
# :-: Large-scale cluster management at Google with Borg
此文主要介绍kubernetes的前生borg,主要涉及borg的主要架构与特性,重要的设计并在多年的google经营中学到的经验,borg的优缺点,以及哪些方面被kubernetes继承。
原文链接 [https://research.google/pubs/pub43438/](https://research.google/pubs/pub43438/)
这篇文章目前有不少地方仍然不能理解,后续会持续更新。
*****
本文摘录与记录对于这篇文章的学习。
###
## **1 Introduction**
Borg提供的主要特性有以下三点:
1.隐藏资源管理和错误处理的细节让用户能够专注于应用的开发。
2.具有很高的可靠性与可用性。同时支持应用程序的复用。
3.能够在大规模机器上同时负载。
:-: 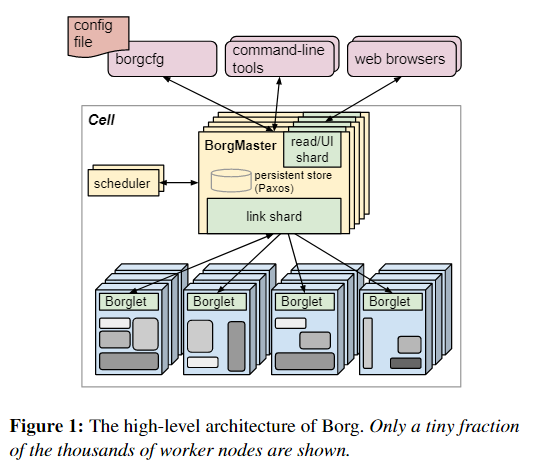
## :-: **borg架构图**
在Borg中,将高优先级Borg job作为“production”(**prod**),剩下的就作为non-production”(**non-prod**).大多数长时间运行的服务都作为prod。在一个典型的cell中,prod job被分配了大约70%的CPU资源和大约60%的CPU使用量;它们大约占据了总内存的55%,占据了总内存使用的85%。分配和使用之间的差异将被证明是重要的。一个中等的cell大于有10K的机器,jobs可以强制指定到特定的os,处理器架构。
\*\*Allocs:\*\*指那些可以被用于运行的资源集合。Alloc可用于为将来的任务留出资源,在停止任务和重新启动任务之间保留资源,并将来自不同作业的任务收集到同一台机器上创建分配集后,可以提交一个或多个作业在其中运行。简洁起见,我们通常会使用“job”来指代分配或顶级任务,使用“tesk”来指代alloc集。
## **2.1 Priority, quota, and admission control**
每个作业都有优先级,一个小的正整数。高优先级的任务可以以较低优先级的任务为代价获得资源,即使这涉及抢占(杀死)后者。配额的标签包括:moni-toring,production,batch, andbest effort(also known astestingorfree)。prod jobs属于monitoring 与productionbands。优先级表示在单元格中正在运行或等待运行的作业的相对重要性。配额用于决定允许哪些作业进行调度。配额表示为一段时间(通常为数月)内具有给定优先级的资源数量(CPU,RAM,磁盘等)的向量。数量指定了用户的作业请求一次可以请求的最大资源量(例如,“从现在到7月下旬,cell中的内存为20 TiB”)。配额检查是准入控制的一部分,而非调度:配额不足的作业会在提交后立即被拒绝
## **2.2 Naming and monitoring**
为了能够在重新分配新的机器后找到新的prod,borg为每一个任务创建一个“Borg name service” (BNS),其中包括cell name, job name, and task number,Borg将任务的主机名和端口写到Chubby中名称一致的,高度可用的文件中被使用到RPC系统去找到endpoint。BNS名称也构成了DNS名称的基础。Borg还会在任务发生变化时将任务大小和任务运行状况信息写入到chubby中,这样负载平衡器就可以知道将请求路由到哪里。Borg监视运行状况并检查URL,并重新启动无法及时响应或返回HTTP错误代码的任务。
一项名为Sigma的服务提供了一个基于Web的用户界面(UI),用户可以通过该界面检查所有作业,特定单元的状态,或者向下钻取到各个作业和任务以检查其资源行为,详细的日志,执行历史记录,以及最终的结果。Borg在Infrastore中记录所有作业提交和任务事件,以及每个任务的详细资源使用信息,Infrastore是可扩展的只读数据存储,具有通过Dremel的类似SQL的界面进行交互。
### **2.2.1 Borg architecture**
Borg的所有组件都是用C++编写的。每个单元的Borgmaster包含两个进程:主 Borgmaster进程和单独的调度程序。Borgmaster主进程处理客户端RPC,这些RPC会更改状态(例如,创建作业)或提供对数据的只读访问权限(例如,查找作业)。Borgmaster主进程处理客户端RPC,这些RPC会更改状态(例如,创建作业)或提供对数据的只读访问权限(例如,查找作业)。它还为系统中的所有对象(机器,任务,分配等)管理状态机,与Borglets通信,并提供Web UI作为Sigma的备份。从逻辑上讲,Borgmaster是一个单一的过程,但实际上被复制了五次。每个副本都维护该单元大多数状态的内存副本,并且此状态副本也记录在基于Paxos的分布式,高可用性,本地磁盘存储中。单个cell serves的elected master同时作为Paxos leader与state mutator。处理更改cell状态的所有操作,例如提交作业或终止机器上的任务。
Borg在某个时间点的状态称为检查点,其形式为定期快照以及保存在Paxos存储的变更日志。检查点有许多用途,包括将Borgmaster的状态恢复到过去的任意点(例如,在接受触发Borg中的软件缺陷的请求之前,以便可以对其进行调试);通过手工操作端对它进行修复;建立事件的持久日志以供将来查询;和离线模拟。
Borg可以使用称为Fauxmaster的高保真Borgmaster模拟器读取检查点文件,并创建完整的生产环境Borgmaster代码副本,并带有连接到Borglets的接口。它接受RPC进行状态机更改并执行诸如“计划所有待处理的任务”之类的操作,并且我们通过与RPC进行交互,就好像它是一个实时的Borgmaster一样,使用它来调试故障,通过Borglets的模拟可以从中重放真实的交互用户,单步执行并观察过去实际发生的系统状态更改。 Fauxmaster还可以用于容量规划(“可以容纳多少个此类型的job?”),以及在对单元的配置进行更改之前进行完整性检查(“此更改会淘汰重要的工作吗?”)。
## **3.1 Scheduling**
提交作业后,Borgmaster将其持久地记录在Paxos存储中,并将该作业的任务添加到挂起队列中。调度程序将对其进行异步扫描,如果有足够的可用资源满足任务的约束,调度程序会将任务分配给计算机。(调度程序主要用于执行任务,而不是工作。)扫描从高优先级到低优先级,并由优先级内的循环机制进行调制,以确保各个用户之间的公平性,并避免在处理大量工作后出现行头阻塞。调度算法包括两部分:可行性检查,查找可以在其上运行任务的机器,以及评分,以选择可行的机器。在可行性检查中,调度程序会找到一组满足任务约束且具有足够“可用”资源的机器,其中包括分配给可以撤出的低优先级任务的资源。
## **3.2 Borglet**
Borglet是本地Borg agent,它存在于cell的每台计算机上。它启动和停止任务;如果它们失败,则重新启动它们;通过操纵OS内核设置来管理本地资源;滚动调试日志;并向Borgmaster和其他监控系统报告机器的状态。Borgmaster每隔几秒钟会轮询每个Borglet,以检索计算机的当前状态并向其发送任何异常请求。这Borgmaster可以控制通信速率,避免了需要明确的流量控制机制,并防止了恢复风暴。The elected master负责准备消息发送到borglet和更新cell的状态与他们的响应。为了实现性能可伸缩性,每个borgter副本运行一个stateless link分片来处理与一些Borglets的通信;只要发生Borgmaster election,分区就会重新计算分区。为了提高弹性,Borglet总是报告它的完整状态,但是链接碎片通过只向状态机报告差异来聚合和压缩这些信息,以减少在所选主服务器上的更新负载。
如果Borglet不响应多个轮询消息,则其计算机将标记为已关闭,并且正在运行的所有任务都将在其他计算机上重新安排。如果恢复了通信,则Borgmaster会通知Borglet取消已重新安排的任务,以避免重复。即使失去与Borgmaster的联系,Borglet也会继续正常运行,因此,即使所有Borgmaster副本均失败,当前正在运行的任务和服务也将保持正常运行。
## **3.3 Scalability**
我们不确定Borg集中式架构的最终可扩展性限制将来自何处;到目前为止,每次达到极限时,我们都设法消除了极限。单个Borgmaster可以在一个单元中管理成千上万的机器,并且几个单元的任务每分钟超过10000个。繁忙的Borgmaster使用10–14CPU和多达50 GiB RAM。我们使用多种技术来达到这一规模。
几个事情使Borg调度程序更具可扩展性:
### **分数缓存**: 评估可行性并为机器评分是耗费昂贵的,因此Borg会缓存分数,直到机器的属性或任务发生变化–例如,机器上的任务终止,属性被更改或任务的需求变化。忽略资源数量的微小变化可减少缓存失效。
### **等价类**:Borg作业中的任务通常具有相同的要求和约束,因此,不是确定每台机器上每个待处理任务的可行性,并为所有可行机器评分,在具有相同要求的一组任务中。Borg对每一个等价类中的一个任务进行评分。
### **宽松的随机化**:计算大型单元中计算所有计算机的可行性和分数是浪费的,因此调度程序会以随机顺序检查计算机,直到找到“足够”的可行计算机进行评分,然后在该集合中选择最佳计算机。这减少了任务进入和离开系统时所需的评分和缓存失效数量,并加快了任务向计算机的分配。
## **4\. Availability**
:-: 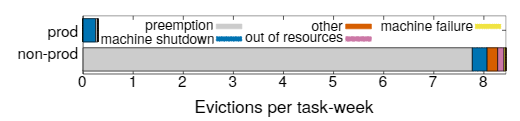,
失败是大型系统中的常态。图3提供了15个样本单元中任务逐出原因的分解。Borg提供了处理失败事件的操作,使用例如republication,持久化存储在分布式系统中,如果合适的话,偶尔设置Checkpoint,即使如此,我们仍然尝试减轻这些事件的影响,例如,如有必要,
•自动在新的机器上重新安排已退出的任务
•通过在整个故障域(如机器,机架和电源域)中分散作业从而减少相关的故障避免重复导致任务或机器崩溃的
•在诸如OS或机器升级之类的维护活动中限制允许的任务中断率和作业中的任务数量
•使用声明的期望状态表示和等效幂等变操作,以便失败的客户端可以无害地重新提交任何忘记的请求
•避免重复导致任务或机器崩溃的task :: machine配对;
•通过重复地重新运行一个日志保护程序任务来恢复写入到本地磁盘的中间数据(§2.4),即使它附加的alloc被终止或移动到另一台机器。用户可以设置系统持续尝试的时间,通常是几天。
Borg的一个关键设计特点是,即使Borgmaster或某个任务的Borglet宕机,已经运行的任务仍能继续运行。但是保持主服务器正常运行仍然很重要,因为当它宕机时,不能提交新的作业或更新现有的作业,来自失败机器的任务不能重新调度。Borgmaster使用了使it在实践中实现99.99%可用性的技术组合:机器故障复制;准入控制以避免任务过载;使用简单的底层工具部署实例来最小化额外的依赖。每个单元独立于其他单元,以尽量减少相关操作符错误和故障传播的机会。这些目标,而不是可限制伸缩性,是大型cell的关键。
## **5\. Utilization**
Borg的主要目标之一是有效利用谷歌的机器,这是一项重大的金融投资:提高几个百分点的机器利用率可以节省数百万美元。本节讨论和评估了Borg在这方面所采用的一些政策和技术。
## 5.1 Evaluation methodology
我们job有部署条件,同时需要处理罕见的工作量高峰,我们的机器是异构的,并且我们从service jobs回收的资源中继续run batch job。因此,要评估我们的方案选择,我们需要一个比“平均利用率”更复杂的指标,在经过了大量的实验后,我们选择了cell compaction:给定一个工作负载,given a workload,we found out how small a cell it could be fitted into by removing machines until the workload no longer fitted, re-peatedly re-packing the workload from scratch to ensure thatwe didn’t get hung up on an unlucky configuration. This provided clean termination conditions and facilitated auto-mated comparisons without the pitfalls of synthetic work-load generation and modeling . A quantitative compari-son of evaluation techniques can be found in \[78\]: the detailsare surprisingly subtle.
不可能在实际的生产环境中做这些测试,但是我们使用Fauxmaster来高保真的模拟结果,采用从实际生产环境的cell与工作负载,同时包括他们的限制性条件,实际限制,reservations,以及使用数据,该数据来自PDT 2014年10月11日星期三获取的Borg Checkpoint。我们首先淘汰了专用,测试和小型(<5000台计算机)单元,从而选择了15个Borg单元进行报告,然后对剩余的总体进行抽样,以实现在大小范围内的平均分布。为了保持compacted cell的机器异质性,我们随机选择要移除的机器。为了维持工作负载的heterogeneity。我们保留了全部,除了与特定计算机绑定的服务器和存储任务外。那些超过cell数量一半大的job,我们将硬约束改为条件改为了软约束条件。如果job非常“挑剔”且只能放置在少数机器上,则允许最多0.2%的任务处于pending状态,广泛的是试验之后表明这样会产生低变动性的重复结果;if we needed a larger cell than the original we cloned the orig-inal cell a few times before compaction; if we needed morecells, we just cloned the original。
### 5.2 Cell sharing
:-: 几乎我们所有的机器都同时运行prod和non-prod任务,98%的机器是共享Brog cell的,Borg管理了整个集合的83%的机器,剩下一些为专用单元特殊用途,因为许多其他的组织在分离的集群中运行user-facing 和batch jobs,我们研究了同时做这些事情会发生时什么。图五展示了在mdeian cell中分离prod与non-prod的工作将会需要20%-30%的额外机器去负载,这是因为prod jobs通常保留资源为了处理少见的负载峰值。但大多数时间这些资源又是没有使用的,Borg回收了未使用的资源(第5.5节)来运行大部分非产品,因此我们总体上需要的机器更少。大多数的Brog cell由成千上万的用户共享,图6展示了为什么,对于这个测试,如果用户消耗了至少10 TiB的内存(或100 TiB),我们会将用户的工作负载划分到一个新的单元中。我们现有的政策看起来不错:即使阈值较大,我们也需要2-16倍的cell,和20–150%的额外机器。再一次表明,合并资源可大大降低成本。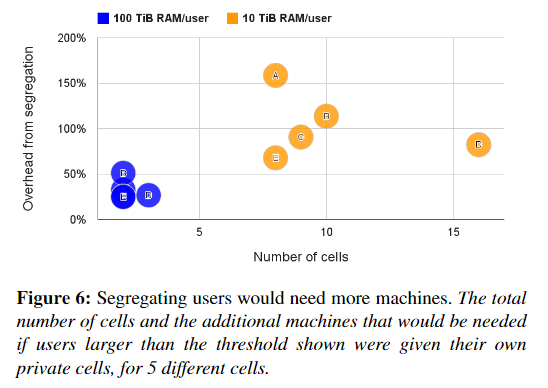
但是也许将不相关的用户和作业类型打包到同一台计算机上会导致CPU干扰,因此我们将需要更多的机器来补偿,为了对此进行评估,我们研究了在相同环境下以相同时钟速度运行的不同环境中的任务的CPI(每条指令的周期数)如何变化。在这些条件下,CPI的值拥有可比性,and can be used as a proxy for performance interference(可以被作为性能被干扰的指标?),因为将CPI加倍会使CPU绑定程序的运行时间加倍。这些数据为在一周内从大约12000个随机的pod任务中收集。使用以下所述的硬件配置基础结构,在5分钟的间隔内对周期和指令进行计数,并加权样本,以便对CPU时间的每一秒进行平均计数。结果并不明确。
(此处粗省略一大段不会的论证资料;<)
这些实验证实,在仓库规模上进行性能比较是棘手的,这增强了\[51\]中的观点,并且还表明共享并不会显着增加运行程序的成本。
但是即使假设我们的结果是最不利的,共享仍然是一种制胜法宝:he CPU slowdown is outweighed by thedecrease in machines required over several different parti-tioning schemes,(在几种不同的分区方案下,所需的机器数量减少,而CPU的速度降低却无法弥补,),并且共享优势应用到了所有资源,包括内存和磁盘,而不仅仅是CPU。
5.3 Large cells
Google建立了大型cell,并且允许运行大型计算,并减少资源分散,We testedthe effects of the latter by partitioning the workload for a cellacross multiple smaller cells – by first randomly permutingthe jobs and then assigning them in a round-robin manneramong the partitions.(机翻:我们通过跨多个较小的单元划分一个单元的工作负载来测试后者的效果-首先随机排列作业,然后以循环方式在分区之间分配它们。)图7证实使用较小的cell将需要更多的计算机。
:-: 
### 5.4 Fine-grained resource requests
Borg用户要求以毫核心为单位的CPU,和内存以及磁盘空间(以字节为单位),一个核心是处理器超线程,针对各种机器类型的性能进行了标准化。图8显示了他们利用了这种粒度:请求的内存或CPU核心数量有少数明显的“最佳点”,这些资源之间几乎没有明显的相关性。这些分布与\[68\]中的分布非常相似,除了我们看到90%以上的内存请求稍微大一些.
提供一组固定大小的容器或虚拟机,尽管在IaaS(基础设施即服务)提供商中很常见(待完成)
### 5.5 Resource reclamation
一个job可以指定一个资源限制,每个人物可以被授予的资源上限,这个限制被Borg用来确定用户是否有足够的配额来接受这份工作,同时决定,如果一个特殊的机器有足够的空闲资源去安排任务,就像有些用户购买的配额超出了他们的需求一样,这些用户请求的比他们任务使用的要少,因为Borg通常会终止试图使用比其请求更多的RAM或磁盘空间的任务,or throttle CPU to what itasked for.此外,某些任务有时需要使用所有资源(在一天中的高峰时段或在应对拒绝服务攻击时),但大多数时候都不是这样。
与其浪费当前没有被消耗的分配资源,我们估算一个任务会使用多少资源同时回收剩余的资源
用来运行低质量的任务,例如批处理作业,这整个过程称为资源回收。这种估算称为任务的保留(task‘s reservation),由Borg-master几秒钟计算一次。使用Borglet捕获的细粒度(资源消耗)信息。初始reservation被设置为等于资源请求(the limit);在300秒之后。考虑到启动瞬态
to allow for startup transients, it decays slowly towards the actual usage plus a safety margin. The reserva-tion is rapidly increased if the usage exceeds it.
Borg调度器使用Limit去计算prod 任务的可行性,因此他们从不依赖回收资源,也不会面临资源超额订购的情况,对于non-prod任务,他使用已有任务的reservation因此新任务可以调度到回收资源上。
如果对于reservation的预测错误的话,一台机器在运行时可能会用尽资源,即使所有任务的使用小于限制,如果这种情况发生,我们选择kill或者限制non-prod任务,但从来不是pods。
图10显示,如果没有资源回收,将需要更多的机器。在median cell中,大约有20%的工作负载run在回收资源中。
我们可以在图11中看到更多的细节,它显示了预订和使用限制的关系。如果需要资源,超过内存限制的任务将首先被抢占,而不管它的优先级如何,因此任务很少超过它们的内存限制。另一方面,CPU可以很容易地被调节,所以短期的峰值可以将使用推高到保留水平,这是无害的。
图11表明资源回收可能过于保守:在reservation跟usage line之间有明显的区域。为了测试这个,为了测试这个,我们选择了一个生产环境的cell并且调整了资源估计算法的参数到一个更为激进的设置,通过减少安全边际来维持了一周,而后另一周调整到一个中等设置介于baseline与激进设置之间。最后又条件回到baseline。图13展示了发生可什么,在第二个week里面reservations非常接近于usage。而在第三周则有所减少,最大的差距显示在baseline周里面,1st与4st,正如预期的那样,内存不足(OOM)事件的发生率在第2周和第3周略有增加。在审查了这些结果之后,我们认为净收益超过了不利因素。并部署了medium资源回收参数到其他cell。
:-: 
##
6.Isolation
我们有50%的计算机运行9个或更多任务;一台90%的机器大约有25个任务,将运行约4500个线程\[83\]。尽管在应用程序之间共享计算机可以提高利用率,但是它也需要良好的机制来防止任务之间的相互干扰。这影响到安全性和性能。
6.1 Security isolation
我们使用Linux chroot jail作为同一台计算机上多个任务之间的主要安全隔离机制。为了允许进行远程调试,我们曾经自动分发(和撤消)sshkey,以使用户只能在机器正在为用户运行任务时访问它。对于大多数用户而言,它已被borgssh命令所取代,该命令与Borglet协作以构建与该任务在同一chroot和cgroup中运行的shell的ssh连接,从而更紧密地锁定访问。
通过google的Google’s AppEngin与Google Compute Engine (GCE).采用VM与安全沙箱技术来运行外部软件。在一个KVM进程当中我们运行每一个宿主VM,这被作为Borg task来运行。
6.2 Performance isolation
Borglet的早期版本具有相对原始的资源隔离实施:对内存,磁盘空间和CPU周期进行事后使用检查,再加上终止使用过多内存或磁盘的任务,以及积极使用Linux的CPU优先级来遏制过分使用很多CPU。但是,流氓任务仍然很容易影响计算机上其他任务的性能,因此某些用户夸大了他们的资源请求,以减少Borg可以与他们共同调度的任务数量,从而降低了利用率。资源回收可以收回部分盈余,但由于涉及安全边际,因此不能全部收回。在最极端的情况下,用户请愿使用专用机器或单元.
现如今,所有的Borg任务都运行在一个Linux cgropu-based 资源容器上,Borglet操作容器设置,由于操作系统内核在循环中,所以提供了更好的控制,即使如此,偶尔还是会发生低级资源干扰(例如,内存带宽或L3缓存污染),如\[60,83\]。
为了解决超负荷以及过度使用的问题,Brog任务有一个应用class or appclass,appclasses与其他的最重要的区别是延迟敏感性,在这偏文章中我们把它叫做batch,LS任务用于需要快速响应请求的面向用户的应用程序和共享基础结构服务。高优先级LS任务会受到最高的待遇。并有能力饿死bach任务几秒钟。第二个分离是在资源的可压缩上,(例如,CPU周期,磁盘I / O带宽)这些都是基于速率的可以通过降低服务质量回收而不会kill掉。不可压缩资源(例如内存,磁盘空间),这些资源除通常不能回收除非kill掉任务。如果一台机器耗尽了不可压缩资源,Borglet将会迅速的终止任务,从最低优先级到最高优先级,直到剩下的reservation可以满足为止,如果机器耗尽了可压缩资源,Borg将会限制用量(多数在LS任务上)以便于处理负载峰值而不用kill掉任何任务。如果事情没有好转,Borgmaster 将会从机器中移除一个或更多的任务。
Borglet中的用户空间控制循环根据预测的未来使用(for prod task)或内存压力(for non-prod ones)将内存分配给容器,处理来自内核的内存不足实践,同时当他们尝试分配超过他们自身的内存限制时,kill掉。或者当一台机器over-committed(过度承诺)但实际上却已经耗尽了内存,由于需要精确的内存计算,Linux迫切需要的文件缓存极大地复杂了这个实现。
为了提高性能隔离,延迟敏感类任务可以保留整个物理CPU核心,这将会停止其他延迟敏感性任务使用。Batcg 类任务允许在任何一个核心上运行。但是,相对于延迟敏感型任务,他们被赋予了更小的调度程序份额。Borglet动态的调整延迟敏感型资源去确保他们在数分钟内不会使batch 任务挨饿。在需要时选择性的应用CFS带宽控制。共享是不足够的,因为我们有多个优先级级别。
像Leverich一样,我们发现标准化的Linux CPU 调度(CFS)需要大量调整以同时支持低延迟与高利用率。为了减少调度延迟,我们的CFS版本使用采用per-cgropu加载记录,允许延迟敏感性任务抢占batch任务。当多个LS任务在CPU上运行时,减少调度量。幸运的是,我们的许多应用程序采用thread-per-request模型。减轻了持续负载不平衡的影响。我们很少使用CPUset将CPU内核分配给延迟要求特别严格的应用程序。图13显示了这些结果的效果。在这方面的工作还在继续,添加线程放置和CPU管理,即NUMA,超线程和功耗感知,并提高Borglet的控制精度。
任务被设置为允许消耗达到最大限值。他们中的大多数都被允许超越诸如CPU之类的可压缩资源。为了利用未使用的闲置资源。大概只有5%的LS任务禁用了此功能,大概是为了获得更好的可预测性。不到批处理任务的1%。默认情况下是禁用闲置资源的。因为它增加了任务被kill掉的概率。但即使如此,10%的LS任务重写了这个,以及79%的batch任务这样做了,因为这是一个mapreduce框架的默认设置。这补充了回收资源的结果(§5.5)。batch 任务愿意使用未被使用的以及回收的资源机会。在大多数情况下,这是可行的,尽管当LS任务急需资源时,偶尔的批处理任务会被牺牲掉。
1. Related work
资源调度已经研究了数十年,涉及范围广泛,例如广域HPC超级计算网格,工作站网络和大型服务器集群。在此,我们仅关注大型服务器集群中最相关的工作。
最近的几项研究追踪了来自yahoo,Google,facebook的集群。并说明了这些现代数据中心和工作负载固有的规模和异构性挑战。包含集群管理器架构的分类。
Facebook的Tupperware \[64\]是一种类似于Borg的系统,用于在群集上调度cgroup容器;尽管似乎提供了资源回收的一种形式,但仅公开了一些细节。 Twitter开源了aurora \[5\],这是一种类似于Borg的调度程序,用于在Mesos之上运行的长期运行的服务,其配置语言和状态机类似于Borg。
Apache Mesos 使用基于报价的机制在中央资源管理器(类似于Borgmaster减去其调度程序)和诸如Hadoop \[41\]和Spark \[73\]的多个“框架”之间划分资源管理和放置功能。(不得不感叹,google的翻译太强了。。)Borg主要使用一种可伸缩的基于请求的机制来集中这些功能。DRF最初是为了Mesos开发的。Borg使用优先级与权限配额。Mesos开发者已经宣布扩展Mesos的雄心,去包括推测性资源分配与回收。以及修理一些已知的问题。
YARN是一个hadoop-centric集群管理器,每一个应用有一个manager,负责与中心资源管理器协商所需的资源。这跟google的map reduce jobs从Borg获取资源很类似。YARN的资源管理最近变得。。。。。YARN最近被扩展去支持多种资源类型,抢占,和高级任务控制,The Tetris research prototype \[40\] supports makespan-awarejob packin。
facebook的Tupperware,是一个类Borg系统,用于在cluster上调度cgroup容器,仅仅只有少数的细节披露了,尽管他似乎提供了资源回收的一种形式,twtter开源了Aurora,一个运行在Mesos上的用来长时间运行services的类Borg调度器。跟Borg的声明式语言与机器状态类似。
微软的Autopilot系统提供自动配置软件与部署。系统监测,并且采用修复措施去处理软硬件错误。Borg同时提供了相似的功能,但这里不进行讨论,Isaard指明了我们所遵循的最佳路线。
阿里巴巴的Fuxi \[84\]支持数据分析工作负载;自2009年以来一直在运行。像Borgmaster一样,中央FuxiMaster(为容错而复制)从节点收集资源可用性信息,接受来自应用程序的请求并进行匹配一个到另一个。 Fuxi增量计划策略与Borg的等价类相反:Fuxi不会将每个任务匹配到一组合适的机器上,而是将新可用资源与待处理工作的积压进行匹配。与Mesos一样,Fuxi允许定义“虚拟资源”类型。只有合成工作负载结果可公开获得
Google的开源Kubernetes系统\[53\]将Docker容器\[28\]中的应用程序放置在多个主机节点上。它既可以在裸机(如Borg)上运行,也可以在各种云托管服务提供商(如Google Compute Engine)上运行,许多构建Borg的工程师都在积极开发中。 Google提供了一个托管版本,称为Google Container Engine \[39\]。下一节我们将讨论如何将来自Borg的课程应用于Kubernetes
最后,正如我们已经指出的那样,管理大型集群的另一个重要部分是自动化和“操作员横向扩展”。 \[43\]描述了如何计划故障,多租户,运行状况检查,准入控制和重启能力,以实现大量的机器操作员。博格(Borg)的设计理念是相似的,它使我们能够为每个操作员(SRE)提供数万台机器。
## 8\. Lessons and future work
在本节中,我们将回顾从运营Borg到生产中十多年中获得的一些定性教训,并描述如何在设计Kubernetes时利用这些观察结果。
8.1 Lessons learned: the bad
我们从Borg的一些经验开始,病态kubernetes中提供了替代的设置。
作业作为任务的唯一分组机制是有限制性的。Borg没有一流的方法来将一个完整的多job service作为一个单独的实体来管理,或者将一个服务的相关实例(例如canary和生产轨迹)加以引用。作为hack,用户将其服务拓扑编码在作业名称中,并构建更高级别的管理工具来解析这些名称。在另一端,另一方面,不可能指代工作的任意子集,这会导致诸如滚动更新和调整工作大小的语义不灵活等问题。
为了避免此类困难,Kubernetes拒绝任务指示,而是使用标签(用户可以将其附加到系统中的任何对象)来组织其调度单位(pod)。可以通过将job:jobname,label附加到一组pod上来完成相当于Borg作业的任务,但是也可以表示任何其他有用的分组,例如服务,层或发布类型(例如,生产,标记,测试) 。 Kubernetes中的操作通过标签查询的方式来确定其目标,该标签查询选择操作应应用于的对象。这种方法比作业的单个固定分组具有更大的灵活性。
每台机器一个IP地址会使事情变得复杂。在InBorg中,计算机上的所有任务都使用其主机的单个IP地址,从而共享主机的端口空间。这带来了许多困难:Borg必须安排端口作为资源;任务必须预先声明它们需要多少个端口,并愿意在启动时被告知要使用哪些端口; Borglet必须强制执行端口隔离;并且命名和RPC系统必须处理端口以及IP地址。
由于Linux名称空间,VM,IPv6和软件定义的网络的出现,Kubernetes可以采用更加用户友好的方法来消除这些复杂性:每个pod和服务都有其自己的IP地址,从而使开发人员可以选择端口而不是要求它们的软件可以适应基础架构选择的软件,并消除了管理端口的基础架构复杂性。
以牺牲普通用户为代价优化高级用户。Borg提供了一套针对“超级用户”的功能,这样他们就可以微调他们程序的运行方式(BCL规范列出了大约230个参数):最主要的关注点是支持谷歌最大的资源消费者,对他们来说效率提高是最重要的。这个API的丰富性使“随意”用户的工作变得更加困难,并且限制了它的发展。我们的解决方案是构建自动化工具和服务,运行在Borg之上,并从实验中确定适当的设置。这些得益于容错应用程序所提供的实验自由:如果自动化造成错误,那将是令人讨厌的,而不是灾难。
## 8.2 Lessons learned: the good
另一方面,Borg的许多设计功能非常有益,并且经受了时间的考验。
\*\*Allocs很有用。\*\*Borg alloc抽象产生了广泛使用的logaver模式(第2.4节),而另一个流行的模式是简单的数据加载器任务定期更新Web服务器使用的数据。 Alloc和软件包允许由单独的团队开发许多帮助服务。Kubernete的pod相当于alloc(分配器),它是一个或多个容器的封装源,这些容器总是安排在同一台机器上并且可以共享资源。Kubernetes在同一容器中使用辅助容器而不是在alloc 中的任务,但是想法是相同的。
\*\*集群管理不仅仅是任务管理。\*\*尽管博格的主要职责是管理任务和机器的生命周期,但运行在博格上的应用程序可以从许多其他集群服务中受益,包括命名和负载平衡。 Kubernetes使用service抽象支持命名和负载平衡:service具有名称和由标签选择器定义的动态Pod集。群集中的任何容器都可以使用服务名称连接到服务。在幕后,Kubernetes会在与标签选择器匹配的Pod之间自动对服务的连接进行负载平衡,并跟踪Pod在哪里运行,并为它们随着时间故障而重新安排。
\*\*自我检查至关重要,\*\*尽管Borg几乎总是“工作正常”,但是当出现问题时,找到根本原因可能是具有挑战性的。在Borg中,一项重要的设计决策是向所有用户公开调试信息,而不是将其隐藏。
Borg有成千上万的用户,因此“自助”已成为调试的第一步。尽管这使我们更难以弃用功能并更改用户所依赖的内部政策,但这仍然是一个胜利,并且我们没有找到现实的选择。为了处理大量数据,我们提供了多个级别的UI和调试工具,因此用户可以快速识别与其工作相关的异常事件,然后从其应用程序和基础结构本身中深入查看详细的事件和错误日志。
Kubernetes旨在复制许多Borg的自检技术。例如,它附带了诸如cAdvisor \[15\]之类的工具,用于资源监视以及基于Elasticsearch / Kibana \[30\]和Fluentd \[32\]的日志聚合。可以查询master以获取其对象状态的快照。Kubernetes具有统一的机制,所有组件都可以使用该机制来记录可供客户端使用的事件(例如,已调度的Pod,容器失败)。
**master是分布式系统的内核。**
Borgmaster最初是作为一个整体系统设计的,但随着时间的流逝,它逐渐成为位于服务生态系统中以管理用户工作的核心。我们将调度程序和主UI(Sigma)分离为单独的过程,并添加了用于接纳控制,垂直和水平自动缩放,重新打包任务,定期作业提交(cron),工作流管理以及离线归档系统操作的服务查询。总之,这些使我们能够在不牺牲性能或可维护性的情况下扩大工作量和功能集。
kubernetes的架构走得更远,它的核心是一个API server,它仅负责处理请求和处理基础状态对象。集群管理逻辑是构建为小型的、复合的微服务,它们是这个API服务器的客户端,比如在出现故障时维护所需的pod副本数量的复制控制器,以及管理机器生命周期的node controller。
8.3 Conclusion
在过去十年,几乎所有的google集群负载都已经切换到了Borg,并且我们仍在持续的更新它,并且他我们所学到的应用到kubernetes上。
结语:现在看来,kubernetes真是一个吸取了诸多经验与一流设计的集群操作系统啊!
- 文章翻译
- Large-scale cluster management at Google with Borg
- Borg Omega and kubernetes
- scaling kubernetes to 7500 nodes
- bpf 的过去,未来与现在
- Demystifying Istio Circuit Breaking
- 知识图谱
- skill level up graph
- 一、运维常用技能
- 1.0 Vim (编辑器)
- 1.1 Nginx & Tengine(Web服务)
- 基础
- 1.2 zabbix
- 定义
- 登录和配置用户
- 1.3 RabbitMQ(消息队列)
- 原理
- RabbitMQ(安装)
- 1.4虚拟化技术
- KVM
- 1.5 Tomcat(Web中间件)
- 1.6Jenkins
- pipline
- 1.7 Docker
- network
- 1.8 Keepalived(负载均衡高可用)
- 1.9 Memcache(分布式缓存)
- 1.10 Zookeeper(分布式协调系统)
- 1.11 GitLab(版本控制)
- 1.12 Jenkins(运维自动化)
- 1.13 WAF(Web防火墙)
- 1.14 HAproxy负载均衡
- 1.15 NFS(文件传输)
- 1.16 Vim(编辑器)
- 1.17 Cobbler(自动化部署)
- 二、常用数据库
- 2.1 MySQL(关系型数据库)
- mysql主从复制
- 2.2 Mongodb(数据分析)
- 2.3 Redis(非关系数据库)
- 三、自动化运维工具
- 3.1 Cobbler(系统自动化部署)
- 3.2 Ansible(自动化部署)
- 3.3 Puppet(自动化部署)
- 3.4 SaltStack(自动化运维)
- 四、存储
- 4.1 GFS(文件型存储)
- 4.2 Ceph(后端存储)
- 五、运维监控工具
- 5.1 云镜
- 5.2 ELK
- 六、运维云平台
- 6.1 Kubernetes
- 6.2 OpenStack
- 介绍
- 安装
- 七、Devops运维
- 7.1 理念
- 7.2 Devops运维实战
- 八、编程语言
- 8.1 Shell
- 书籍《Wicked Cool Shell Scripts》
- 8.2 Python
- 8.3 C
- 8.4 Java
- leecode算法与数据结构
- 九、杂记
- 高优先级技能
- 知识点
- JD搜集
- 明显的短板
- 1.0 Python
- 1.1 Kubernetes
- 1.18.2 《kubernetes in action》
- 遗漏知识点
- 1.18.3 GCP、azure、aliyun
- Azure文档
- 1.18.5 《program with kubernetes》
- Istio
- HELM
- 《Kubernetes best practice》
- Kubernetes源码学习
- Scheduler源码
- 调度器入口
- 调度器框架
- Node筛选算法
- Node优先级算法
- pod抢占调度
- 入口
- 主要代码结构
- new
- 文章翻译
- Flannel
- 从二进制集群搭建
- 信息收集
- docker优化
- 1.2 shell
- 面试题
- grep awk sed 常见用法
- shell实践
- 1.3 Data structure(数据结构)
- Calico
- Aliyun文档以及重点模块
- git
- 大数据组件
- 前端,后端,web框架
- cgroup,namespace
- 内核
- Linux搜集
- crontab
- centos7常用优化配置
- centos Mariadb
- eBPF
- ebpf的前世今生
- Linux性能问题排查与分析
- 性能分析搜集
- 性能分析常用10条
- 网络性能优化
- 文本处理命令
- sql
- Iptables
- python面试题
- iptables
- iptables详细
- zabbix面试题,proj
- prometheus
- web中间件
- nginx
- Haproxy
- grep sed awk
- Linux常用命令
- 云平台
- 书籍Linux应用技巧
- kafka
- kafka面试题
- ETCD
- Jenkins
- 3天补充的点
- K8s源码
- K8s
- k8s实操
- etcd
- test
- BPF
- PSFTP使用
- StackOverflow问答精选
- 问题
- 我对于学习思考
- 修改ssh超时时间
- 课程目录
- 运维与运维开发
- The Person
- 个人杂谈
- mysql主从复制
- 对于工作的认识与思考