
>[success] # 词法解析
~~~
1.生活中经常我们会有一些对话比如'今天我吃了鱼香肉丝',或者是'I ate noodles today' 但是实际
上如果我们大脑不进行分词理解这些语句实际变得无意义就像'Iatenoodlestoday' 只是一堆字符串
词法解析就像,我们大脑帮我们翻译的一样'今天''我''吃了''鱼香肉丝'
2.如何可以让程序也像人一样可以对这些词进行分类,其实在学习语言的过程时候已经知道了答
案,在我们第一次去学习汉字时候往往第一步是学习每一个'字',在将'字组成词',同理在学习
英语时候需要先学习'26个字母',再学的是将不同'26个字母组成单词',无论是'汉字'还是'单词'
组成的字它们会有一些新的标记例如'名词'、'动词'等
3.现在按照我们让大脑可以进行'词法分析'学习步骤,来实现编程语言的词法分析,第一步就是
'扫描',这个步骤将输入的内容当作一个无意义的字符串,读取时候它所看到的只是一次一个字符
例如'今天 我吃了鱼香肉丝',扫描后变成了['今', '天', ' ', '我', '吃', '了', '鱼', '香', '肉', '丝']
4.得到了这些我们在然后生成词素(lexeme)。词素是组成编程语言的最小的有意义的单元实
变成类似['今天','','我','吃', '了', '鱼香','肉丝'],此时这个阶段不知道它们是什么“类型”的词。只知道
单词在文本本身中的结束和开始位置。例如'今天' start:0 end:1
5.现在要做的是识别词类型,将识别的单词统一转换成词法单元'token' 形式即'<种别码,属性值>'
举个例子来看'<名词,今天><代词,我>...'
~~~
>[info] ## 词法单元'token'
两个例子来源
[MOOC编译原理](https://www.icourse163.org/course/HIT-1002123007?tid=1467039443)
[Reading Code Right, With Some Help From The Lexer](https://medium.com/basecs/reading-code-right-with-some-help-from-the-lexer-63d0be3d21d)
>[danger] ##### 例子一

* 举个例子

>[danger] ##### 举个前端例子的'token'
~~~
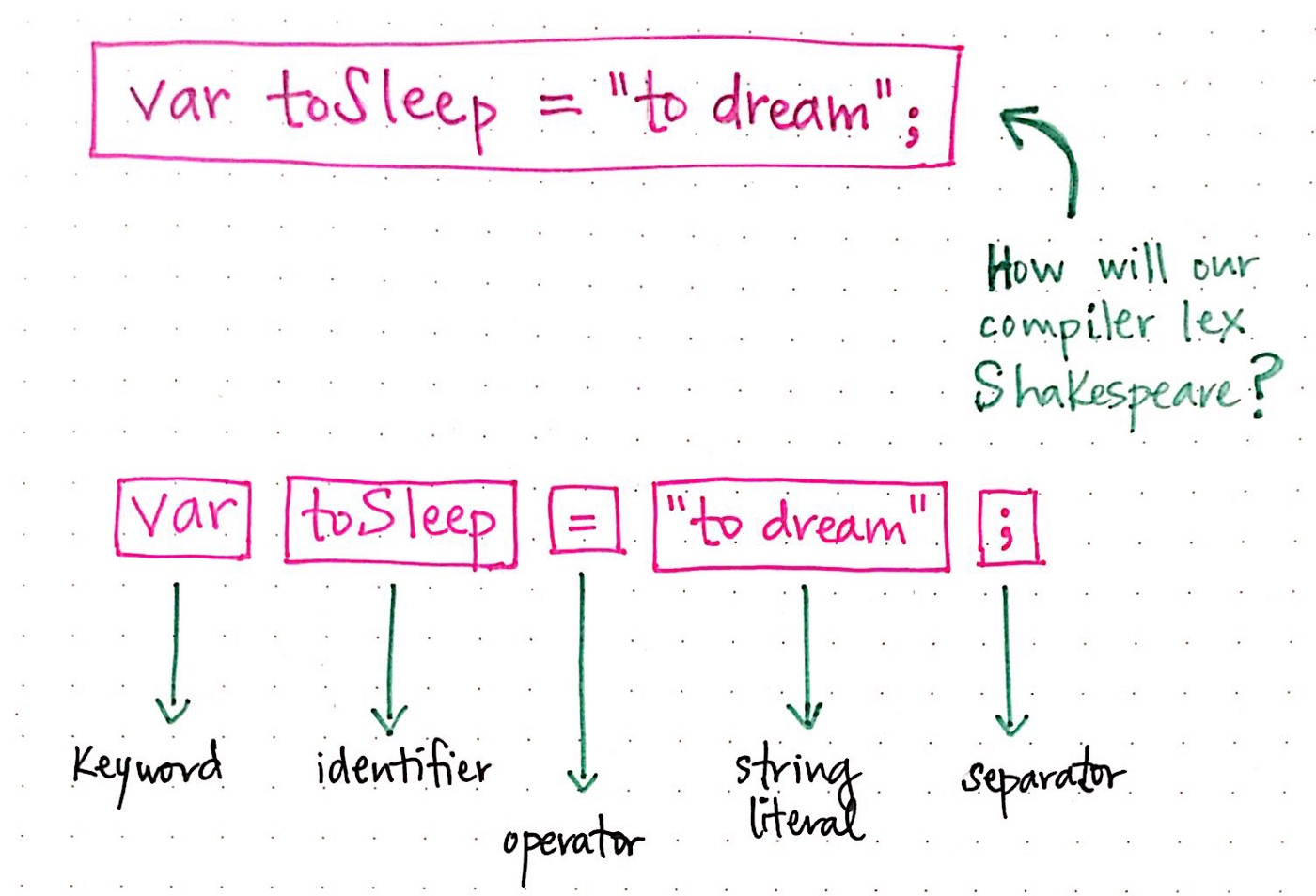
1.var toSleep = "to dream";,可以看到空格并不会作为一个词法单元('token'),但这完全是因为js
不需要,但如果你是python 开发就会知道'空格最为缩减是完全有作为词法单元('token')'必要
~~~
>[info] ## 做一个自己词法解析器
~~~
1.词法编辑器步骤,'读取每个字'=》'将字组成词素(lexeme)'=》'做好令牌token标记'
2.js程序语言比自然语言要稍微好处理点,首先js 和自然语句都一样都需有语法,即属于自己
的特定规则
2.1.空白:JS中连续的空格、换行、缩进等这些如果不在字符串里,就没有任何实际逻辑意义,
所以把连续的空白符直接组合在一起作为一个语法单元。
2.2.注释:行注释或块注释,虽然对于人类来说有意义,但是对于计算机来说知道这是个“注释”
就行了,并不关心内容,所以直接作为一个不可再拆的语法单元
2.3.字符串:对于机器而言,字符串的内容只是会参与计算或展示,里面再细分的内容也是没
必要分析的
2.4.数字:JS语言里就有16、10、8进制以及科学表达法等数字表达语法,数字也是个具备含
义的最小单元
2.5.标识符:没有被引号扩起来的连续字符,可包含字母、_、$、及数字(数字不能作为开
头)。标识符可能代表一个变量,或者true、false这种内置常量、也可能是if、return、
function这种关键字,是哪种语义,分词阶段并不在乎,只要正确切分就好了。
2.6.运算符:+、-、*、/、>、<等等
2.7.括号:(...)可能表示运算优先级、也可能表示函数调用,分词阶段并不关注是哪种语义,
只把“(”或“)”当做一种基本语法单元
2.8.还有其他:如中括号、大括号、分号、冒号、点等等
~~~
>[danger] ##### 举个例子
~~~
if (1 > 0) {
alert("if \"1 > 0\"");
}
~~~
~~~
1.第一步'扫描'拆解成单独字符
[
'i', 'f', '(', 'a', ' ', '=',
'=', '=', ' ', '1', ')', '{',
'\n', ' ', ' ', ' ', ' ', 'c',
'o', 'n', 's', 'o', 'l', 'e',
'.', 'l', 'o', 'g', '(', 'a',
')', '\n', '}'
]
2.做词素(lexeme),这里就变得简单了,js关键字即具备实际意义可以组成语句的并不像
自然语言那么多。而且大多数情况下通过'空格'即是每一个词最小单位例如'if' 等,这里将
词素(lexeme)和 token 作为一步一起输出(<种别码,属性值>),js像表达类似(<种别码,属性值>)
这里选择了对象,下面例子可以看出'if' 被标记为'Keyword' 即关键字
[
{
"type": "Keyword",
"value": "if"
},
{
"type": "Punctuator",
"value": "("
},
{
"type": "Identifier",
"value": "a"
},
{
"type": "Punctuator",
"value": "==="
},
{
"type": "Numeric",
"value": "1"
},
{
"type": "Punctuator",
"value": ")"
},
{
"type": "Punctuator",
"value": "{"
},
{
"type": "Identifier",
"value": "console"
},
{
"type": "Punctuator",
"value": "."
},
{
"type": "Identifier",
"value": "log"
},
{
"type": "Punctuator",
"value": "("
},
{
"type": "Identifier",
"value": "a"
},
{
"type": "Punctuator",
"value": ")"
},
{
"type": "Punctuator",
"value": "}"
}
]
~~~
* 词素(lexeme)

>[danger] ##### 形象的图形理解
* 图片来自【图文详解】200行JS代码,带你实现代码编译器(人人都能学会)
- https://juejin.cn/post/6844904105937207304#heading-24
~~~
1.这拆分过程其实就是简单粗暴地一个字符一个字符地遍历,然后分情况讨论
~~~
>[danger] ##### 开始敲代码
~~~
function tokenizeCode(code) {
// 当前读取指针位置
let current = 0;
// 令牌结果
const tokens = [];
// 当前字符
let currentChar = "";
while (current < code.length) {
currentChar = code[current];
// 如果是; 就是结束符 直接存起来
// 类似 const b = 2;const a = 1 此时; 也是有语义的
if (currentChar === ";") {
tokens.push({
type: "sep",
value: ";",
});
// 将指针指向下一个字符
++current;
// 这个字符不需要其他特殊出来因此可以直接处理 下一个
continue;
}
// 处理() 情况
if (currentChar === "(" || currentChar === ")") {
tokens.push({
type: "parens",
value: currentChar,
});
// 将指针指向下一个字符
++current;
// 这个字符不需要其他特殊出来因此可以直接处理 下一个
continue;
}
// 处理{} 情况
if (currentChar === "}" || currentChar === "{") {
// 与 ; 类似只是语法单元类型不同
tokens.push({
type: "brace",
value: currentChar,
});
++current;
continue;
}
// 处理 < > = 但实际情况比这复杂 还会有 >= <= == === 等情况
if (currentChar === ">" || currentChar === "<") {
// 与 ; 类似只是语法单元类型不同
tokens.push({
type: "operator",
value: currentChar,
});
++current;
continue;
}
// 处理数字
if (/[0-9]/.test(currentChar)) {
let value = "";
// 当情况为 1234 这种情况时候,即将1234 看作一个整体
// 需要一直循环到最后一个数字截至
while (/[0-9]/.test(currentChar)) {
value += currentChar;
currentChar = code[++current];
}
tokens.push({
type: "number",
value: value,
});
++current;
continue;
}
// 处理字符串 也就是引号" 开头到下一个 "结束
// 期望输出结果 例如"aa" { type: "string", value: "\"aa\"" },
// 可以看到对结果输出多了\ 转义符 这就是对字符处理稍微注意地方
if (currentChar === '"' || currentChar === "'") {
let value = "";
// 保存实际对应的闭合标签
const closeTag = currentChar;
value += currentChar;
while (currentChar !== closeTag) {
currentChar = code[++current];
value += currentChar;
}
currentChar = code[++current];
value += currentChar;
const token = {
type: "string",
value,
};
tokens.push(token);
++current;
continue;
}
if (/[a-zA-Z\$\_]/.test(currentChar)) {
// 标识符是以字母、$、_开始的
let value = "";
// 标识符是以字母、$、_开始的 和数字同理
// 即 if else for 这些
while (/[a-zA-Z\$\_]/.test(currentChar)) {
value += currentChar;
currentChar = code[++current];
}
tokens.push({
type: "identifier",
value: value,
});
++current;
continue;
}
if (/\s/.test(currentChar)) {
// let value = "";
// while (/\s/.test(currentChar)) {
// value += currentChar;
// currentChar = code[++current];
// }
// tokens.push({
// type: "whitespace",
// value: value,
// });
++current;
continue;
}
// 还可以有更多的判断来解析其他类型的语法单元
// 遇到其他情况就抛出异常表示无法理解遇到的字符
throw new Error("Unexpected " + currentChar);
}
return tokens;
}
const code = `
if (1 > 0) {
alert("aaaa");
}
`;
console.log(tokenizeCode(code));
~~~
* 打印结果
~~~
1.像 const if 这种等 这种没有双引号包裹的,因此可以我们理解为是变量名或者系统关键字,即
属于'标识符'(可以看上面案对标识符说明)
~~~
~~~
[
{ type: 'identifier', value: 'if' },
{ type: 'parens', value: '(' },
{ type: 'number', value: '1' },
{ type: 'operator', value: '>' },
{ type: 'number', value: '0' },
{ type: 'brace', value: '{' },
{ type: 'identifier', value: 'alert' },
{ type: 'string', value: '"a' },
{ type: 'identifier', value: 'aaa' },
{ type: 'parens', value: ')' },
{ type: 'sep', value: ';' },
{ type: 'brace', value: '}' }
]
~~~
>[info] ## 文章内容参考来源
[Rebuilding Babel: The Tokenizer](https://www.nan.fyi/tokenizer)
https://github.com/narendrasss/compiler/blob/main/src/tokenizer.ts
[MOOC编译原理](https://www.icourse163.org/course/HIT-1002123007?tid=1467039443)
[Babel是如何读懂JS代码的
](https://zhuanlan.zhihu.com/p/27289600)[Reading Code Right, With Some Help From The Lexer](https://medium.com/basecs/reading-code-right-with-some-help-from-the-lexer-63d0be3d21d)
https://github.com/YongzeYao/the-super-tiny-compiler-CN/blob/master/the-super-tiny-compiler.js
- 工程化 -- Node
- vscode -- 插件
- vscode -- 代码片段
- 前端学会调试
- 谷歌浏览器调试技巧
- 权限验证
- 包管理工具 -- npm
- 常见的 npm ci 指令
- npm -- npm install安装包
- npm -- package.json
- npm -- 查看包版本信息
- npm - package-lock.json
- npm -- node_modules 层级
- npm -- 依赖包规则
- npm -- install 安装流程
- npx
- npm -- 发布自己的包
- 包管理工具 -- pnpm
- 模拟数据 -- Mock
- 页面渲染
- 渲染分析
- core.js && babel
- core.js -- 到底是什么
- 编译器那些术语
- 词法解析 -- tokenize
- 语法解析 -- ast
- 遍历节点 -- traverser
- 转换阶段、生成阶段略
- babel
- babel -- 初步上手之了解
- babel -- 初步上手之各种配置(preset-env)
- babel -- 初步上手之各种配置@babel/helpers
- babel -- 初步上手之各种配置@babel/runtime
- babel -- 初步上手之各种配置@babel/plugin-transform-runtime
- babel -- 初步上手之各种配置(babel-polyfills )(未来)
- babel -- 初步上手之各种配置 polyfill-service
- babel -- 初步上手之各种配置(@babel/polyfill )(过去式)
- babel -- 总结
- 各种工具
- 前端 -- 工程化
- 了解 -- Yeoman
- 使用 -- Yeoman
- 了解 -- Plop
- node cli -- 开发自己的脚手架工具
- 自动化构建工具
- Gulp
- 模块化打包工具为什么出现
- 模块化打包工具(新) -- webpack
- 简单使用 -- webpack
- 了解配置 -- webpack.config.js
- webpack -- loader 浅解
- loader -- 配置css模块解析
- loader -- 图片和字体(4.x)
- loader -- 图片和字体(5.x)
- loader -- 图片优化loader
- loader -- 配置解析js/ts
- webpack -- plugins 浅解
- eslit
- plugins -- CleanWebpackPlugin(4.x)
- plugins -- CleanWebpackPlugin(5.x)
- plugin -- HtmlWebpackPlugin
- plugin -- DefinePlugin 注入全局成员
- webapck -- 模块解析配置
- webpack -- 文件指纹了解
- webpack -- 开发环境运行构建
- webpack -- 项目环境划分
- 模块化打包工具 -- webpack
- webpack -- 打包文件是个啥
- webpack -- 基础配置项用法
- webpack4.x系列学习
- webpack -- 常见loader加载器
- webpack -- 移动端px转rem处理
- 开发一个自己loader
- webpack -- plugin插件
- webpack -- 文件指纹
- webpack -- 压缩css和html构建
- webpack -- 清里构建包
- webpack -- 复制静态文件
- webpack -- 自定义插件
- wepack -- 关于静态资源内联
- webpack -- source map 对照包
- webpack -- 环境划分构建
- webpack -- 项目构建控制台输出
- webpack -- 项目分析
- webpack -- 编译提速优护体积
- 提速 -- 编译阶段
- webpack -- 项目优化
- webpack -- DefinePlugin 注入全局成员
- webpack -- 代码分割
- webpack -- 页面资源提取
- webpack -- import按需引入
- webpack -- 摇树
- webpack -- 多页面打包
- webpack -- eslint
- webpack -- srr打包后续看
- webpack -- 构建一个自己的配置后续看
- webpack -- 打包组件和基础库
- webpack -- 源码
- webpack -- 启动都做了什么
- webpack -- cli做了什么
- webpack - 5
- 模块化打包工具 -- Rollup
- 工程化搭建代码规范
- 规范化标准--Eslint
- eslint -- 扩展配置
- eslint -- 指令
- eslint -- vscode
- eslint -- 原理
- Prettier -- 格式化代码工具
- EditorConfig -- 编辑器编码风格
- 检查提交代码是否符合检查配置
- 整体流程总结
- 微前端
- single-spa
- 简单上手 -- single-spa
- 快速理解systemjs
- single-sap 不使用systemjs
- monorepo -- 工程
- Vue -- 响应式了解
- Vue2.x -- 源码分析
- 发布订阅和观察者模式
- 简单 -- 了解响应式模型(一)
- 简单 -- 了解响应式模型(二)
- 简单 --了解虚拟DOM(一)
- 简单 --了解虚拟DOM(二)
- 简单 --了解diff算法
- 简单 --了解nextick
- Snabbdom -- 理解虚拟dom和diff算法
- Snabbdom -- h函数
- Snabbdom - Vnode 函数
- Snabbdom -- init 函数
- Snabbdom -- patch 函数
- 手写 -- 虚拟dom渲染
- Vue -- minVue
- vue3.x -- 源码分析
- 分析 -- reactivity
- 好文
- grpc -- 浏览器使用gRPC
- grcp-web -- 案例
- 待续