
## RDD 的依赖关系
`RDD`有两种依赖,分别为**宽依赖 (`wide dependency/shuffle dependency`) \**和\**窄依赖 (`narrow dependency`)** :

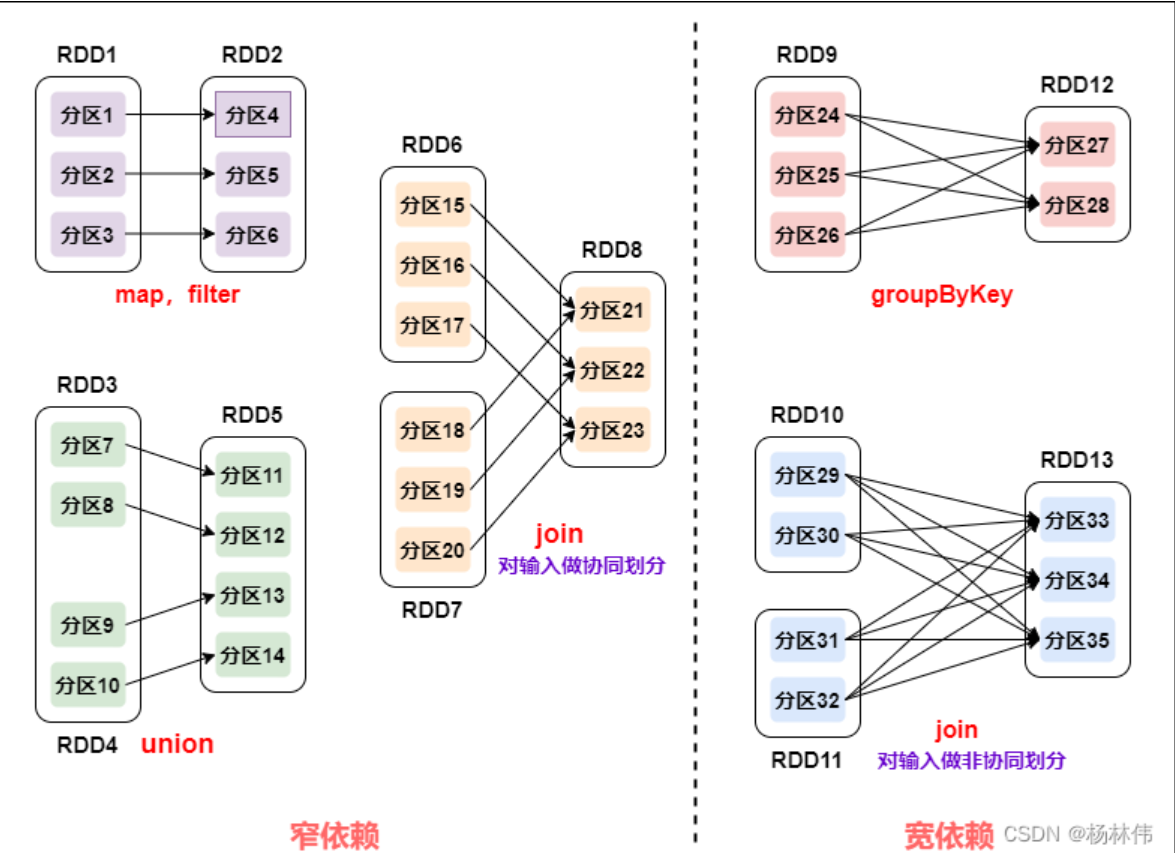
从上图可以看到:
- **窄依赖**:父 RDD 的一个分区只会被子 RDD 的一个分区依赖;
- **宽依赖**:父 RDD 的一个分区会被子 RDD 的多个分区依赖 (涉及到 shuffle)。
**对于窄依赖:**
- 窄依赖的多个分区可以并行计算;
- 窄依赖的一个分区的数据如果丢失只需要重新计算对应的分区的数据就可以了。
**对于宽依赖:**
- 划分 Stage(阶段) 的依据: 对于宽依赖, 必须等到上一阶段计算完成才能计算下一阶段。
#### 2.1.7 DAG 的生成和划分 Stage
##### 2.1.7.1 DAG
**DAG(`Directed Acyclic Graph` 有向无环图)**:指的是数据转换执行的过程,有方向,无闭环 (其实就是 RDD 执行的流程);
原始的 RDD 通过一系列的转换操作就形成了 DAG 有向无环图,任务执行时,可以按照 DAG 的描述,执行真正的计算 (数据被操作的一个过程)。
**DAG 的边界**:
- **开始**:通过 SparkContext 创建的 RDD;
- **结束**:触发 Action,一旦触发 Action 就形成了一个完整的 DAG。
## DAG 划分 Stage
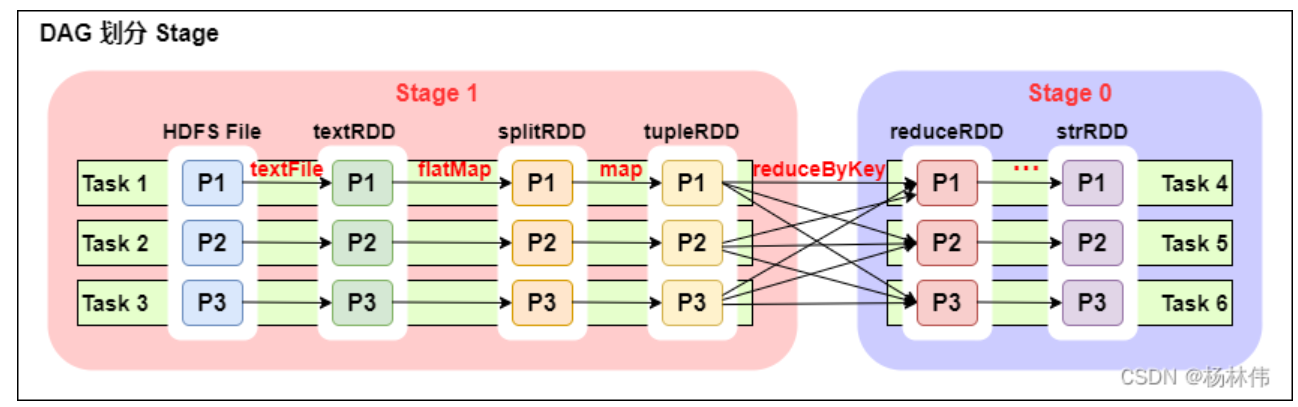
从上图可以看出:
- 一个 Spark 程序可以有多个 DAG(有几个 Action,就有几个 DAG,上图最后只有一个 Action(图中未表现), 那么就是一个 DAG);
- 一个 DAG 可以有多个 Stage(根据宽依赖 / shuffle 进行划分);
- 同一个 Stage 可以有多个 Task 并行执行 (task 数 = 分区数,如上图,Stage1 中有三个分区 P1、P2、P3,对应的也有三个 Task);
- 可以看到这个 DAG 中只 reduceByKey 操作是一个宽依赖,Spark 内核会以此为边界将其前后划分成不同的 Stage;
- 在图中 Stage1 中,从 textFile 到 flatMap 到 map 都是窄依赖,这几步操作可以形成一个流水线操作,通过 flatMap 操作生成的 partition 可以不用等待整个 RDD 计算结束,而是继续进行 map 操作,这样大大提高了计算的效率。
为什么要划分 Stage? -- 并行计算
- 一个复杂的业务逻辑如果有 shuffle,那么就意味着前面阶段产生结果后,才能执行下一个阶段,即下一个阶段的计算要依赖上一个阶段的数据。那么我们按照 shuffle 进行划分 (也就是按照宽依赖就行划分),就可以将一个 DAG 划分成多个 Stage / 阶段,在同一个 Stage 中,会有多个算子操作,可以形成一个 pipeline 流水线,流水线内的多个平行的分区可以并行执行。
如何划分 DAG 的 stage?
- 对于窄依赖,partition 的转换处理在 stage 中完成计算,不划分 (将窄依赖尽量放在在同一个 stage 中,可以实现流水线计算)。
- 对于宽依赖,由于有 shuffle 的存在,只能在父 RDD 处理完成后,才能开始接下来的计算,也就是说需要要划分 stage。
**总结:**
- Spark 会根据 shuffle / 宽依赖使用回溯算法来对 DAG 进行 Stage 划分,从后往前,遇到宽依赖就断开,遇到窄依赖就把当前的 RDD 加入到当前的 stage / 阶段中。
具体的划分算法请参见 AMP 实验室发表的论文:[《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》](http://xueshu.baidu.com/usercenter/paper/show?paperid=b33564e60f0a7e7a1889a9da10963461&site=xueshu_se)
- Introduction
- 快速上手
- Spark Shell
- 独立应用程序
- 开始翻滚吧!
- RDD编程基础
- 基础介绍
- 外部数据集
- RDD 操作
- 转换Transformations
- map与flatMap解析
- 动作Actions
- RDD持久化
- RDD容错机制
- 传递函数到 Spark
- 使用键值对
- RDD依赖关系与DAG
- 共享变量
- Spark Streaming
- 一个快速的例子
- 基本概念
- 关联
- 初始化StreamingContext
- 离散流
- 输入DStreams
- DStream中的转换
- DStream的输出操作
- 缓存或持久化
- Checkpointing
- 部署应用程序
- 监控应用程序
- 性能调优
- 减少批数据的执行时间
- 设置正确的批容量
- 内存调优
- 容错语义
- Spark SQL
- 概述
- SparkSQLvsHiveSQL
- 数据源
- RDDs
- parquet文件
- JSON数据集
- Hive表
- 数据源例子
- join操作
- 聚合操作
- 性能调优
- 其他
- Spark SQL数据类型
- 其它SQL接口
- 编写语言集成(Language-Integrated)的相关查询
- GraphX编程指南
- 开始
- 属性图
- 图操作符
- Pregel API
- 图构造者
- 部署
- 顶点和边RDDs
- 图算法
- 例子
- 更多文档
- 提交应用程序
- 独立运行Spark
- 在yarn上运行Spark
- Spark配置
- RDD 持久化