# XML
[TOC]
## XML介绍与用途
XML的全称为EXtensible Markup Language,可扩展标记语言
编写XML就是编写标签,形式与HTML非常类似。通常以文件的方式来保存数据,文件的扩展名为.xml。
>[info]XML和之前讲解过的Json作用其实相同的,都是为了保存数据。
> XML没有预制标签都是自己定义的。
> XML本身标签存在一定含义,并且语法格式非常规范,存在良好的人机可读性
比如:
~~~xml
person.xml
<person>
<name>张三</name>
<age>23</age>
<sex>男</sex>
<height>178</height>
<height>75</weight>
</person>
school.xml
<school>
<class no="J121">
<name>Java全日制121班</name>
<count>5</count>
</class>
<class no="JY3">
<name>Java业余3班</name>
<count>4</count>
</class>
</school>
~~~
**XML与HTML的比较**
1. XML与HTML非常相似,都是编写标签
2. XML没有预定义标签,HTML存在大量预定义标签
3. XML重在保存与传输数据,HTML用于显示信息
**XML的用途**
1. Java程序的配置描述文件
比如:web应用配置文件
~~~xml
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd"
id="WebApp_ID" version="3.1">
<display-name>demo3</display-name>
<welcome-file-list>
<welcome-file>Login2Servlet</welcome-file>
</welcome-file-list>
<filter>
<filter-name>EncodingFilter</filter-name>
<filter-class>cn.filters.EncodingFilter</filter-class>
<init-param>
<param-name>Encoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
</filter>
</web-app>
~~~
2. 用于保存程序产生的数据
3. 网络间的数据传输
## XML的语法规则
### XML文档结构
1. 第一行必须是XML声明
XML声明说明XML文档的基本信息,包括版本号与字符集,写在XML第一行
~~~xml
<?xml version="1.0" encoding="UTF-8"?>
~~~
2. 有且只有一个根节点
3. XML标签的书写规则与HTML相同
### XML标签书写规则
* 适当的注释 `<!-- -->`与缩进
* 合理的标签名
1. 标签名要有意义
2. 建议使用英文,小写字母,单词之间使用`-`进行分割
3. 建议多级标签之间不要存在重名的情况
* 合理使用属性
1. 标签属性用于描述标签不可或缺的信息
2. 对标签分组或者为标签设置id时常用属性表示
* 特殊字符与CDATA标签
标签体中,出现`<` `>`特殊字符,会破坏文档结构
如:
~~~xml
<example>
<question>3+4>6</question>
</example>
~~~
可以使用实体引用CDATA标签解决该问题
1. 实体引用:
| 实体引用 | 对应符号 |
| --- | --- |
| `<` | `<` |
| `>` | `>` |
| `&` | `&` |
| `'` | `'` |
| `"` | `"` |
2. CDATA标签
CDATA标签指的是不应由XML解析器进行解析的文本内容,使用`<![CDATA[开始 ~ 结束]]>`将该部分内容包裹起来
* 有序的子元素
指的是在多层嵌套的子元素中,标签的前后顺序应保持一致
## XML语义约束
在XML中文档结构正确,但可能不是有效的。
比如在关于员工档案的XML文档中,不允许出现有关植物品种的标签,XML语义约束指的就是规定XML文档中允许出现哪些元素
XML的语义约束有两种定义方式:DTD和XML Schema;
**DTD**
DTD(Document Type Definition 文档类型定义),是一种简单易用的语义约束方式。
DTD文件的扩展名为.dtd
~~~
<!ELEMENT>定义XML文档允许出现的节点和数量。
例如:定义hr节点下只允许出现一个employee子节点。
<!ELEMENT hr(employee)>
定义hr节点下至少出现一个employee子节点。
<!ELEMENT hr(employee+)>
定义hr节点下可以出现0...n个employee子节点。
<!ELEMENT hr(employee*)>
定义hr节点下可以最多出现一个employee子节点。
<!ELEMENT hr(employee?)>
定义hr节点标签体只能是文本。
<!ELEMENT hr(#PCDATA)>
定义hr节点只能有四个子节点,并且按顺序排列。
<!ELEMENT hr(name,age,salary,department)>
<!ATTLIST>定义XML文档中元素的属性。
例如:定义employee节点属性no的默认值为""
<!ATTLIST employee no CDATA "">
~~~
在XML中使用<!DOCTYPE>标签引用DTD文件
`<!DOCTYPE 根节点 SYSTEM "dtd文件路径">`
**XML Schema**
>[info]Schema比dtd更复杂 高级的约束性语言
提供了数据类型 格式限定 数据范围等特性
Schema 是w3c标准的标准规范
~~~xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- 人力资源管理信息 -->
<!-- xmlns:xsi属性的值用来告诉xml文档,使用的是schema约束 -->
<employee-data xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="hr.xsd">
<employee nid="3309">
<name>张三</name>
<age>24</age>
<salary>5000</salary>
<department>
<dname>会计部</dname>
<address>数字大厦</address>
</department>
</employee>
<employee nid="3310">
<name>李四</name>
<age>25</age>
<salary>5600</salary>
<department>
<dname>开发部</dname>
<address>数字大厦</address>
</department>
</employee>
</employee-data>
~~~
~~~xml
<?xml version="1.0" encoding="UTF-8"?>
<schema xmlns="http://www.w3.org/2001/XMLSchema">
<element name="employee-data"><!-- 表明根节点是employee-data -->
<!-- complexType标签含义是复杂节点,包含子节点的时候必须使用这个标签 -->
<!-- 因为employee是根节点,下面有很多的子节点,所以必须使用 -->
<complexType>
<sequence><!-- 序列:表明其下的子节点必须按照顺序前后严格书写 -->
<!-- minOccurs="1" maxOccurs="999"表示该节点最少出现一次,最大出现999次 -->
<element name="employee" minOccurs="1" maxOccurs="999">
<complexType>
<sequence>
<!-- type="string"表明该节点中只能输入字符串,不能拥有子节点 -->
<element name="name" type="string"></element>
<!-- type="integer"表明该节点中只能输入数字,不能拥有子节点 -->
<element name="age">
<simpleType>
<restriction base="integer"><!-- 表示数值范围 -->
<minInclusive value="18"></minInclusive>
<maxInclusive value="60"></maxInclusive>
</restriction>
</simpleType>
</element>
<element name="salary" type="integer"></element>
<element name="department">
<complexType>
<sequence>
<element name="dname" type="string"></element>
<element name="address" type="string"></element>
</sequence>
</complexType>
</element>
</sequence>
<!-- use="required"表示nid属性在任何employee节点上必须存在 -->
<attribute name="nid" type="string" use="required"></attribute>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>
~~~
## Java解析XML
Java可以使用DOM、SAX、DOM4j、JDOM等方式解析XML文档,最常用的还是属于DOM4j
DOM4j**jar**包下载地址:[https://dom4j.github.io](https://dom4j.github.io/)
**xml:解析**
~~~java
import java.io.File;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class DOM4jDemo {
public static void main(String[] args) throws Exception {
//1.创建Reader对象
//SAXReader类是读取XML文件的核心类,用于将XML解析后以“树”的形式保存在内容中
SAXReader reader = new SAXReader();
//2.加载xml,获取整个文档的document对象
Document document = reader.read(new File("src/com/ntdodoke/JDBCStudy/hr.xml"));
//3.获取根节点
Element rootElement = document.getRootElement();
//或者采用rootElement.elementText("name")方法输出节点文本值
//创建迭代器准备迭代
Iterator<Element> iterator = rootElement.elementIterator();
while (iterator.hasNext()){
Element stu = iterator.next();
//获取节点的属性
List<Attribute> attributes = stu.attributes();
System.out.println("======获取属性值======");
for (Attribute attribute : attributes) {
System.out.println(attribute.getValue());
}
System.out.println("======遍历子节点======");
Iterator<Element> iteratorSon = stu.elementIterator();
while (iteratorSon.hasNext()){
Element stuChild = iteratorSon.next();
System.out.println("节点名:"+stuChild.getName()+"---节点值:"+stuChild.getStringValue());
}
}
}
}
~~~
**xml:修改**
~~~java
import java.io.FileOutputStream;
import java.io.OutputStreamWriter;
import java.io.Writer;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Demo4jWriter {
public static void main(String[] args) {
writeXml();
}
public static void writeXml(){
String file = "src/com/ntdodoke/JDBCStudy/hr.xml";
SAXReader reader = new SAXReader();
try {
Document document = reader.read(file);
Element root = document.getRootElement();
Element employee = root.addElement("employee");
employee.addAttribute("nid", "3311");
Element name = employee.addElement("name");
name.setText("李铁柱");
employee.addElement("age").setText("37");
employee.addElement("salary").setText("3600");
Element department = employee.addElement("department");
department.addElement("dname").setText("人事部");
department.addElement("address").setText("数字大厦-B105");
Writer writer = new OutputStreamWriter(new FileOutputStream(file) , "UTF-8");
document.write(writer);
writer.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
~~~
## XPath路径表达式
**XPath**即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。
XPath路径是XML文档中查找数据的语言,掌握XPath可以极大的提高在提取数据时的开发效率。
学习XPath本质就是掌握各种表达式的使用技巧。
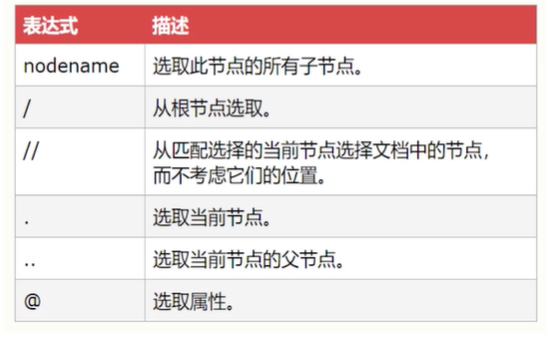
**XPath基本表达式**
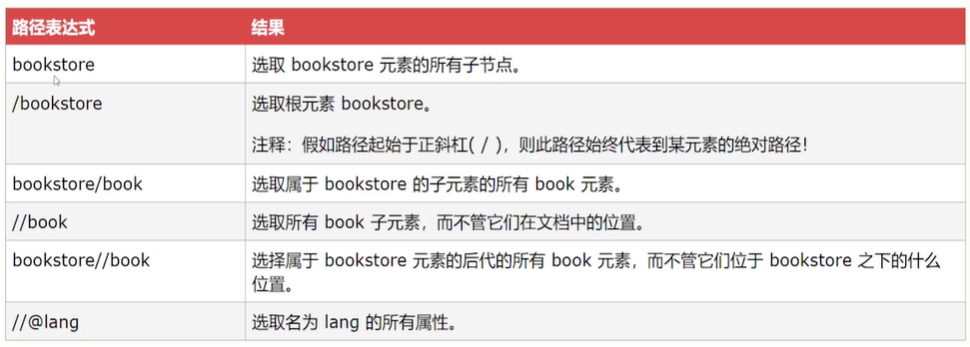
**XPath基本表达式使用案例**
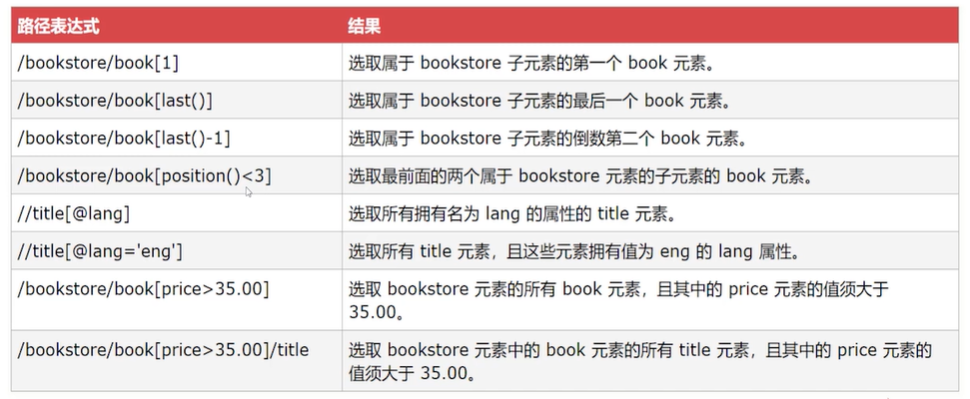
**XPath谓语表达式**
**Jaxen介绍:**
Jaxen是一个Java编写的开源的XPath库,能适应不同的不同的对象模型,包括DOM、XOM、DOM4j和JDOM,DOM4j底层依赖Jaxen实现XPath查询。
Jaxen下载地址:[https://maven.aliyun.com/mvn/view](https://maven.aliyun.com/mvn/view)
可以到阿里云的镜像仓库下载想要的jar包
