栈来简化运算,由于栈是 FILO 的,因此一定要注意左右子树的推入顺序。
树的重要性质:
- 如果树有 n 个顶点,那么其就有 n - 1 条边,这说明了树的顶点数和边数是同阶的。
- 任何一个节点到根节点存在`唯一`路径,路径的长度为节点所处的深度
实际使用的树有可能会更复杂,比如使用在游戏中的碰撞检测可能会用到四叉树或者八叉树。以及 k 维的树结构 `k-d 树`等。

(图片来自 https://zh.wikipedia.org/wiki/K-d%E6%A0%91)
### 二叉树
二叉树是节点度数不超过二的树,是树的一种特殊子集,有趣的是二叉树这种被限制的树结构却能够表示和实现所有的树,
它背后的原理正是`长子 + 兄弟`法,用邓老师的话说就是`二叉树是多叉树的特例,但在有根且有序时,其描述能力却足以覆盖后者`。
> 实际上, 在你使用`长子 + 兄弟`法表示树的同时,进行 45 度角旋转即可。
一个典型的二叉树:
标记为 7 的节点具有两个子节点,标记为 2 和 6; 一个父节点,标记为 2, 作为根节点,在顶部,没有父节点。

(图片来自 https://github.com/trekhleb/javascript-algorithms/blob/master/src/data-structures/tree/README.zh-CN.md)
对于一般的树,我们通常会去遍历,这里又会有很多变种。
下面我列举一些二叉树遍历的相关算法:
- [94.binary-tree-inorder-traversal](../problems/94.binary-tree-inorder-traversal.md)
- [102.binary-tree-level-order-traversal](../problems/102.binary-tree-level-order-traversal.md)
- [103.binary-tree-zigzag-level-order-traversal](../problems/103.binary-tree-zigzag-level-order-traversal.md)
- [144.binary-tree-preorder-traversal](../problems/144.binary-tree-preorder-traversal.md)
- [145.binary-tree-postorder-traversal](../problems/145.binary-tree-postorder-traversal.md)
- [199.binary-tree-right-side-view](../problems/199.binary-tree-right-side-view.md)
相关概念:
- 真二叉树 (所有节点的度数只能是偶数,即只能为 0 或者 2)
另外我也专门开设了 [二叉树的遍历](./binary-tree-traversal.md) 章节,具体细节和算法可以去那里查看。
#### 堆
堆其实是一种优先级队列,在很多语言都有对应的内置数据结构,很遗憾 javascript 没有这种原生的数据结构。
不过这对我们理解和运用不会有影响。
堆的特点:
- 在一个 最小堆 (min heap) 中,如果 P 是 C 的一个父级节点,那么 P 的 key(或 value) 应小于或等于 C 的对应值。
正因为此,堆顶元素一定是最小的,我们会利用这个特点求最小值或者第 k 小的值。

- 在一个 最大堆 (max heap) 中,P 的 key(或 value) 大于 C 的对应值。

需要注意的是优先队列不仅有堆一种,还有更复杂的,但是通常来说,我们会把两者做等价。
相关算法:
- [295.find-median-from-data-stream](../problems/295.find-median-from-data-stream.md)
#### 二叉查找树
二叉排序树(Binary Sort Tree),又称二叉查找树(Binary Search Tree),亦称二叉搜索树。
二叉查找树具有下列性质的二叉树:
- 若左子树不空,则左子树上所有节点的值均小于它的根节点的值;
- 若右子树不空,则右子树上所有节点的值均大于它的根节点的值;
- 左、右子树也分别为二叉排序树;
- 没有键值相等的节点。
对于一个二叉查找树,常规操作有插入,查找,删除,找父节点,求最大值,求最小值。
二叉查找树,之所以叫查找树就是因为其非常适合查找,举个例子,
如下一颗二叉查找树,我们想找节点值小于且最接近 58 的节点,搜索的流程如图所示:

(图片来自 https://www.geeksforgeeks.org/floor-in-binary-search-tree-bst/)
另外我们二叉查找树有一个性质是: `其中序遍历的结果是一个有序数组`。
有时候我们可以利用到这个性质。
相关题目:
- [98.validate-binary-search-tree](../problems/98.validate-binary-search-tree.md)
### 二叉平衡树
平衡树是计算机科学中的一类数据结构,是一种改进的二叉查找树。一般的二叉查找树的查询复杂度取决于目标结点到树根的距离(即深度),因此当结点的深度普遍较大时,查询的均摊复杂度会上升。为了实现更高效的查询,产生了平衡树。
在这里,平衡指所有叶子的深度趋于平衡,更广义的是指在树上所有可能查找的均摊复杂度偏低。
一些数据库引擎内部就是用的这种数据结构,其目标也是将查询的操作降低到 logn(树的深度),可以简单理解为`树在数据结构层面构造了二分查找算法`。
基本操作:
- 旋转
- 插入
- 删除
- 查询前驱
- 查询后继
#### AVL
是最早被发明的自平衡二叉查找树。在 AVL 树中,任一节点对应的两棵子树的最大高度差为 1,因此它也被称为高度平衡树。查找、插入和删除在平均和最坏情况下的时间复杂度都是 O(logn)。增加和删除元素的操作则可能需要借由一次或多次树旋转,以实现树的重新平衡。AVL 树得名于它的发明者 G. M. Adelson-Velsky 和 Evgenii Landis,他们在 1962 年的论文 An algorithm for the organization of information 中公开了这一数据结构。 节点的平衡因子是它的左子树的高度减去它的右子树的高度(有时相反)。带有平衡因子 1、0 或 -1 的节点被认为是平衡的。带有平衡因子 -2 或 2 的节点被认为是不平衡的,并需要重新平衡这个树。平衡因子可以直接存储在每个节点中,或从可能存储在节点中的子树高度计算出来。
#### 红黑树
在 1972 年由鲁道夫·贝尔发明,被称为"对称二叉 B 树",它现代的名字源于 Leo J. Guibas 和 Robert Sedgewick 于 1978 年写的一篇论文。红黑树的结构复杂,但它的操作有着良好的最坏情况运行时间,并且在实践中高效:它可以在 O(logn) 时间内完成查找,插入和删除,这里的 n 是树中元素的数目
### 字典树(前缀树)
又称 Trie 树,是一种树形结构。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。

(图来自 https://baike.baidu.com/item/%E5%AD%97%E5%85%B8%E6%A0%91/9825209?fr=aladdin)
它有 3 个基本性质:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符;
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串;
- 每个节点的所有子节点包含的字符都不相同。
#### immutable 与 字典树
`immutableJS`的底层就是`share + tree`. 这样看的话,其实和字典树是一致的。
相关算法:
- [208.implement-trie-prefix-tree](../problems/208.implement-trie-prefix-tree.md)
- [211.add-and-search-word-data-structure-design](../problems/211.add-and-search-word-data-structure-design.md)
- [212.word-search-ii](../problems/212.word-search-ii.md)
## 图
前面讲的数据结构都可以看成是图的特例。 前面提到了二叉树完全可以实现其他树结构,
其实有向图也完全可以实现无向图和混合图,因此有向图的研究一直是重点考察对象。
图论〔Graph Theory〕是数学的一个分支。它以图为研究对象。图论中的图是由若干给定的点及连接两点的线所构成的图形,这种图形通常用来描述某些事物之间的某种特定关系,用点代表事物,用连接两点的线表示相应两个事物间具有这种关系。
## 图的表示方法
- 邻接矩阵(常见)
空间复杂度 O(n^2),n 为顶点个数。
优点:
1. 直观,简单。
2. 适用于稠密图
3. 判断两个顶点是否连接,获取入度和出度以及更新度数,时间复杂度都是 O(1)
- 关联矩阵
- 邻接表
对于每个点,存储着一个链表,用来指向所有与该点直接相连的点
对于有权图来说,链表中元素值对应着权重
例如在无向无权图中:

(图片来自 https://zhuanlan.zhihu.com/p/25498681)
可以看出在无向图中,邻接矩阵关于对角线对称,而邻接链表总有两条对称的边
而在有向无权图中:

(图片来自 https://zhuanlan.zhihu.com/p/25498681)
## 图的遍历
图的遍历就是要找出图中所有的点,一般有以下两种方法:
1. 深度优先遍历:(Depth First Search, DFS)
深度优先遍历图的方法是,从图中某顶点 v 出发, 不断访问邻居, 邻居的邻居直到访问完毕。
2. 广度优先搜索:(Breadth First Search, BFS)
广度优先搜索,可以被形象地描述为 "浅尝辄止",它也需要一个队列以保持遍历过的顶点顺序,以便按出队的顺序再去访问这些顶点的邻接顶点。
- 前言
- 第一章 - 算法专题
- 数据结构
- 二叉树的遍历
- 动态规划
- 哈夫曼编码和游程编码
- 布隆过滤器
- 字符串问题
- 前缀树专题
- 《贪婪策略》专题
- 《深度优先遍历》专题
- 滑动窗口(思路 + 模板)
- 位运算
- 设计题
- 小岛问题
- 最大公约数
- 并查集
- 平衡二叉树专题
- 第二章 - 91 天学算法
- 第一期讲义-二分法
- 第一期讲义-双指针
- 第二期
- 第三章 - 精选题解
- 《日程安排》专题
- 《构造二叉树》专题
- 字典序列删除
- 百度的算法面试题 * 祖玛游戏
- 西法的刷题秘籍】一次搞定前缀和
- 字节跳动的算法面试题是什么难度?
- 字节跳动的算法面试题是什么难度?(第二弹)
- 《我是你的妈妈呀》 * 第一期
- 一文带你看懂二叉树的序列化
- 穿上衣服我就不认识你了?来聊聊最长上升子序列
- 你的衣服我扒了 * 《最长公共子序列》
- 一文看懂《最大子序列和问题》
- 第四章 - 高频考题(简单)
- 面试题 17.12. BiNode
- 0001. 两数之和
- 0020. 有效的括号
- 0021. 合并两个有序链表
- 0026. 删除排序数组中的重复项
- 0053. 最大子序和
- 0088. 合并两个有序数组
- 0101. 对称二叉树
- 0104. 二叉树的最大深度
- 0108. 将有序数组转换为二叉搜索树
- 0121. 买卖股票的最佳时机
- 0122. 买卖股票的最佳时机 II
- 0125. 验证回文串
- 0136. 只出现一次的数字
- 0155. 最小栈
- 0167. 两数之和 II 输入有序数组
- 0169. 多数元素
- 0172. 阶乘后的零
- 0190. 颠倒二进制位
- 0191. 位1的个数
- 0198. 打家劫舍
- 0203. 移除链表元素
- 0206. 反转链表
- 0219. 存在重复元素 II
- 0226. 翻转二叉树
- 0232. 用栈实现队列
- 0263. 丑数
- 0283. 移动零
- 0342. 4的幂
- 0349. 两个数组的交集
- 0371. 两整数之和
- 0437. 路径总和 III
- 0455. 分发饼干
- 0575. 分糖果
- 0874. 模拟行走机器人
- 1260. 二维网格迁移
- 1332. 删除回文子序列
- 第五章 - 高频考题(中等)
- 0002. 两数相加
- 0003. 无重复字符的最长子串
- 0005. 最长回文子串
- 0011. 盛最多水的容器
- 0015. 三数之和
- 0017. 电话号码的字母组合
- 0019. 删除链表的倒数第N个节点
- 0022. 括号生成
- 0024. 两两交换链表中的节点
- 0029. 两数相除
- 0031. 下一个排列
- 0033. 搜索旋转排序数组
- 0039. 组合总和
- 0040. 组合总和 II
- 0046. 全排列
- 0047. 全排列 II
- 0048. 旋转图像
- 0049. 字母异位词分组
- 0050. Pow(x, n)
- 0055. 跳跃游戏
- 0056. 合并区间
- 0060. 第k个排列
- 0062. 不同路径
- 0073. 矩阵置零
- 0075. 颜色分类
- 0078. 子集
- 0079. 单词搜索
- 0080. 删除排序数组中的重复项 II
- 0086. 分隔链表
- 0090. 子集 II
- 0091. 解码方法
- 0092. 反转链表 II
- 0094. 二叉树的中序遍历
- 0095. 不同的二叉搜索树 II
- 0096. 不同的二叉搜索树
- 0098. 验证二叉搜索树
- 0102. 二叉树的层序遍历
- 0103. 二叉树的锯齿形层次遍历
- 0113. 路径总和 II
- 0129. 求根到叶子节点数字之和
- 0130. 被围绕的区域
- 0131. 分割回文串
- 0139. 单词拆分
- 0144. 二叉树的前序遍历
- 0150. 逆波兰表达式求值
- 0152. 乘积最大子数组
- 0199. 二叉树的右视图
- 0200. 岛屿数量
- 0201. 数字范围按位与
- 0208. 实现 Trie (前缀树)
- 0209. 长度最小的子数组
- 0211. 添加与搜索单词 * 数据结构设计
- 0215. 数组中的第K个最大元素
- 0221. 最大正方形
- 0229. 求众数 II
- 0230. 二叉搜索树中第K小的元素
- 0236. 二叉树的最近公共祖先
- 0238. 除自身以外数组的乘积
- 0240. 搜索二维矩阵 II
- 0279. 完全平方数
- 0309. 最佳买卖股票时机含冷冻期
- 0322. 零钱兑换
- 0328. 奇偶链表
- 0334. 递增的三元子序列
- 0337. 打家劫舍 III
- 0343. 整数拆分
- 0365. 水壶问题
- 0378. 有序矩阵中第K小的元素
- 0380. 常数时间插入、删除和获取随机元素
- 0416. 分割等和子集
- 0445. 两数相加 II
- 0454. 四数相加 II
- 0494. 目标和
- 0516. 最长回文子序列
- 0518. 零钱兑换 II
- 0547. 朋友圈
- 0560. 和为K的子数组
- 0609. 在系统中查找重复文件
- 0611. 有效三角形的个数
- 0718. 最长重复子数组
- 0754. 到达终点数字
- 0785. 判断二分图
- 0820. 单词的压缩编码
- 0875. 爱吃香蕉的珂珂
- 0877. 石子游戏
- 0886. 可能的二分法
- 0900. RLE 迭代器
- 0912. 排序数组
- 0935. 骑士拨号器
- 1011. 在 D 天内送达包裹的能力
- 1014. 最佳观光组合
- 1015. 可被 K 整除的最小整数
- 1019. 链表中的下一个更大节点
- 1020. 飞地的数量
- 1023. 驼峰式匹配
- 1031. 两个非重叠子数组的最大和
- 1104. 二叉树寻路
- 1131.绝对值表达式的最大值
- 1186. 删除一次得到子数组最大和
- 1218. 最长定差子序列
- 1227. 飞机座位分配概率
- 1261. 在受污染的二叉树中查找元素
- 1262. 可被三整除的最大和
- 1297. 子串的最大出现次数
- 1310. 子数组异或查询
- 1334. 阈值距离内邻居最少的城市
- 1371.每个元音包含偶数次的最长子字符串
- 第六章 - 高频考题(困难)
- 0004. 寻找两个正序数组的中位数
- 0023. 合并K个升序链表
- 0025. K 个一组翻转链表
- 0030. 串联所有单词的子串
- 0032. 最长有效括号
- 0042. 接雨水
- 0052. N皇后 II
- 0084. 柱状图中最大的矩形
- 0085. 最大矩形
- 0124. 二叉树中的最大路径和
- 0128. 最长连续序列
- 0145. 二叉树的后序遍历
- 0212. 单词搜索 II
- 0239. 滑动窗口最大值
- 0295. 数据流的中位数
- 0301. 删除无效的括号
- 0312. 戳气球
- 0335. 路径交叉
- 0460. LFU缓存
- 0472. 连接词
- 0488. 祖玛游戏
- 0493. 翻转对
- 0887. 鸡蛋掉落
- 0895. 最大频率栈
- 1032. 字符流
- 1168. 水资源分配优化
- 1449. 数位成本和为目标值的最大数字
- 后序