
>[success] # JavaScript代码的执行
1. js 是通过浏览器的js引擎进行执行,现阶段最流行的引擎就是V8引擎
2. V8是用**C ++**编写的Google开源高性能JavaScript和WebAssembly引擎,它用于**Chrome和Node.js**等
3. 它实现ECMAScript和WebAssembly,并在Windows 7或更高版本,macOS 10.12+和使用x64,IA-32,ARM或MIPS处理器的Linux系统上运行
4. V8可以独立运行,也可以嵌入到任何C ++应用程序。最后可以将字节码编译为CPU可以直接执行的机器码
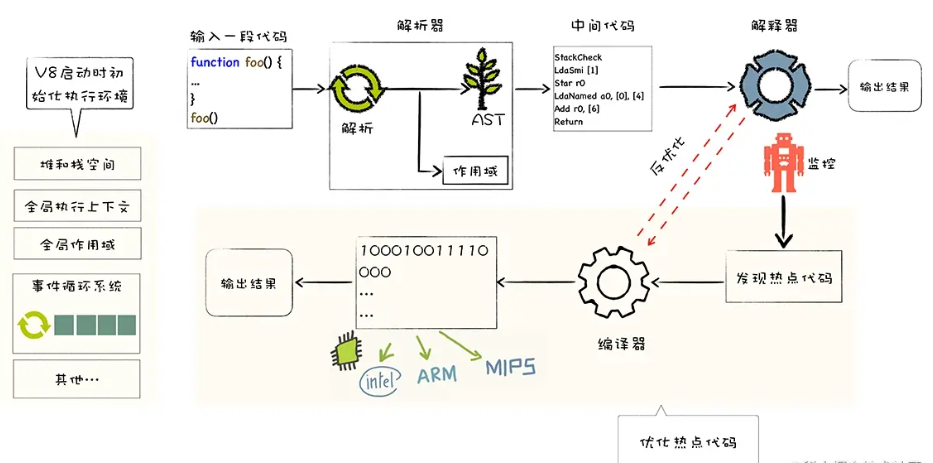
>[info] ## v8 中的一些模块
1. **Parse**模块会将JavaScript代码转换成**AST**(抽象语法树),这是因为解释器并**不直接认识JavaScript代码**;如果函数没有被调用,那么是不会被转换成AST的;
* **参考**:Parse的V8官方文档:https://v8.dev/blog/scanner
2. **Ignition**是一个解释器,会将**AST转换成ByteCode**(字节码),同时会收集TurboFan优化所需要的信息(比如函数参数的类型信息,有了类型才能进行真实的运算);如果函数只调用一次,Ignition会解释执行ByteCode;
* **参考**: Ignition的V8官方文档:https://v8.dev/blog/ignition-interpreter
3. **TurboFan是一个编译器**,可以将字节码编译为**CPU可以直接执行的机器码** 如果一个函数被多次调用,那么就会被标记为热点函数,那么就会经过TurboFan转换成优化的机器码,提高代码的执行性能;但是,机器码实际上也会被还原为ByteCode,这是因为如果后续执行函数的过程中,类型发生了变化(比如sum函数原来执行的是number类型,后来执行变成了string类型),之前优化的机器码并不能正确的处理运算,就会逆向的转换成字节码;
* **参考**: TurboFan的V8官方文档:https://v8.dev/blog/turbofan-jit
>[success] # JS -- 执行过程
~~~
1.V8 引擎为例,在 V8 引擎中 JavaScript 代码的运行过程主要分成三个阶段
1.1.'语法分析阶段': 该阶段会对代码进行语法分析,检查是否有语法错误(SyntaxError),
如果发现语法错误,会在控制台抛出异常并终止执行。
1.2.'编译阶段': 该阶段会进行执行上下文(Execution Context)的创建,包括创建变量对象、
建立作用域链、确定 this 的指向等。每进入一个不同的运行环境时,V8 引擎都会创建一个新
的执行上下文。
1.3.'执行阶段': 将编译阶段中创建的执行上下文压入调用栈,并成为正在运行的执行上下文,
代码执行结束后,将其弹出调用栈。
~~~
>[info] ## 语法分析阶段
~~~
1.当语法错误的时候。控制台出现'SyntaxError' 就是在这个阶段,这个阶段分析该js脚本代码块的
语法是否正确,如果出现不正确,就抛出'SyntaxError'并且停止,该js代码块的执行,然后继续查
找并加载下一个代码块,如果正确就进入下一个阶段'预编译阶段'
2.这个阶段会经历 过程'通过词法分析 -> 语法分析 -> 语法树'
2.1.'词法分析',它读取字符流(我们的代码)并使用定义的规则将它们组合成标记(token)
此外,它将删除空格字符,注释等。最后,整个代码字符串将被拆分为一个标记列表。
2.2.'语法分析':将在词法分析后获取一个简单的标记列表,并语法分析阶段会把一个令牌流转换成
抽象语法树(AST) 的形式。 验证语言语法并抛出语法错误(如果发生这种情况)
3.下面案例通过'espree' JavaScript 解析器 展示词法语法
~~~
>[danger] ##### 案例espree
~~~
import * as espree from 'espree'
// 词法分析
const tokens = espree.tokenize('function a(){}', { ecmaVersion: 6 })
console.log(tokens)
// ast 语法树生成
const ast = espree.parse('function a(){}')
console.log(ast)
~~~
* 词法输出
~~~
[
Token { type: 'Keyword', value: 'function', start: 0, end: 8 },
Token { type: 'Identifier', value: 'a', start: 9, end: 10 },
Token { type: 'Punctuator', value: '(', start: 10, end: 11 },
Token { type: 'Punctuator', value: ')', start: 11, end: 12 },
Token { type: 'Punctuator', value: '{', start: 12, end: 13 },
Token { type: 'Punctuator', value: '}', start: 13, end: 14 }
]
~~~
* ast 语法树
~~~
{
"type":"Program",
"start":0,
"end":14,
"body":[
{
"type":"FunctionDeclaration",
"start":0,
"end":14,
"id":{
"type":"Identifier",
"start":9,
"end":10,
"name":"a"
},
"params":[
],
"body":{
"type":"BlockStatement",
"start":12,
"end":14,
"body":[
]
},
"expression":false,
"generator":false
}
],
"sourceType":"script"
}
~~~
>[danger] ##### 总结
~~~
1. 词法分析=》
ast语法树=》
编译阶段(
1.执行上下文EC,js运行环境 全局上下文EC(G)/函数上下文EC(fn)/eval执行函数上下文/EC(Block)块级上下文
2.创建变量
3.建立作用域链
4.确定this指向
5.变量提升)=》
执行阶段
~~~
>[danger] ##### 参考文章
[JavaScript解释器
](https://javascript.ruanyifeng.com/advanced/interpreter.html)
[前端进阶之 JS 抽象语法树
](https://juejin.cn/post/6844903650670673933#heading-2)
[一日一练-JS AST抽象语法树
](https://jobbym.github.io/2018/12/12/%E4%B8%80%E6%97%A5%E4%B8%80%E7%BB%83-JS-AST%E6%8A%BD%E8%B1%A1%E8%AF%AD%E6%B3%95%E6%A0%91/)
>[info] ## JavaScript执行上下文和执行栈
[JS引擎线程的执行过程的三个阶段
](https://juejin.cn/post/6844903788629721096)
- HTTP -- 初始
- HTTP -- 什么是HTTP
- HTTP -- 相关技术
- HTTP -- 相关的协议
- Emmet -- 语法
- HTML -- 补充
- iframe -- 补充
- checkbox 和 radio 细节
- form -- 补充
- html -- html5
- html -- 视频音频
- html -- html5 data-* 全局属性
- css -- 重学
- css -- 单位
- css 知识补充 -- 导入
- css -- 颜色补充
- css --继承性
- css - 元素隐藏
- 标签元素--块/行内/行内块
- css -- 盒子阴影 – 在线查看
- css -边框图形
- css -- Web字体
- css -- 精灵图
- css -- 属性补充
- text-align -- 内容
- line-height -- 行高
- 文字换行
- overflow-溢出
- css -- 选择器
- css -- 伪元素
- css -- 伪类选择器
- 设置高度宽度 和 盒子模型
- css -- 文字溢出
- css -- white-space / text-overflow
- css -- 定位
- css -- 浮动
- 浮动 -- 案例
- flex -- 布局
- flex -- 解决等距布局
- flex -- 内容居中
- flex -- 导航栏
- Grid -- 布局
- css -- transform 形变
- css -- 垂直水平居中
- css -- transition 动画
- css -- Animation 动画
- css -- vertical-align
- css -- 函数
- css -- 媒体查询
- 重学案例
- 重新 -- 鼠标常见样式
- 重学 -- 透明边框background-clip
- 重学 -- 多重边框box-shadow
- css -- 预处理器
- 移动端适配
- 前端结构目录说明
- 浏览器 加载过程
- 回流和重绘
- 杂七杂八 -- 小工具方法
- npm包比较网站
- IP定位
- 通过useragent获取手机品牌型号
- 自启本地服务
- BOM -- 常用知识点记录
- window -- 认识
- windows -- 大小滚动
- BOM -- Location
- BOM -- URLSearchParams
- BOM -- history
- BOM -- navigator 和 screen
- 前端存储 -- Cookie、LocalStorage、IndexedDB
- DOM -- 知识总结
- DOM -- 获取元素
- DOM -- 节点属性
- DOM -- 元素属性
- 获取元素style的读取 - getComputedStyle
- DOM -- 元素的操作
- DOM -- 元素大小和滚动
- DOM -- 小练习
- Event -- 事件
- event -- 事件对象
- event -- 案例
- event -- 做一个树
- js -- ajax
- 封装一个ajax
- ajax -- 文件上传
- 倒计时抢购案例
- axios -- 封装
- 跨域
- 前端 -- Fetch API
- js -- 基础篇
- 数据类型
- 数据类型检测
- 类型小知识
- 原始类型的包装类
- 类型转换
- delete -- 运算符
- Date -- 对象
- 函数参数传递
- 对象某个属性不存时候判断
- 操作符
- 函数变量传值
- 访问对象通过点和[]
- 和if等同的一些写法
- for -- 执行顺序
- JS -- 执行过程
- JS中的堆(Heap)栈(Stack)内存
- JS -- 执行上下文
- Js -- ES3 和 ES5+ 后
- let const var
- ES3 -- 案例思考
- 闭包概念
- 浅拷贝和深拷贝
- JS -- 严格模式
- js -- 数组篇
- Array -- 数组基础
- Array -- 小常识检测数组
- Array -- 小技巧将数组转成字符串
- Array -- 自带方法
- Array -- 数组插入总结
- Array -- every是否都符合巧用
- js--Function篇
- Function -- length 属性
- Function -- arguments
- Function -- 也是对象
- Function -- new Function 创建方法
- Function -- 函数作为返回值
- Function -- callee
- 匿名函数
- Function -- 闭包
- 闭包内存查看
- 闭包 -- 使用的案例
- 闭包 -- 使用的案例
- 箭头函数不适用场景
- js -- this、call、apply
- this -- 指向
- call、apply -- 讲解
- 总结 -- this
- 思考题
- Object -- 数据属性/访问器属性
- 新增关于对象方法
- js -- 面向对象
- 对象到底是什么
- 到底什么是js的对象
- js --prototype、__proto__与constructor 1
- JS es5继承
- JS 中的原型继承说明
- JS -- Object是所有类的父类
- 总结
- Object -- 函数构造函数
- Object -- 手动实现一个new
- js -- 函数式编程(目前只是了解后面需要更多时间深入)
- 了解 -- 高阶函数
- 了解 -- 纯函数
- 了解 -- 函数柯里化
- 柯里化 -- 知识点
- 了解 -- 函数组合
- 了解 -- 函子
- js--小知识点
- url -- 将get请求连接参数变成对象
- event -- 一个函数处理多个事件
- try -- 处理异常
- Error -- 前段报错信息传给后台
- JSON -- 序列化
- return -- 返回true和false
- for -- 循环里初始化变量
- 命名 -- get和set怎么命名
- 链式调用
- 利用递归代替循环思路
- JS -- 技巧篇
- 技巧 -- 代码规范
- 技巧 -- 惰性载入函数
- 技巧 -- 防抖函数
- 技巧 -- 节流函数
- 插入补充(防抖/节流)
- 技巧 -- 定时器的使用
- 技巧 -- 回调函数
- 技巧 -- 分时函数
- 技巧 -- 除了return 我怎么跳出多层循环
- 技巧 -- switch 还是 if-else?
- 技巧 -- 将字符串转成对象
- 技巧 -- 函数转换
- 技巧 -- 工作记录数组对象中相同项
- JS -- 数组小文章总结
- 数组类型判断
- includes 和 indexOf
- for ... in,for ... of和forEach之间有什么区别
- map、filter、reduce、find 四种方法
- 多种形式处理数组思考方式
- for...in 和 Object.keys
- 各种知识点集合文章
- 创建数组 -- 总结
- 数组去重 -- 总结
- 获取数组中不重复的元素 -- 总结
- 比较两个数组元素相同 -- 总结
- 出现频率最高的元素 -- 总结
- 两数组交集 -- 总结
- 两数组差集 -- 总结
- 工具方法 - 总结
- 扁平化数组
- JS -- 数组技巧篇 30s
- 30s Array -- 创建数组篇(一)
- 30s Array --过滤(查询)篇章(一)
- 30s Array --过滤篇章(二)
- 30s Array -- 新增篇(一)
- 30s Array--比较篇(一)
- 30s Array -- 分组篇(一)
- 30 Array -- 删除篇(一)
- 30s Array-- 其他篇(一)
- 30s Array -- 个人感觉不常用篇章
- JS -- 对象技巧篇30s
- 30s Object -- 查(一)
- 30s Object -- 增(一)
- 30s Object -- 工具类型小方法
- 30s Object -- 跳过没看系列
- ES -- 新特性
- 变量篇章
- 变量 -- let/const/var声明
- 变量 -- 词法声明和变量声明
- 变量 -- var x = y = 100
- 变量 -- a.x = a = {n:2}
- 带标签的模板字符串
- 函数篇章
- 函数 -- 参数篇章
- 函数 -- 只能通过new创建实例
- 函数 -- 箭头函数
- 函数 -- 尾调优化
- 对象篇章
- 对象 -- 字面量写法的优化/新增方法
- 赋值篇章
- 解构赋值 -- 简单概念
- 解构赋值 -- 对象解构
- 解构赋值 -- 数组解构
- 解构赋值 -- 函数参数
- Symbol 属性
- Set 和 Map
- Set -- 去重/交、并、差集
- Map -- 集合
- 类class篇章
- ES6 和 ES5 的写法比较
- es6 -- mixin函数继承
- es6 -- 创建一个接口
- ES5 VS ES6 -- class 编译
- 数组新功能
- 创建/转换 -- 数组
- 迭代器和生成器
- es6 -- 迭代器
- es6 -- 生成器
- for-of 循环的是什么
- 做一个异步执行器
- 代理和反射
- Proxy -- 使用
- Reflect -- 使用
- Proxy 和 Reflect 结合使用
- 运算符 -- 展开运算符
- ES7 -- 新特性
- ES8 -- 新特性
- ES9 -- 新特性
- ES10 -- 新特性
- ES11 -- 新特性
- ES12 -- 新特性
- ES13 -- 新特性
- ES6 和 ES8 的异步
- js -- 异步、同步、阻塞、非阻塞
- js -- 如何做到异步的
- js -- 引擎线程,GUI渲染线程,浏览器事件触发线程
- js -- 如何通过事件循环运行异步
- js -- 误区任务回调就是异步
- js -- 宏任务和微任务
- 参考文章推荐阅读
- js -- callback 还是 promise
- js -- Promise 初识
- js -- 自己实现一个Promise
- js -- Promise 更多用法
- 再来看setTimeout 和for
- js -- ES8 异步 async await
- js -- 红绿灯问题
- js -- 倒计时
- 异步图片预加载
- 手动触发异步
- 异步题
- JS -- 模块化
- CommonJS -- 在node服务器端
- AMD 模块化规范
- ES Modules
- ES Modules -- 使用特点
- import 和 export 使用
- export 和 import -- 执行
- 其他用法
- systemjs
- 对比区别
- 使用babel 或webpack进行模块打包
- Jq -- 细节
- JS -- 性能优化
- 图片预加载
- js -- 正则
- 设计原则和编程技巧
- 设计原则 -- 单一职责
- js -- 设计模式
- 设计模式 -- 简单理解
- 一、鸭子类型
- 1.1 多态概念
- 1.2 小章节记录 -- 封装
- 1.3.多态和鸭子
- 设计模式 -- 单例模式(透明、惰性)
- 单例模式 -- js单例和惰性单例
- ES6 -- 写单例模式
- 设计模式 -- 策略模式
- 策略模式 -- 表单验证
- 策略模式 -- 表单验证多规则
- 策略模式和多态区别
- 设计模式 -- 代理模式(代理被代理相同方法)
- 代理模式 -- 分类
- 代理模式 -- 总结
- 设计模式 -- 迭代器模式
- 设计模式 -- 观察者(发布订阅)模式
- 观察者 和 发布订阅区别
- 发布订阅模式 -- 现在通用模型
- 发布订阅模式 -- 书中实际案例
- 发布订阅模式--全局发布订阅对象
- 发布订阅模式 -- vue
- 设计模式 -- 命令模式(对象方法拆分指令)
- 命令模式 -- js 自带
- 命令模式 -- 撤销和重做
- 命令模式 -- 命令和策略的区别
- 设计模式 -- 组合模式(树)
- 组合模式 -- 拆分了解
- 组合模式 -- java角度
- 组合模式 -- 书中案例扫描文件夹
- 组合模式 -- 注意点
- 组合模式 -- 引用父对象(书中案例)
- 组合模式 -- 小的案例
- 组合模式 -- 总结
- 设计模式 -- 模板方法(抽象类继承)
- 模板方法 -- 前端角度思考
- 模板方法 -- java 思考方式
- 模板方法 -- js没有抽象类
- 模板方法 -- 钩子方法
- 模板方法 -- 用js方式来实现
- 设计模式 -- 享元模式
- 享元、单例、对象池
- 享元模式 -- 前端角度思考
- 享元模式 -- 代码案例
- 享元模式 -- 适用和内外部状态
- 额外扩展 -- 对象池
- 设计模式 -- 职责链模式
- 职责链 -- 前端角度
- 职责链和策略
- 职责链 -- 异步的职责链
- 职责链 -- AOP
- 职责链 -- 改造迭代器模式的代码
- 设计模式 -- 中介者模式
- 中介者模式 -- 前端角度(一)
- 中介者模式 -- 前端角度(二)
- 中介者模式 -- 前端角度(三)
- 中介者模式 -- 总结
- 设计模式 -- 装饰者模式
- 装饰者模式 -- es5 解决方案
- 装饰器模式 -- 和代理模式区别
- 设计模式 -- 状态模式
- 状态模式 -- 前端思想
- 状态模式 -- 文件上传案例
- 状态模式 -- 和策略模式的区别
- 设计模式 -- 适配器模式
- js -- 代码重构
- 重构 -- 方法封装
- 重构 -- 抽象函数
- 高阶函数 -- 范式
- 状态管理方案
- Node -- 学习篇
- Node -- 服务端运行的js
- node -- Global(全局成员)
- node -- Buffer缓冲器
- node -- 路径操作
- node -- 文件的读写
- node -- 目录操作
- node -- HTTP
- HTTP -- 响应头常见类型
- HTTP -- 处理Get
- HTTP -- 处理Post
- HTTP -- 简单的案例
- Express
- Express -- 中间件
- Express -- 处理post/get
- Express -- 模板引擎
- Express -- 简单案例和目录搭建
- Express -- 数据库service.js
- Express -- json/url
- Express -- 配合数据库
- 配合数据库 -- 简单的登录
- npm -- js包管理
- npm -- 淘宝镜像
- nrm -- 更多镜像的选择
- yarn -- 包管理
- yarn -- 清理缓存
- WebPack -- 模块化开发
- webPack -- 安装、使用、打包
- webPack -- 使用配置文件
- 延伸 -- base64图片优劣
- webPack -- 完整配置