[TOC]
## 1.概念
**分类**(classification)是通过对具有类别的对象的数据集进行学习,概括其主要特征,构建分类模型,根据该模型预测对象的类别的一种数据挖掘和机器学习技术。
## 2.模型的误差
* 误差(error):模型的实际预测输出与样本的真实输出之间的差异
* 训练误差(training error)或经验误差( empirical error):模型在训练集上的误差
* 泛化误差( generalization error):在新样本上的误差
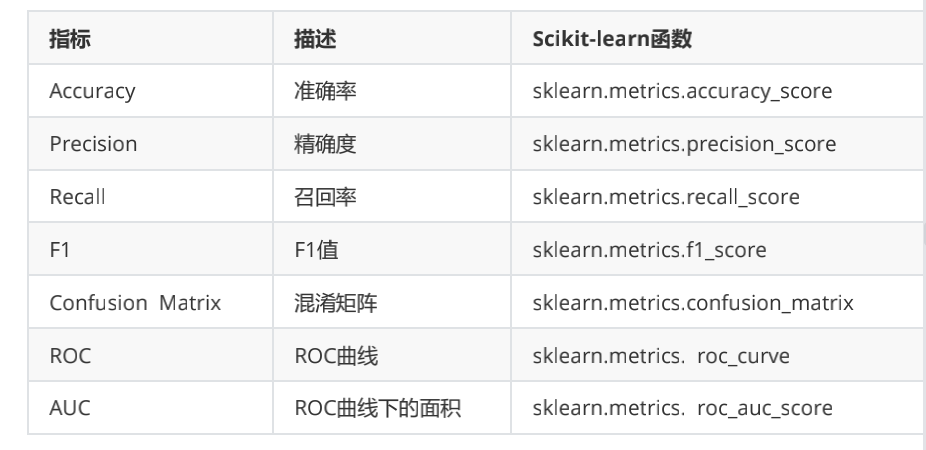
## 3.分类的评估
* **混淆矩阵**

* **准确率**(Accuracy): 衡量所有样本被分类准确的比例
Accuracy=(TP+TN)/(TP+FP+TN+FN)
* **精确率**(Precision): 也叫查准率,衡量正样本的分类准确率,就是说被预测为正样本的样本有多少是真的正样本。
Precision=TP/(TP+FP)
* **召回率**(Recall):表示有多少正样本被准确识别
Recall=TP/(TP+FN)
* **F1-score**:精确率和召回率的调和平均
2/F\_1 =1/P+1/R⇒F\_1 = 2PR/(P+R) = 2TP/(2TP+FP+FN)
* **roc曲线**(Receiver Operating Characteristic,接受者操作特征曲线),指在特定刺激条件下,以被试者在不同判断标准下所得的误报率FPR为横坐标,以击中率TPR为纵坐标,画得的各点的连线,是一种评价分类模型的可视化工具.
1. 横坐标是FPR(False Positive Rate)或称误报率: FPR = FP/(TN+FP)
2. 纵坐标是TPR(True Positive Rate)或称召回率: TPR = TP/(TP+FN)
* **AUC**(Area Under Curve)表示ROC曲线下方的面积,可以对模型的好坏进行量化
## 4.数据集的划分

* 训练数据集(train dataset):用来学习的样本集,用于模型参数的拟合。
* 验证数据集(validation dataset):用来调整模型超参数的样本集,如在神经网络中选择隐藏层神经元的数量。
* 测试数据集(test dataset):用于对已经训练好的模型进行性能评估的样本集,用来评估最终模型的泛化能力。但不能作为调参、选择特征等算法相关的选择的依据。
### **1)划分**
* model\_selection.train\_test\_split
### **2)K折交叉验证:**
* cross\_val\_score
### **5.过拟合问题**
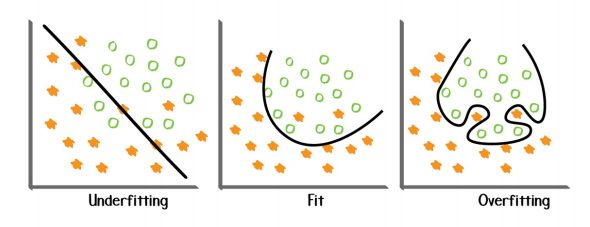
* 过拟合:做的太过好以至于偏离了原本,泛化能力差
1. 可能的原因:
* 使用的模型比较复杂,学习能力过强
* 有噪声存在
* 数据量有限
2. 过拟合解决方式:
* 交叉验证
* 及时终止(当验证集上的效果变差的时候)
* 找到更多的数据
* 寻找最优参数
* 增大正则化系数:正则化是指人为地迫使模型变得更简单的一系列技术
* 删除无用特征
* 集成学习
* 欠拟合:泛化能力强,但过于泛化
1. 可能的原因:使用的模型过于简单
2. 解决办法:
* 找到更多的特征
* 减少正则化系数
* 从一个非常简单的模型开始,以此作为基准
**Sklearn中提供的相应方法:**
* 网络搜索:model_selection. GridSearchCV
* 寻找训练集大小:学习曲线model_selection. learning_curve
* 寻找参数的最优:验证曲线model_selection. validation_curve
### **6. KNN**
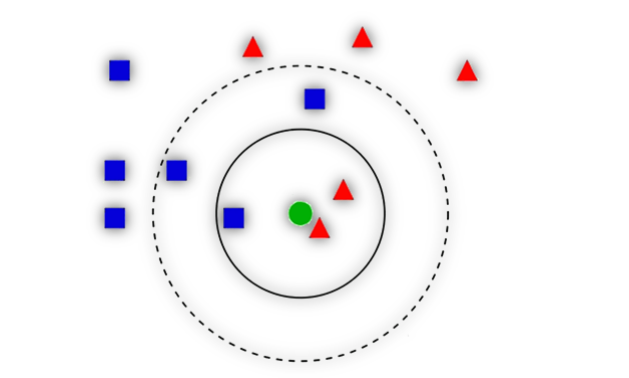
距离的度量
**1).算法描述**
**2)优缺点**
**3)变种**
* 加权KNN:增加邻居的权重,比如距离越近权重越高。
* RadiusNeighbors:使用一定半径内的点取代距离最近的k个点
**4) sklearn提供的方法**
* neighbors. KNeighborsClassifier
* neighbors. RadiusNeighborsClassifier
### 7.决策树
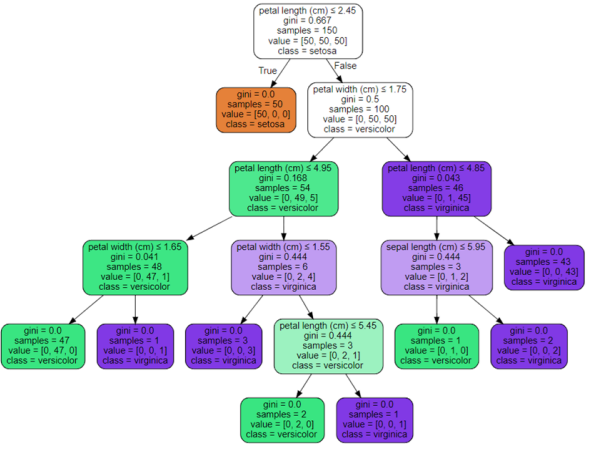
**1)核心:**
* 选哪个特征进行分裂以及如何分裂
* 如何让树停止生长
**2)算法:**
* ID3 <==>信息增益:事件中某一影响因素的不确定性度量对事件信息不确定性减少的程度,即得知特征X的信息而使得类Y的信息不确定性减少的程度。
* C4.5 <==>信息增益率
* CART <==>基尼指数
**3)sklearn中的方法:**
* tree.DecisionTreeClassifier
### 8.朴素贝叶斯
朴素贝叶斯算法(Naive Bayes)是基于贝叶斯定理与特征条件独立假设的分类方法。
**1)朴素贝叶斯的工作过程**
(1)设D是训练元组和它们相关联的类标号的集合。通常,每个元组用一个n维属性向量X={x_1,x_2,…,x_n}表示,描述由n个属性对元组的n个测量。
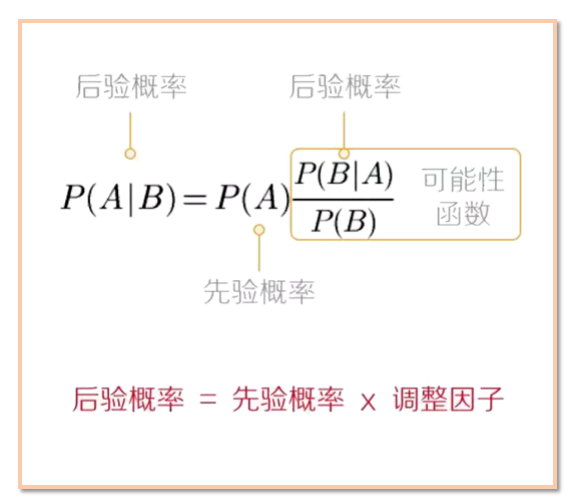
(2)假定有m个类y\_1,y\_2,..., y\_m。给定元组X,分类法将预测X属于具有最高后验概率的类(在条件X下)。P(y\_i |X) = (P(X|y\_i)P(y\_i))/(P(X))由于P(X)对所有类为常数,所以只需要P(X│y\_i )P(y\_i )最大即可。
(3)给定具有许多属性的数据 集,计算P(X│y\_i )的开销可能非常大。为了降低P(X│y\_i )的开销,可以做**类条件独立**的朴素假定。给定元组的类标号,假定属性值条件地相互独立(即属性之间不存在依赖关系)。因此
P(X│y\_i ) =∏\_(k=1)^n▒〖P(〗x\_k |y\_i) = P(x\_1 |y\_i) P(x\_2 |y\_i)∙∙∙P(x\_n |y\_i)
(4)该分类算法预测输入元组X的类为y\_i,当且仅当P(X|y\_i)P(y\_i) > P(X|y\_j)P(y\_j) 1≤j≤m, j≠i
**2)优缺点**
**3)分类**
* 多项式模型: naive_bayes.MultinomialNB
* 补集朴素贝叶斯: naive_bayes.ComplementNB (是标准多项式朴素贝叶斯算法的改进。该算法能够解决样本不平衡问题,并且能够一定程度上忽略朴素假设的补集朴素贝叶斯。)
* 高斯模型: naive_bayes.GaussianNB
* 伯努利模型: naive_bayes.BernoulliNB
### 9.支持向量机
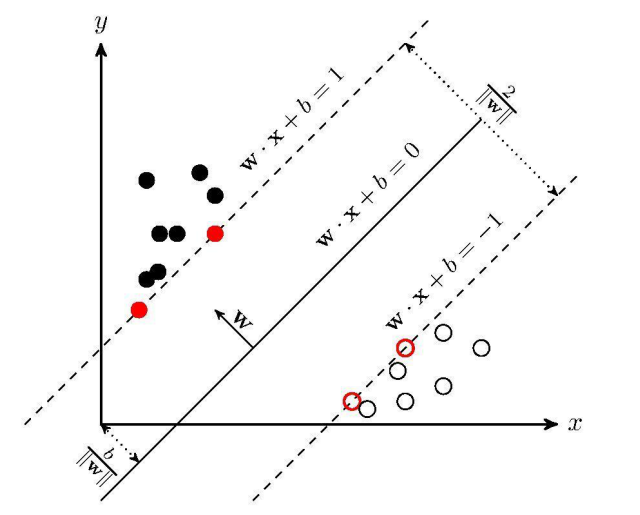
支持向量机(support vector machines)是一种二分类模型,它的目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化,最终转化为一个凸二次规划问题来求解:
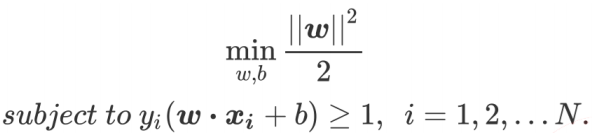
**1)三种情况**
* 线性可分
* 近似线性可分:引入松弛变量
* 线性不可分:引入核函数
**2)svm.SVC**
