Apache Kafka® is a distributed streaming platform. What exactly does that mean?
**Apache Kafka®是一个*分布式流平台*。这意味着什么?**
We think of a streaming platform as having three key capabilities:
**我们认为一个流平台有这三个关键功能:**
1. It lets you publish and subscribe to streams of records. In this respect it is similar to a message queue or enterprise messaging system.
2. It lets you store streams of records in a fault-tolerant way.
3. It lets you process streams of records as they occur.
**1. 能够发布订阅记录流。从这个层面来讲,它类似一个消息队列或企业消息系统。
2. 能够以容错方式存储记录流。
3. 能够及时处理记录流。**
What is Kafka good for?
**Kafka 的优点是?**
It gets used for two broad classes of application:
**主要应用于应用的两大方面**
1. Building real-time streaming data pipelines that reliably get data between systems or applications
2. Building real-time streaming applications that transform or react to the streams of data
**1. 在系统与应用之间建立可靠获取数据的实时流式数据管道
2. 建立相应变换或响应数据流的实时流式应用**
To understand how Kafka does these things, let's dive in and explore Kafka's capabilities from the bottom up.
**为了理解Kafka怎样实现这些,让我们开始自下而上的研究Kafka的功能。**
First a few concepts:
**概念先行:**
* Kafka is run as a cluster on one or more servers.
* The Kafka cluster stores streams of records in categories called topics.
* Each record consists of a key, a value, and a timestamp.
* Kafka作为一个集群运行在一个或多个服务器上。
* Kafka按类别存储的数据流称为topics。
* 每条记录分别包含一个键、值、时间戳。
Kafka has four core APIs:
**Kafka的四个核心API:**
* The Producer API allows an application to publish a stream of records to one or more Kafka topics.
* The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
* The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
* The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table.
* Producer API (生产者)允许一个应用发布记录流给一/多个Kafka的topic。
* Consumer API(消费者)允许一个应用订阅一/多个topic并处理(推送给它们的)记录流。
* Streams API(流)使得应用成为流处理器,消费来自一/多个topic的输入流并发布输出流给一/多个topic,有效地转换输入流为输出流。
* Connector API(连接器) 使得建立并运行着的可复用生产/消费者,能够连接起Kafka topic与现有应用/数据系统。例如,一个关系型数据库的连接器能捕获每张表的变化。
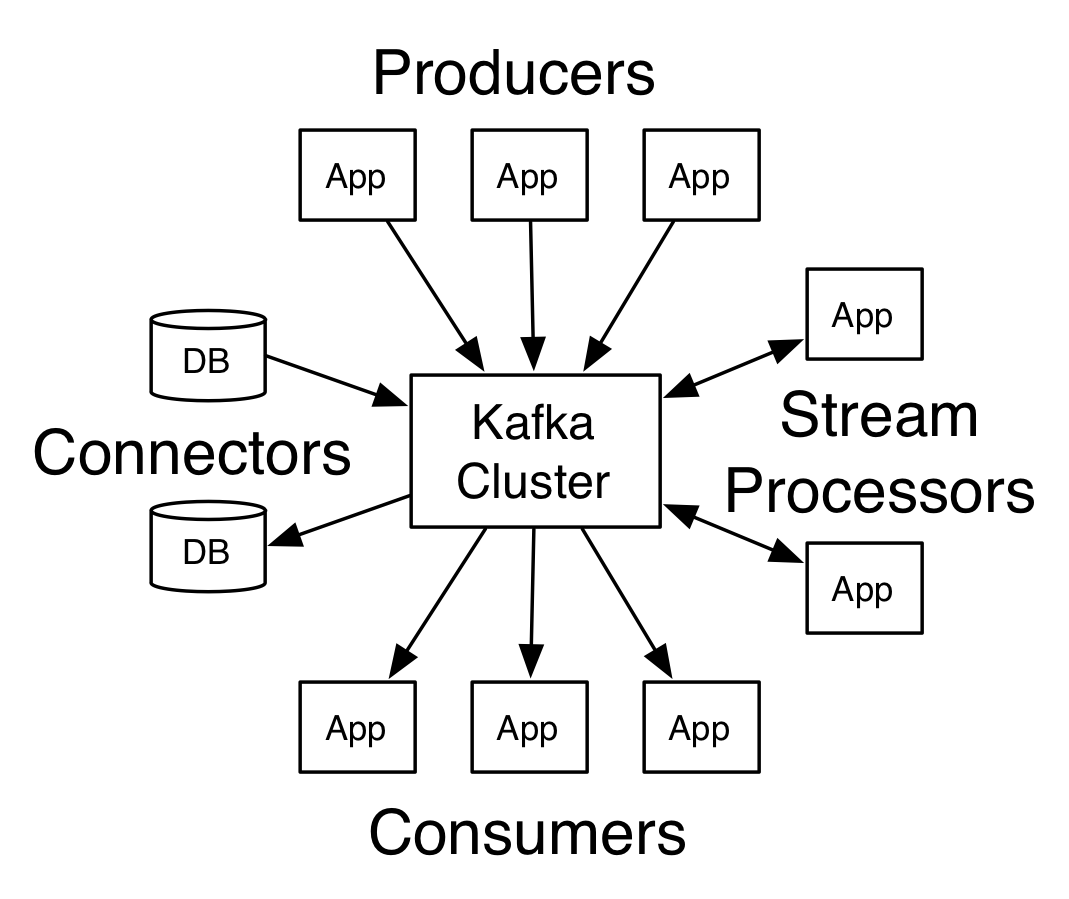
In Kafka the communication between the clients and the servers is done with a simple, high-performance, language agnostic TCP protocol. This protocol is versioned and maintains backwards compatibility with older version. We provide a Java client for Kafka, but clients are available in many languages.
**在Kafka中,客户端与服务器间的连接采用简单、高效,语言无关的TCP协议。该版本化协议支持向后兼容旧版本。我们为Kafka提供了Java版客户端,也可使用其他(更多)语言来实现客户端。**
Topics and Logs
**Topic与Log**
Let's first dive into the core abstraction Kafka provides for a stream of records—the topic.
**首先深入Kafka中用于提供流记录的核心抽象概念——topic。**
A topic is a category or feed name to which records are published. Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it.
**一个topic即一种类别或者说是发布记录的统称。Kafka中的Topic总是多订阅者的,也就是说,一个topic可以有零个,一个,或多个消费者来订阅写入topic的数据。**
For each topic, the Kafka cluster maintains a partitioned log that looks like this:
**对于每个topic而言,Kafka集群维系着如下的一个分区日志:**
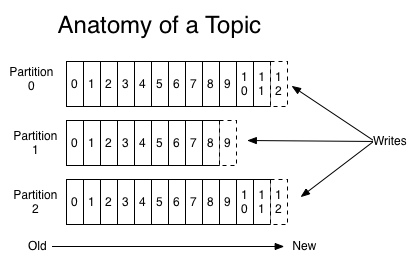
Each partition is an ordered, immutable sequence of records that is continually appended to—a structured commit log. The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
**每组是一个有序的,不可变的,连续追加的记录序列,一种结构型提交日志。分区中的记录分别被赋予一个按次序的id号,称之为偏移,用来唯一区分区内每条记录。**
The Kafka cluster retains all published records—whether or not they have been consumed—using a configurable retention period. For example, if the retention policy is set to two days, then for the two days after a record is published, it is available for consumption, after which it will be discarded to free up space. Kafka's performance is effectively constant with respect to data size so storing data for a long time is not a problem.
**基于可配置的保留周期,Kafka集群能保留着所有发布的记录,即便它们被消费了。例如,如果保留策略设为两天,那么两天内的数据可用于消费,之后将被清空丢弃。在数据量方面Kafka的性能是高效恒定的,因此长期存储数据不是什么问题。**
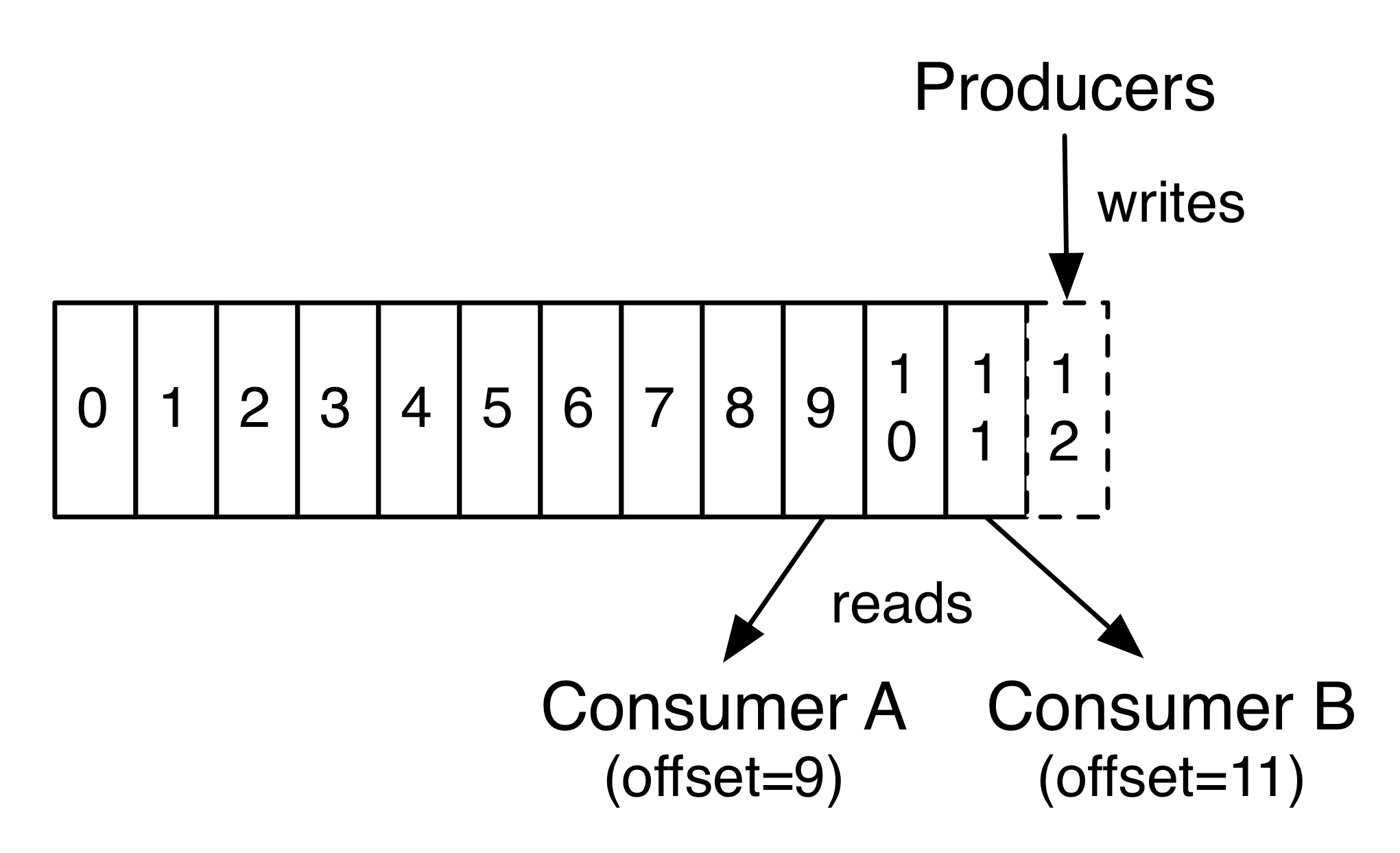
In fact, the only metadata retained on a per-consumer basis is the offset or position of that consumer in the log. This offset is controlled by the consumer: normally a consumer will advance its offset linearly as it reads records, but, in fact, since the position is controlled by the consumer it can consume records in any order it likes. For example a consumer can reset to an older offset to reprocess data from the past or skip ahead to the most recent record and start consuming from "now".
**实际上,元数据仅存每个消费者的主要信息,即偏移或者其在日志中的位置。偏移由消费者来控制:通常一个消费者将线性移动至偏移来读取记录,但是,实际上,由于位置由消费者控制,它可以消费想要的任意次序记录。例如一个消费者可以重置到先前偏移来重新处理之前的数据或者跳到最近的记录开始消费。**
This combination of features means that Kafka consumers are very cheap—they can come and go without much impact on the cluster or on other consumers. For example, you can use our command line tools to "tail" the contents of any topic without changing what is consumed by any existing consumers.
**这系列特征说明Kafka的消费者(消耗)相当小——他们来去自由却不会对集群或其他消费者造成影响。例如,你可以使用我们的命令行工具来“tail”(查看最后几行)任意topic内容而不需要改变现有消费者所需消耗。**
The partitions in the log serve several purposes. First, they allow the log to scale beyond a size that will fit on a single server. Each individual partition must fit on the servers that host it, but a topic may have many partitions so it can handle an arbitrary amount of data. Second they act as the unit of *parallelism*—more on that in a bit.
**日志分区有多种用途。首先,它们能使日志扩展到适应单个服务器的大小。服务器持有的每单个分区(大小)必须适配(规定大小),但是topic可以有多个分区来处理任意数量的数据。其次它们作为并发单位——稍后会进一步解释。**
Distribution
**分布式**
The partitions of the log are distributed over the servers in the Kafka cluster with each server handling data and requests for a share of the partitions. Each partition is replicated across a configurable number of servers for fault tolerance.
**日志分区分布在Kafka集群上的服务器上,每个处理数据的服务器要求有个共享分区。每个分区复制到可配置数量的服务器上以便容错。**
Each partition has one server which acts as the "leader" and zero or more servers which act as "followers". The leader handles all read and write requests for the partition while the followers passively replicate the leader. If the leader fails, one of the followers will automatically become the new leader. Each server acts as a leader for some of its partitions and a follower for others so load is well balanced within the cluster.
**每个分区有一台服务器作为“leader”(主机)和零到多台服务器作为“followers”(从机)。主机处理分区的所有读写请求,与此同时从机被动复制主机。如果主机挂了,其中一个从机将会自动成为新的主机。每台服务器要么作为这些分区的主机要么作为从机,使得集群内加载平衡。**
Producers
**生产者**
Producers publish data to the topics of their choice. The producer is responsible for choosing which record to assign to which partition within the topic. This can be done in a round-robin fashion simply to balance load or it can be done according to some semantic partition function (say based on some key in the record). More on the use of partitioning in a second!
**生产者向自主选择的topic推送数据。生产者的职责在于将指定记录分配到topic中的某个分区。可以通过简单轮询当时实现负载均衡或者可以根据一些语义分区函数实现(基于记录中的key而言)。更多分区用法马上会讲到。**
Consumers
**消费者**
Consumers label themselves with a consumer group name, and each record published to a topic is delivered to one consumer instance within each subscribing consumer group. Consumer instances can be in separate processes or on separate machines.
**消费者将自己分组命名,且每条推给topic的记录会发往各个订阅消费者组中的某一消费者实例。消费者实例可以在不同处理器或不同机器上。**
If all the consumer instances have the same consumer group, then the records will effectively be load balanced over the consumer instances.
**如果所有的消费者实例有相同的消费者组,那么记录会被有效的分摊到消费者实例上。(如下图,加入都分配到了A组,C1与C2各分摊2条)**
If all the consumer instances have different consumer groups, then each record will be broadcast to all the consumer processes.
**如果所有的消费者实例来自不同消费者组,那么每条记录会被广播到所有的消费者处理器上。(如下图,C1与C3来自不同组,说明P0被广播到不同的处理器上了)**
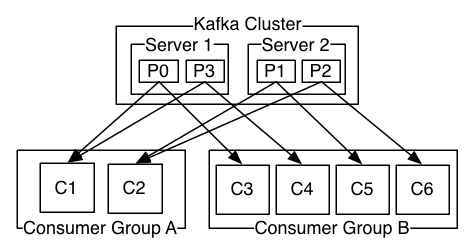
A two server Kafka cluster hosting four partitions (P0-P3) with two consumer groups. Consumer group A has two consumer instances and group B has four.
**一个两台服务器(组成)的Kafka集群拥有四个分区(P0-P3)和两个消费者组。组A有两个消费者实例而组B有四个。**
More commonly, however, we have found that topics have a small number of consumer groups, one for each "logical subscriber". Each group is composed of many consumer instances for scalability and fault tolerance. This is nothing more than publish-subscribe *semantics* where the subscriber is a cluster of consumers instead of a single process.
** ~~通常是这样,然而~~ 与众不同的是,我们会发现topic有少数消费者组对应着“逻辑订阅者”。每组由许多可扩展、容错的消费者实例组成。~~这不过是 订阅者是一个消费者集群而不是单个处理器的 发布订阅模式(语义)。~~ 这也是语义上的发布订阅,只不过订阅者是一个消费者集群,而不是单个处理器。**
The way consumption is implemented in Kafka is by dividing up the partitions in the log over the consumer instances so that each instance is the exclusive consumer of a "fair share" of partitions at any point in time. This process of maintaining membership in the group is handled by the Kafka protocol dynamically. If new instances join the group they will take over some partitions from other members of the group; if an instance dies, its partitions will be distributed to the remaining instances.
**Kafka中将日志划分给分区中的消费者实例来实现消费,因此每个实例在任何时间点都是是“共享”分区的专属消费者。组员维系处理基于Kafka的动态协议协。如果有新实例加入组,那么它们会占用同组成员的一些分区;如果一个实例挂掉了,它的分区会被分配给剩下的实例。**
Kafka only provides a total order over records within a partition, not between different partitions in a topic. Per-partition ordering combined with the ability to partition data by key is sufficient for most applications. However, if you require a total order over records this can be achieved with a topic that has only one partition, though this will mean only one consumer process per consumer group.
**Kafka仅提供单分区内的所有记录有序,而非topic中不同分区之间。各分区结合 按key划分数据的能力 来排序满足大部分应用。然而,如果你想要全部记录有序可以通过一个topic(仅有)一个分区实现,各消费组仅有一个消费者进程。**
Guarantees
**保障**
At a high-level Kafka gives the following guarantees:
**一个高级Kafka能提供以下保障:**
* Messages sent by a producer to a particular topic partition will be appended in the order they are sent. That is, if a record M1 is sent by the same producer as a record M2, and M1 is sent first, then M1 will have a lower offset than M2 and appear earlier in the log.
* A consumer instance sees records in the order they are stored in the log.
* For a topic with replication factor N, we will tolerate up to N-1 server failures without losing any records committed to the log.
* 生产者发送消息给特定topic分区将按其发送顺序追加。也就是说,如果一条记录M1和M2由同一生产者发出,且M1先发,那么M1的偏移小于M2而且在日志中出现的更早些。
* 一个消费者实例按日志所存记录顺序读取。
* 对于N个副本因子的topic,可容许N-1个服务挂掉而不会丢失任何提交到日志的记录。**
More details on these guarantees are given in the design section of the documentation.
**更多保障的细节可在文档的设计章节中看到。**
Kafka as a Messaging System
**Kafka消息系统**
How does Kafka's notion of streams compare to a traditional enterprise messaging system?
**kafka的流概念和传统的企业消息系统有何区别?**
Messaging traditionally has two models: queuing and publish-subscribe. In a queue, a pool of consumers may read from a server and each record goes to one of them; in publish-subscribe the record is broadcast to all consumers. Each of these two models has a strength and a weakness. The strength of queuing is that it allows you to divide up the processing of data over multiple consumer instances, which lets you scale your processing. Unfortunately, queues aren't multi-subscriber—once one process reads the data it's gone. Publish-subscribe allows you broadcast data to multiple processes, but has no way of scaling processing since every message goes to every subscriber.
**传统消息模式有两种:队列和发布订阅。在队列(模式)中,一堆消费者的任一消费者都有机会从服务器读取到记录;在发布订阅(模式)中,记录被广播给所有消费者。两者皆有利弊。队列的好处是允许数据处理划分给多个消费者实例,~~扩展你的处理~~提高处理性能。不足的是,队列不支持多订阅——数据读取一次就没了。发布订阅(模式)允许广播数据给多进程,但是无法扩展处理,因为消息都到了各自的订阅者那。**
The consumer group concept in Kafka generalizes these two concepts. As with a queue the consumer group allows you to divide up processing over a collection of processes (the members of the consumer group). As with publish-subscribe, Kafka allows you to broadcast messages to multiple consumer groups.
**Kafka中的消费者组概念结合了以上两种思想。消费者组与队列一样允许划分进程集合(消费者组成员)。与发布订阅一样,支持广播消息给多个消息组。**
The advantage of Kafka's model is that every topic has both these properties—it can scale processing and is also multi-subscriber—there is no need to choose one or the other.
**Kafka模式的优点在于每个topic有着以下两方面——提高处理的同时又支持多订阅者——无需选择(队列还是发布订阅)。**
Kafka has stronger ordering guarantees than a traditional messaging system, too.
**此外,Kafka比传统消息系统拥有更强的顺序保证。**
A traditional queue retains records in-order on the server, and if multiple consumers consume from the queue then the server hands out records in the order they are stored. However, although the server hands out records in order, the records are delivered asynchronously to consumers, so they may arrive out of order on different consumers. This effectively means the ordering of the records is lost in the presence of *parallel consumption*. Messaging systems often work around this by having a notion of "exclusive consumer" that allows only one process to consume from a queue, but of course this means that there is no parallelism in processing.
**传统队列在服务器端按顺序保留记录,当多消费者从队列消费,服务器会按存储顺序分发记录。然而,即使服务器按顺序分发记录,记录异步传输给消费者,结果他们到达不同消费者可能是无序的。这实际上意味着并发消费情况下记录顺序丢失。消息系统经常为了支持”独占消费者”的概念,即只允许一个进程去消费队列,当然也就意味没有并行处理(能力)了。**
Kafka does it better. By having a notion of parallelism—the partition—within the topics, Kafka is able to provide both ordering guarantees and load balancing over a pool of consumer processes. This is achieved by assigning the partitions in the topic to the consumers in the consumer group so that each partition is consumed by exactly one consumer in the group. By doing this we ensure that the consumer is the only reader of that partition and consumes the data in order. Since there are many partitions this still balances the load over many consumer instances. Note however that there cannot be more consumer instances in a consumer group than partitions.
**Kafka更出众(相比上文)。基于topic内分区并行概念,kafka既能够保证顺序又能负载均衡消费者进程池。这得意于将topic中的分区分配给消费者组中的消费者,以至于消费者组中的一个消费者能准确的消费分区。由此可见消费者是分区唯一的订阅者,而且按顺序消费。这样许多的分区还要分摊到更多的消费者实例上。不过需要注意的是一个消费者组里的消费者实例不能多于分区。**
Kafka as a Storage System
**Kafka存储系统**
Any message queue that allows publishing messages decoupled from consuming them is effectively acting as a storage system for the *in-flight* messages. What is different about Kafka is that it is a very good storage system.
**任何消息队列能高效地解耦发布消息与消费消息就可以作为*动态*消息的存储系统。Kafka是非常棒的存储系统,这点不同于其他。**
Data written to Kafka is written to disk and replicated for fault-tolerance. Kafka allows producers to wait on acknowledgement so that a write isn't considered complete until it is fully replicated and guaranteed to persist even if the server written to fails.
**Kafka的数据写入是写到硬盘的,而且备份以便容错。Kafka允许生产者等待确认,因此直到全部备份完和保证持久化完才认为一次写入完成,哪怕服务器写入失败。**
The disk structures Kafka uses scale well—Kafka will perform the same whether you have 50 KB or 50 TB of persistent data on the server.
**硬盘结构Kafka利用得极好——无论服务器端是50KB或者50TB持久化数据,Kafka性能相同。**
As a result of taking storage seriously and allowing the clients to control their read position, you can think of Kafka as a kind of special purpose distributed filesystem dedicated to high-performance, low-latency commit log storage, replication, and propagation.
**作为重视存储和允许客户端控制读取位置的结果,你可以把Kafka看做一种致力于高性能,低延迟提交日志存储,可备份,可扩展,这些特殊目的的分布式文件系统。**
For details about the Kafka's commit log storage and replication design, please read [this](https://kafka.apache.org/documentation/#design) page.
**更详细关于Kafka提交日志存储和备份设计,请[阅读](https://kafka.apache.org/documentation/#design)这个页面。**
Kafka for Stream Processing
**kafka流处理**
It isn't enough to just read, write, and store streams of data, the purpose is to enable real-time processing of streams.
**仅仅读,写和存储数据流,其目的是能够实时处理流。**
In Kafka a stream processor is anything that takes continual streams of data from input topics, performs some processing on this input, and produces continual streams of data to output topics.
**Kafka中的流处理器从输入topic连续取数据流,并执行一些处理,然后产生连续的数据流给输出的topic。**
For example, a retail application might take in input streams of sales and shipments, and output a stream of reorders and price adjustments computed off this data.
**例如,一个零售应用可能从销售和装货上读取流,计算数据后输出重订价格流。**
It is possible to do simple processing directly using the producer and consumer APIs. However for more complex transformations Kafka provides a fully integrated Streams API. This allows building applications that do non-trivial processing that *compute aggregations off of streams or join streams together*.
**这可能只是直接利用生产者和消费者做了简单处理。然而对于更复杂转换Kafka提供了一个完全集成流API。允许创建有意义处理的应用,*计算聚合流或者连接流*。**
This facility helps solve the hard problems this type of application faces: handling out-of-order data, reprocessing input as code changes, performing stateful computations, etc.
**该工具用于帮助解决以下类型应用面临的困难问题:处理无序数据,代码变更重新处理输入,执行稳定计算,等等。**
The streams API builds on the core *primitives* Kafka provides: it uses the producer and consumer APIs for input, uses Kafka for stateful storage, and uses the same group mechanism for fault tolerance among the stream processor instances.
**流API建立在Kafka提供的核心基础上:依靠生产者与消费者API输入(输出),依靠Kafka稳定存储,并依靠流处理器实例间的同样的分去机制容错。**
Putting the Pieces Together
**化零为整**
This combination of messaging, storage, and stream processing may seem unusual but it is essential to Kafka's role as a streaming platform.
**把消息,存储,和流处理结合起来看起来有点奇怪但是它是Kafka作为流平台角色必不可少的。**
A distributed file system like HDFS allows storing static files for batch processing. Effectively a system like this allows storing and processing historical data from the past.
**诸如HDFS这样允许存储静态文件用于批处理分布式系统,使得存储和处理过往历史数据很高效。**
A traditional enterprise messaging system allows processing future messages that will arrive after you subscribe. Applications built in this way process future data as it arrives.
**传统企业消息系统能够处理订阅之后来临的消息。以这种方式创建的应用也能处理即将到达的数据。**
Kafka combines both of these capabilities, and the combination is critical both for Kafka usage as a platform for streaming applications as well as for streaming data pipelines.
**Kafka结合了上述功能,并且Kafka用在流应用平台也好,作为流数据管道也好,这种结合都是可圈可点的。**
By combining storage and low-latency subscriptions, streaming applications can treat both past and future data the same way. That is a single application can process historical, stored data but rather than ending when it reaches the last record it can keep processing as future data arrives. This is a generalized notion of stream processing that subsumes batch processing as well as message-driven applications.
**通过结合存储和低延迟订阅,流应用能以相同方式处理新旧数据。即一个能处理历史(数据),存储数据,持续处理数据(直到最后一条记录到达而不是结束)的单应用。广义概念即包括批处理和消息驱动应用的流处理。**
Likewise for streaming data pipelines the combination of subscription to real-time events make it possible to use Kafka for very low-latency pipelines; but the ability to store data reliably make it possible to use it for *critical data* where the delivery of data must be guaranteed or for integration with offline systems that load data only periodically or may go down for extended periods of time for maintenance.The stream processing facilities make it possible to transform data as it arrives.
**同样还有结合实时订阅事件的流数据管道,不仅使得使用Kafka作为非常低延迟的管道成为可能。可靠的存储数据能力还使得有保障的传输关键数据,整合离线系统定期加载的数据,减少维护周期成为可能。流处理设施使得当数据到达时进行转换成为可能。**
For more information on the guarantees, APIs, and capabilities Kafka provides see the rest of the documentation.
**更多关于保障,API,和Kafka具备能力参看接下来的文档。**
译者的话
---
粗略翻译,欢迎纠错,共同进步。
更多有意思的内容欢迎访问[rebey.cn](http://rebey.cn)。
其他译文
---
[《kafka中文手册》-快速开始](http://ifeve.com/kafka-getting-started/);
[kafka文档(6)----0.10.1-Introduction-基本介绍 ](http://blog.csdn.net/beitiandijun/article/details/53671269);
[英文原文](http://kafka.apache.org/intro);
