
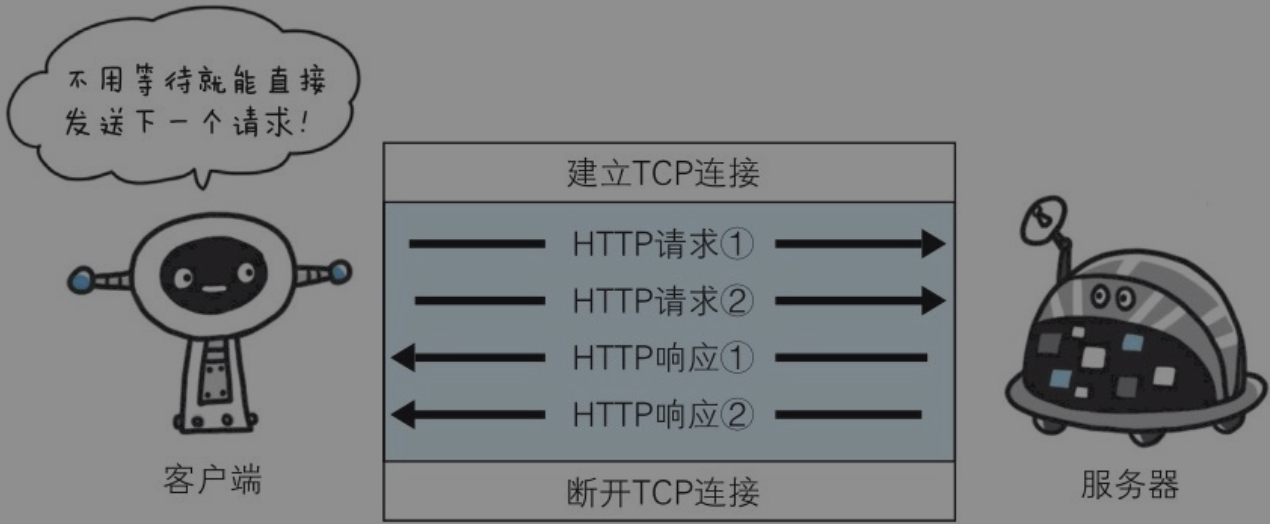
默认情况下,HTTP 请求是按顺序发出的,下一个请求只有在当前请求收到响应之后才会被发出。由于受到网络延迟和带宽的限制,在下一个请求被发送到服务器之前,可能需要等待很长时间。
持久连接使得多数请求以管线化(pipelining)方式发送成为可能。从前发送请求后需等待并收到响应,才能发送下一个请求。管线化技术出现后,不用等待响应亦可直接发送下一个请求
- 概述
- 网络时延
- 进程间通信
- URI
- URL
- URN
- NAT
- 操作系统基础
- 内核
- 用户空间
- 网络协议模型
- 四层网络协议模型
- 链路层
- 以太网协议
- ARP协议
- RARP协议
- MAC地址
- 网络层
- IP协议
- ICMP协议
- 子网掩码
- 传输层
- TCP协议
- TCP慢启动
- TCP性能
- UDP协议
- SCTP协议
- 应用层
- DNS
- TCP/IP协议族
- Socket
- Socket通信模型
- socket和TCP/IP协议族
- Socket三次握手四次挥手
- OSI七层模型
- 物理层
- 数据链路层
- 网络层
- 传输层
- 应用层
- HTTP
- 基础
- HTTP/1.0
- HTTP/1.1
- http2.0
- HTTP报文
- WEB浏览器工作机制
- HTTP事务时延
- HTTP与HTTPS区别
- 持久连接
- 用户验证
- web结构组件
- 代理
- 正向代理
- 反向代理
- 缓存
- 网关
- 隧道-tunnel
- Agent代理
- http协议补充
- Servlet3异步请求
- ajax
- Comet
- WebSocket
- SPDY协议
- HTTP/2
- QUIC
- WebDAV
- http方法
- http连接
- 短连接&长连接
- 管线化
- 网络会话
- cookie
- session
- token
- jwt
- cookie与session的区别
- Spring Session
- 分布式session实现方案
- 同源策略
- 跨域
- CORS
- HTTP三大安全问题
- JWT vs OAuth
- HTTPS
- SSL&TLS
- OpenSSL
- HTTPS和TLS/SSL的关系
- X509标准和PKI
- IO模型
- IO
- I/O模型
- 传统阻塞式I/O
- 非阻塞式I/O
- IO复用
- Connection Per Thread模式
- IO多路复用模型流程
- Reactor模式
- 单Reactor单线程
- 单Reactor多线程
- 主从Reactor多线程
- Proactor模型
- Selector模型
- 信号驱动I/O
- 异步I/O
- select/poll/epoll
- select
- poll
- epoll
- select/poll/epoll适用场景
- 零拷贝原理
- 读取文件发送网络内存拷贝
- 零拷贝
- Netty零拷贝
- 密码学
- 密码学Hash算法分类
- 加密算法
- 对称加密
- 非对称加密
- 数字签名
- RSA数字签名算法
- DSA数字签名算法
- 数字证书
- MAC算法
- web安全
- CSRF攻击
- XSS
- cookie劫持
- SQL注入
- DDos攻击
- 常见面试题
- 浏览器工作机制和原理
- XSS如何预防
- 如何防止cookie被劫持
- 附录
- HTTP状态码
- 常用的网络端口