
[TOC]
*****
# 1. Numpy科学计算
numpy 是 python科学计算的核心库。PYTHON里涉及到科学计算的包括Pandas,sklearn等都是基于numpy进行二次开发包装的。numpy功能非常强大,和scipy构建了强大的PYTHON数理计算功能,函数接口丰富复杂。
* 数组的定义和应用
* 数组元素的索引选取
* 数组的计算

## 数组:Arrays
array用来**存储同类型的序列数据**,能够被非负整数进行索引。 维度的数量就是array的秩(rank)。
我们可以通过python的列表来创建array,并且通过方括号进行索引获取元素
```
import numpy as np
a = np.array([1,3,4,6,10])
```

*****
```
#有五个元素
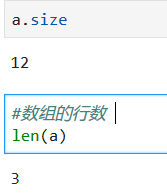
print(a.size)
# 是一维的
print(a.shape)
# 按索引取元素
print(a[2])
```
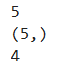
*****
**高维数组的创建**
对于多维数组的理解,看《利用Python进行数据分析》的4.1.4小节
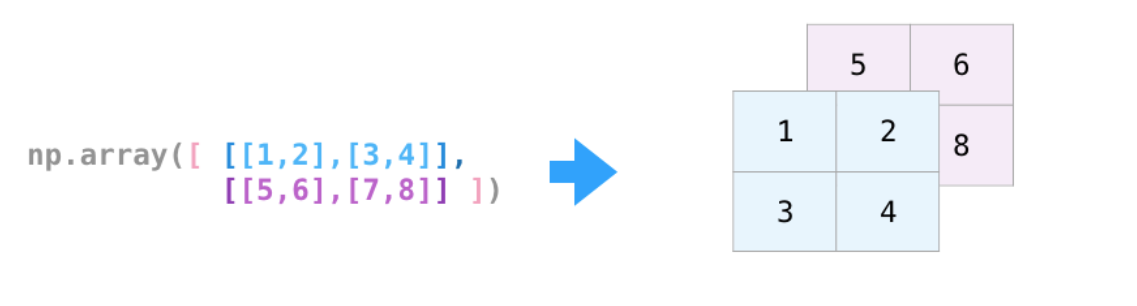
```
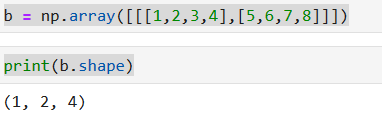
# 二维数组
b = np.array([[1,2,3,4],[5,6,7,8]])
print(b.shape)
```
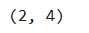
*****
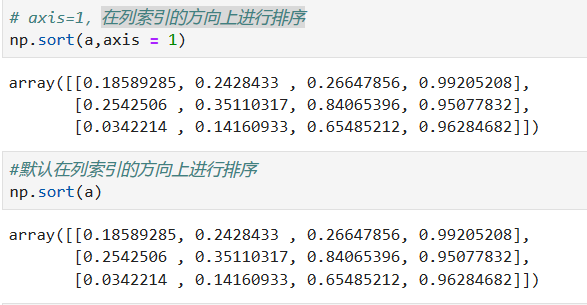
**axis = 0表示在行方向上的索引选取。axis=1表示在列方向上的进行索引选取**
*****
## 创建Array
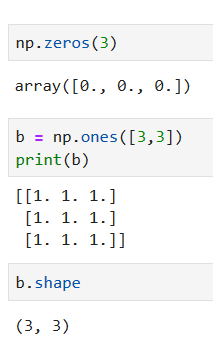
numpy提供了内置的函数来创建一些特殊的数组,我们仅仅需要传递创建的大小即可

*****
```
#按照b的数组结构全填0
np.zeros_like(b)
```
*****
生成如下图的数组

*****
## Array的常用属性和方法
* 统计计算
* 排序
* 按照大小查索引
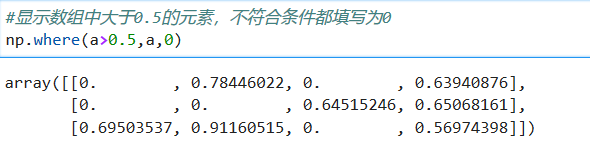
* 条件查找
* shape
*****
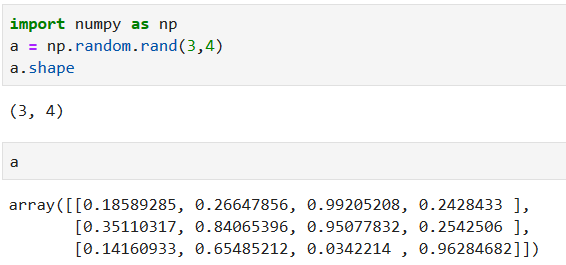
生成3行4列的数组
*****
*****

*****
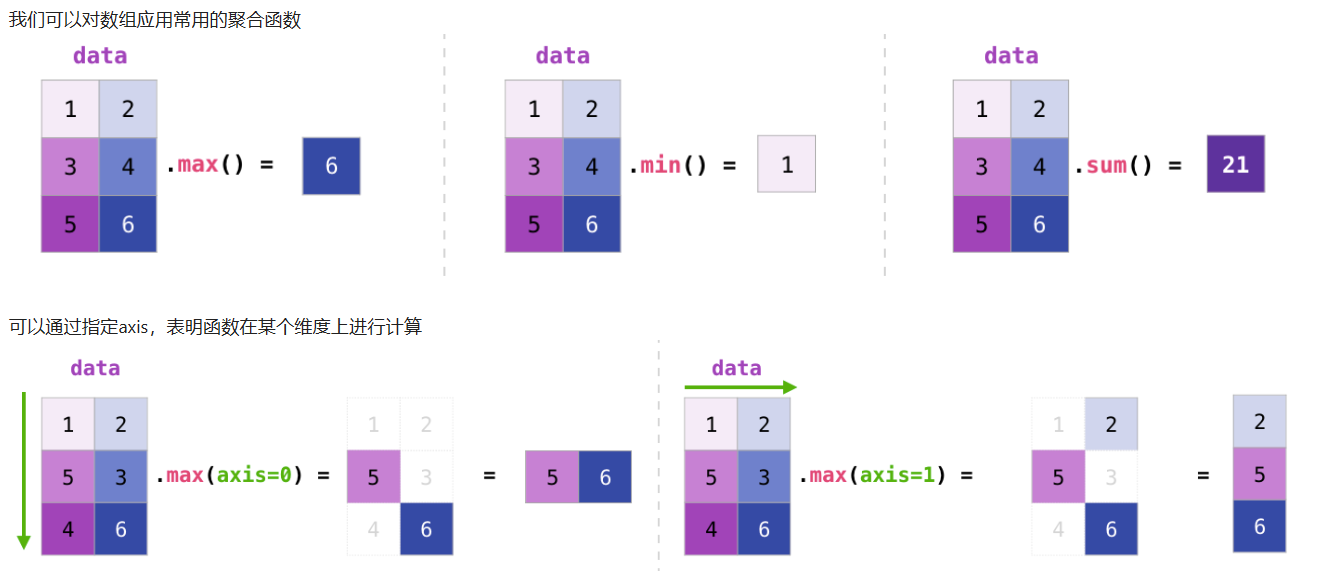
**聚合计算**
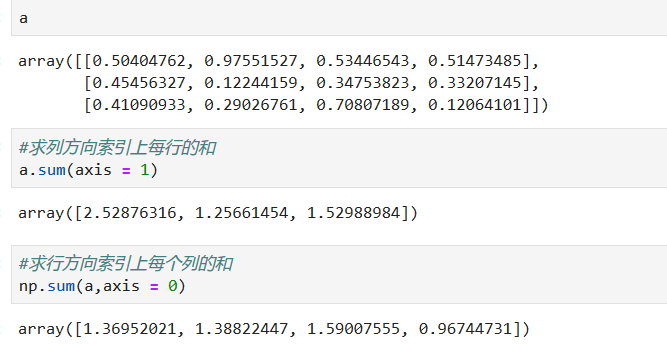
*****
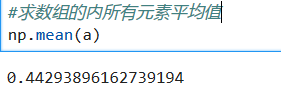
*****
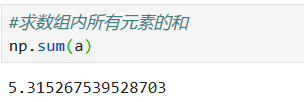
*****
## Shape改变
一个数组的 shape 是由轴及其元素数量决定的,它一般由一个整型元组表示,且元组中的整数表示对应维度的元素数
我们最容易接触到的shape改变就是转置,这通常用于计算dot

还有一种常见的情形是在机器学习中应用,我们需要改变数组的形状从而适应我们的建模需要
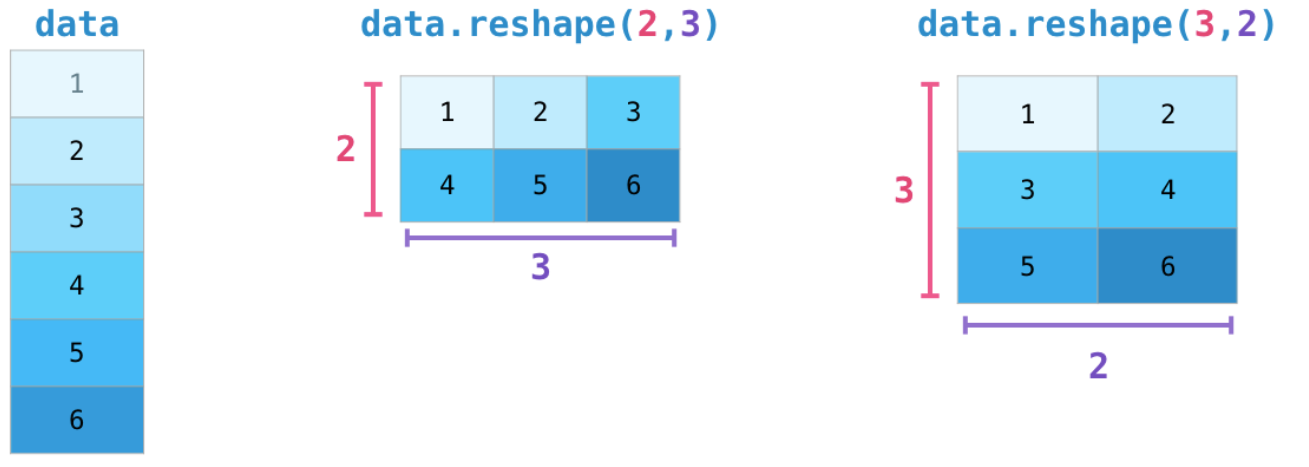
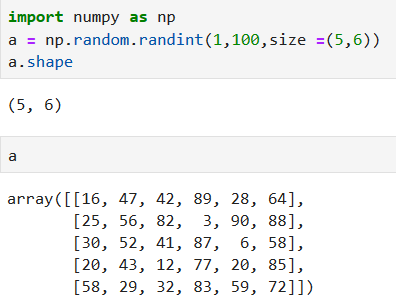
*****
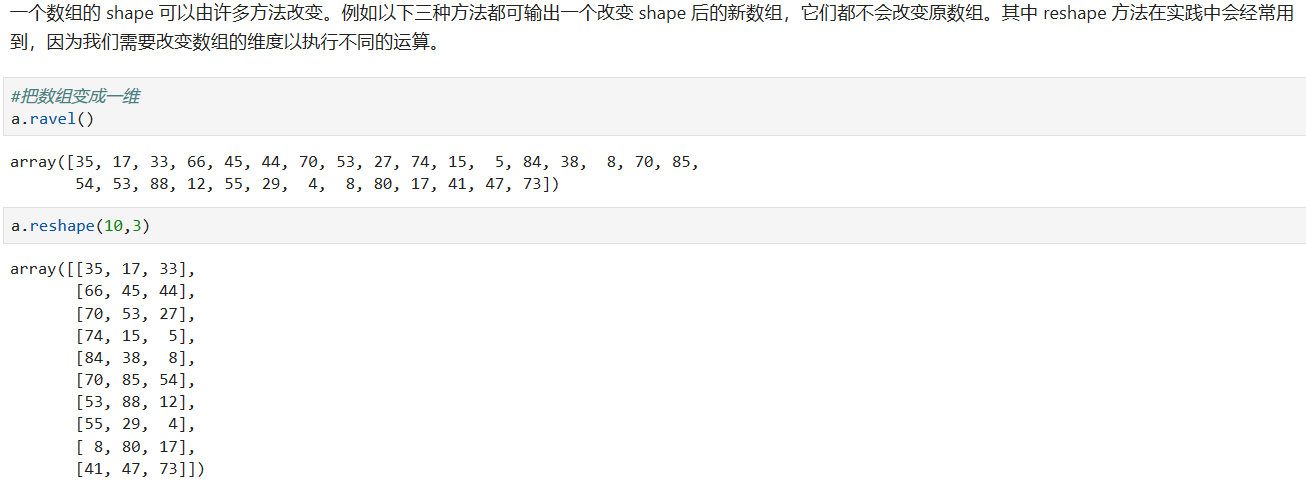
ravel()和reshape()生成新的数组,不改变原有的数组

*****
## 随机数
numpy可以根据一定的规则创建随机数,随机数的使用会在后面概率论,数据挖掘的时候经常用到。
*****
生成3*4的随机数,生成范围[0,1)
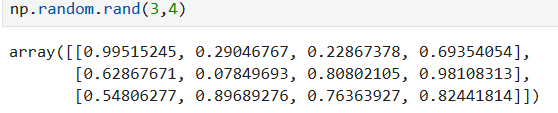
*****
```
#生成10个随机数
np.random.rand(10)
```
*****
生成一个不大于10的随机数
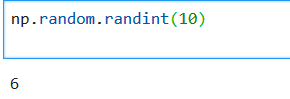
*****
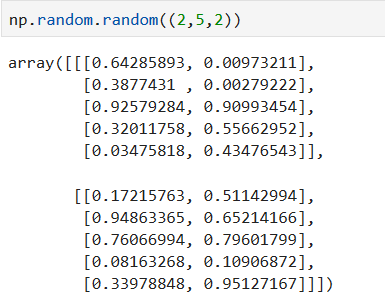
生成两个5*2的数组。生成范围[0.0, 1.0)
*****

*****
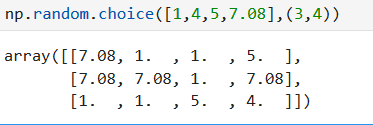
生成3*4的数组,数组中的每个元素从前面的参数列表中随机选取
*****
## 数组的索引
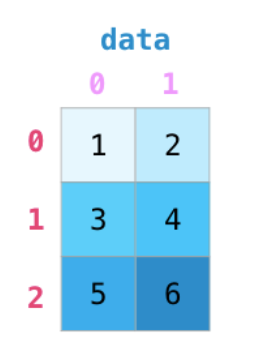
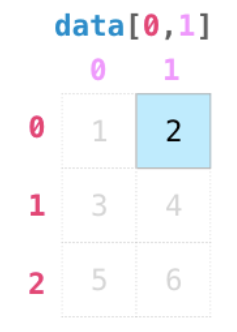
**切片**选取类似于list,但是array可以是多维度的,因此我们需要指定每一个维度上的操作
*****
[]里用切片进行选取,第一个切片参数是在行索引方向上进行选取。[1:3]表示选中位置下标为1的行到位置下标为3的行。
切片按位置选取时,前闭后开,会选到位置下标为2的行止
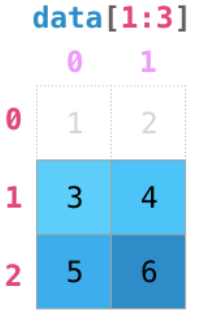
*****
[0:1]选取位置从第0行到1行。逗号后0选取第一列
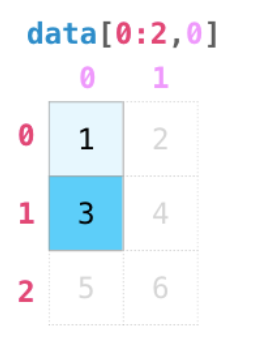
*****
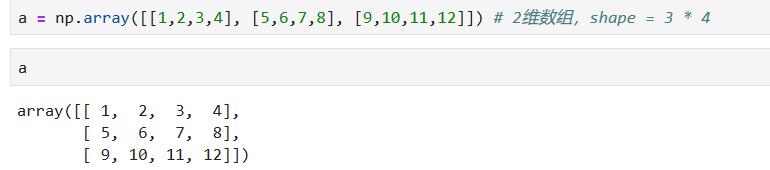
*****

**整数索引**
```
#行位置索引列表1,2。列位置索引列表0,1。所以选中(1,0)和(2,1)
a[[1,2],[0,1]]
```
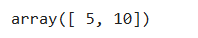
*****
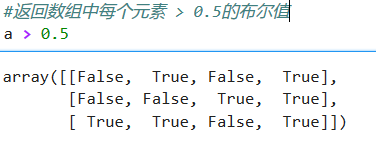
**布尔型索引**
```
# 选出数组中所有大于4的元素
a >4
a[a>4]
```
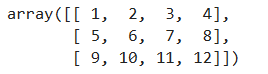
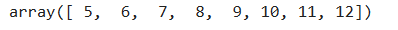
*****
**图解索引**
mask是行索引从位置0到最后一行,每行被选中与否的布尔值列表
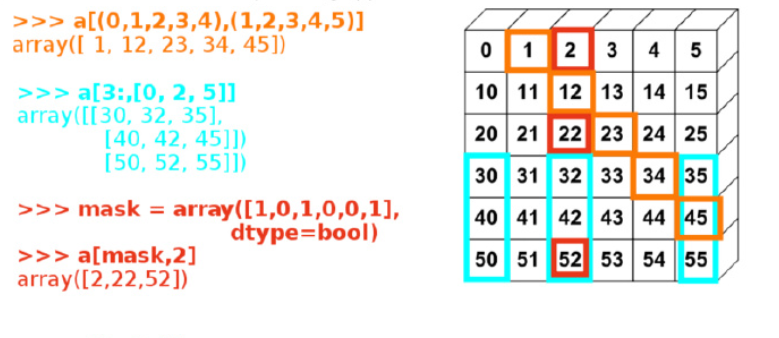
*****
a[2::2,::2]。2::2表示选中位置为2的行和从2开始能不断加2得到索引行。::2表示选中位置为0的列和从0开始能不断加2得到的索引列
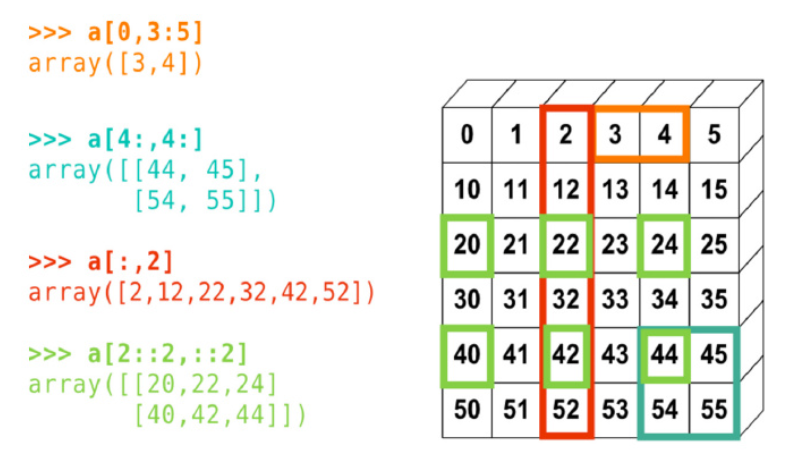
*****
## 数学计算
需要线性代数的知识
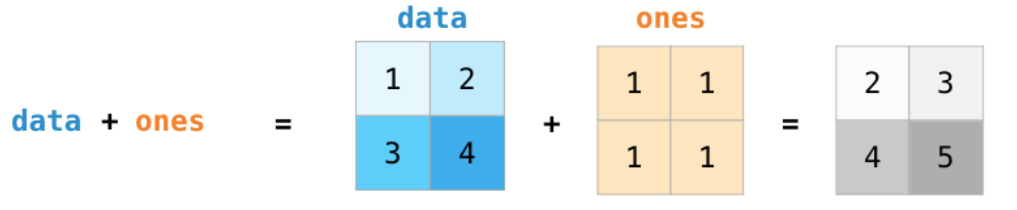
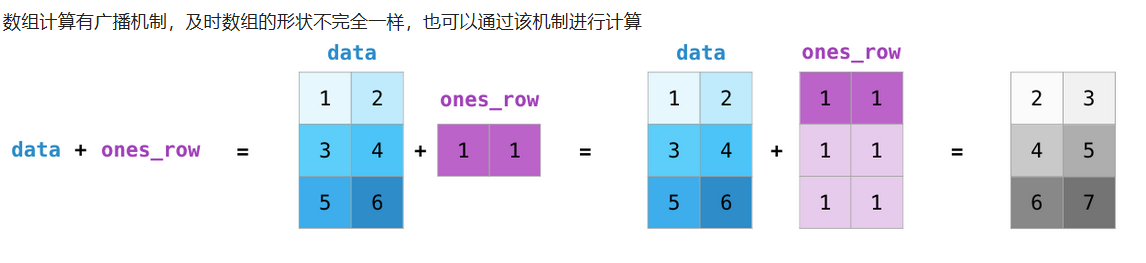
*****
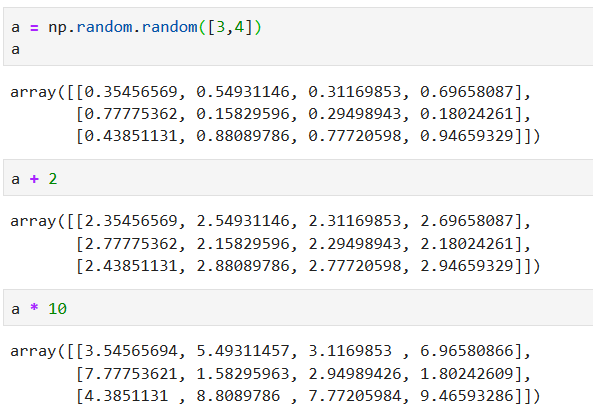
*****
*****

*****

*****
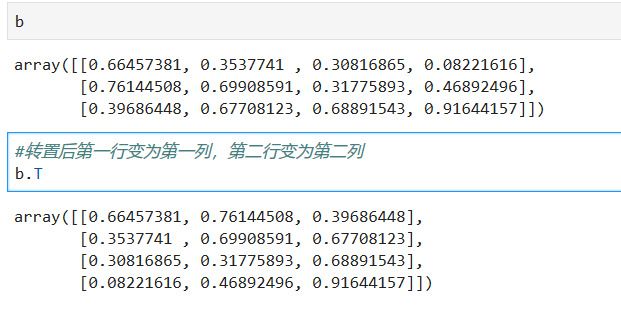
*****
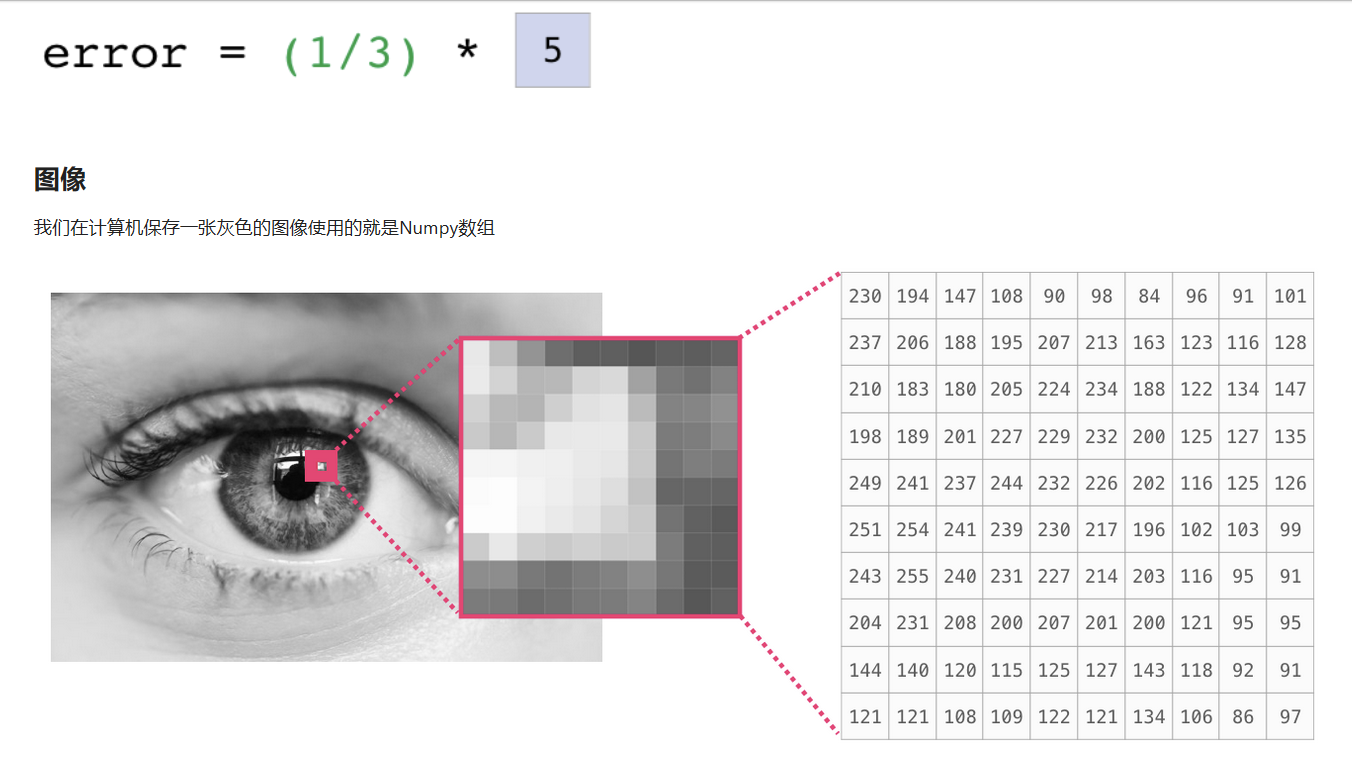
## 实际应用
### 机器学习
在我们学习到后面机器学习的时候,会遇到一个公式。这个公式在统计学习中叫做最小二乘法,在机器学习中的线性回归模型中叫做平方和误差
Prediction是线性回归模型预测试,求与观测值的方差,数字越大,模型预测能力越差
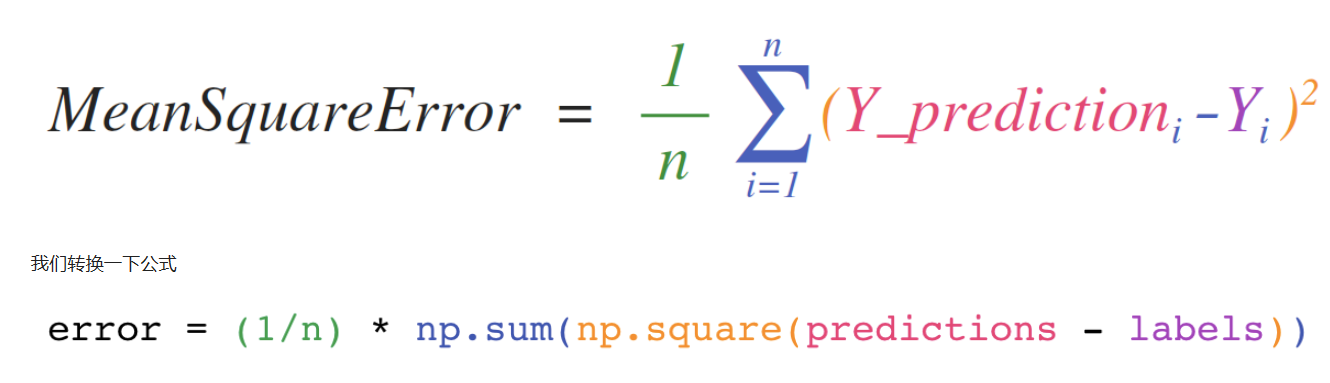


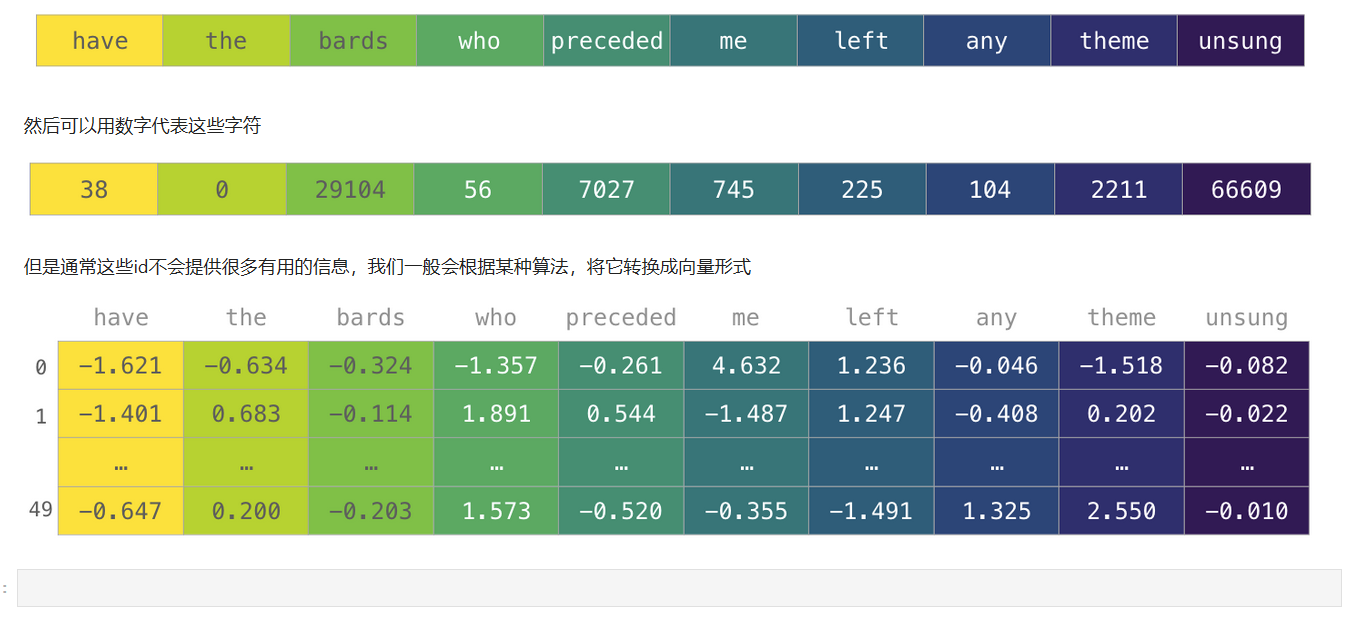
### **文本**
我们可以把一句话切割成单个的字符
- 第五节 Pandas数据管理
- 1.1 文件读取
- 1.2 DataFrame 与 Series
- 1.3 常用操作
- 1.4 Missing value
- 1.5 文本数据
- 1.6 分类数据
- 第六节 pandas数据分析
- 2.1 索引选取
- 2.2. 分组计算
- 2.3. 表联结
- 2.4. 数据透视与重塑(pivot table and reshape)
- 2.5 官方小结图片
- 第七节 NUMPY科学计算
- 第八节 python可视化
- 第九节 统计学
- 01 单变量
- 02 双变量
- 03 数值方法
- 第十节 概率
- 01 概率
- 02 离散概率分布
- 03 连续概率分布
- 第一节 抽样与抽样分布
- 01抽样
- 02 点估计
- 03 抽样分布
- 04 抽样分布的性质
- 第十三节 区间估计
- 01总体均值的区间估计:𝝈已知
- 02总体均值的区间估计:𝝈未知
- 03总体容量的确定
- 04 总体比率