**本节内容:**
[TOC]
## 引言
贝叶斯原理是英国数学家托马斯·贝叶斯提出的。贝叶斯是个很神奇的人,他的经历类似梵高。生前没有得到重视,死后,他写的一篇关于归纳推理的论文被朋友翻了出来,并发表了。这一发表不要紧,结果这篇论文的思想直接影响了接下来两个多世纪的统计学,是科学史上著名的论文之一。<br/>
贝叶斯为了解决一个叫“逆向概率”问题写了一篇文章,**尝试解答在没有太多可靠证据的情况下,怎样做出更符合数学逻辑的推测。**
<strong style="color:red;">什么是“逆向概率”呢? </strong>
所谓“逆向概率”是相对“正向概率”而言。正向概率的问题很容易理解,比如我们已经知道袋子里面有 N 个球,不是黑球就是白球,其中 M 个是黑球,那么把手伸进去摸一个球,就能知道摸出黑球的概率是多少。**但这种情况往往是上帝视角,即了解了事情的全貌再做判断。**
> 一个袋子里有10个球,其中6个黑球,4个白球;那么随机抓一个黑球的概率是0.6!
在现实生活中,我们很难知道事情的全貌。贝叶斯则从实际场景出发,提了一个问题:**如果我们事先不知道袋子里面黑球和白球的比例,而是通过我们摸出来的球的颜色,能判断出袋子里面黑白球的比例么?**
## 0.分类问题综述

其中C叫做类别集合,其中每一个元素是一个类别,而 I 叫做项集合(特征集合),其中每一个元素是一个待分类想,f 叫做分类器。
<strong style="color:red;">分类算法的任务就是构造分类器 f </strong>
<strong>分类算法的内容是要求给定特征,让我们得出类别,这也是所有分类问题的关键。</strong>
## 1.朴素贝叶斯算法介绍
### 1.1贝叶斯定理
条件概率是指在事件B发生的情况下,事件A发生的概率。通常记为 P(A | B)

因此,

可得,

<strong style="color:red;">故,贝叶斯公式为:</strong>

这也是条件概率的计算公式。
此外,由全概率公式,可得条件概率的另一种写法:

其中样本空间由 A 和 A' 构成,由此求得事件B的概率。
<strong style="color:red;">但是,为了减少计算量,全概率公式在实际编程中可以不使用。</strong><br/>
<strong style="color:green;">【敲黑板,划重点】</strong>
贝叶斯公式中,
P(A) 称为“先验概率”(通过经验来判断事情发生的概率),即在B事件发生之前,对A事件概率的一个判断;
P(A | B)称为“后验概率”(就是发生结果之后,推测原因的概率),即在B事件发生之后,对A事件概率的重新评估;
P(B | A)/ P(B)称为“可能性函数”,这是一个调整因子,使得预估概率更接近真实概率。
推出,
<strong>后验概率 = 先验概率 x 调整因子</strong>
这就是贝叶斯推断的含义:我们先预估一个“先验概率”,然后加入实验结果,看这个实验到底是增强还是削弱了“先验概率”,由此得到更接近事实的“后验概率”。
<strong style="color:red;">因此,在分类中,只需要找到可能性最大的那个选项,而不需要知道具体那个类别的概率是多少。</strong>
更重要的是,朴素贝叶斯推断是在贝叶斯推断的基础上,对条件概率分布做了<strong style="color:red;">条件独立性的假设</strong>。
<strong>因此,如果以自变量之间的独立(条件特征独立)性和连续变量的正态性假设为前提,就会导致算法精度在某种程度上受影响。</strong>

### 1.2朴素贝叶斯
朴素贝叶斯,它是一种简单但极为强大的预测建模算法。
之所以称为朴素贝叶斯,是因为它假设每个输入变量是独立的。
这个假设在现实生活中根本不满足,但是这项技术对绝大部分的复杂问题仍然非常有效。<br/>
<strong style="color:red;">朴素贝叶斯模型由两种类型的概率组成:</strong>
* 每个类别的概率P(Cj)
* 每个属性的条件概率P(Ai | Cj)
为了训练朴素贝叶斯模型,我们需要先给出训练数据,以及这些数据对应的分类。
那么上面这两个概率,也就是类别概率和条件概率,他们都可以从给出的训练数据中计算出来,一旦计算出来,概率模型就可以使用贝叶斯原理对新数据进行预测。
<strong style="color:red;">贝叶斯训练流程</strong>

<strong style="color:red;">那么贝叶斯原理、贝叶斯分类和朴素贝叶斯三者之间是何关系???</strong>

* 贝叶斯原理是理论基础(解决概率论中“逆向概率”的问题),人们在该基础上,设计出了贝叶斯分类器;
* 朴素贝叶斯分类是贝叶斯分类器中的一种,也是最简单、最常用的分类器;
* 朴素贝叶斯之所以朴素是因为<i><strong>它假设属性是相互独立的</strong></i>,因此对实际情况有所约束(<strong style="color:green;">如果属性之间存在关联,分类准确率会降低。不过好在对于大部分情况下,朴素贝叶斯的分类效果都不错</strong>)。
## 2.案例分析
### 2.1针对不同类型数据,该如何进行朴素贝叶斯的推断呢?

### 2.2离散数据案例分析
我们以下面的数据为例,这些是我们之前的经验所获得的静静打王者情况的数据。然后给出一个新的数据:
(课程类型:商业数据分析,心情:不好,朋友都在:在)
请问,此时静静会不会打游戏呢?
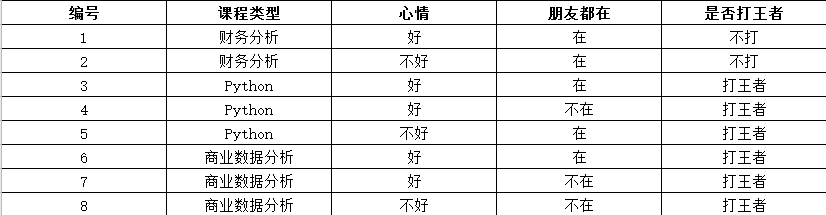
是否打王者就是类别:打王者C1,不打王者C2
属性条件:课程类型A1,心情A2,朋友都在A3
那么我们想要在A1、A2、A3属性下,求解Cj的概率,用条件概率表示就是P(Cj | A1A2A3)。
由贝叶斯公式可得:

共有两种类别,我们只需求得P(C1|A1A2A3)和P(C2|A1A2A3)的概率,然后比较哪个分类的可能性大,就是哪个分类结果,即求P(A1A2A3 | Cj)* P(Cj)的最大值。
<strong style="color:red;">我们假定Ai之间都是相互独立的,那么:</strong>
P(A1A2A3 | Cj)= P(A1 | Cj) * P(A2 | Cj) * P(A3 | Cj)
P(A1 | C1) = 3/6 = 1/2
P(A2 | C1) = 2/6 = 1/3
P(A3 | C1) = 3/6 = 1/2
P(A1 | C2) = 0
P(A2 | C2) = 1/2
P(A3 | C2) = 1
P(C1)= 6/8 = 3/4
P(C2)= 2/8 = 1/4
所以,
P(A1A2A3 | C1) = 1/12
P(A1A2A3 | C2) = 0
=》
P(A1A2A3 | C1)* P(C1)= 1/16
P(A1A2A3 | C2)* P(C2)= 0
所以 P(C1 | A1A2A3)> P(C2 | A1A2A3),所以应该是C1类别,<strong style="color:red;">即静静会打王者(在商业数据分析课,心情不好且朋友都在的时候)的概率大于静静不会打王者的概率。</strong>
### 2.3连续数据案例分析
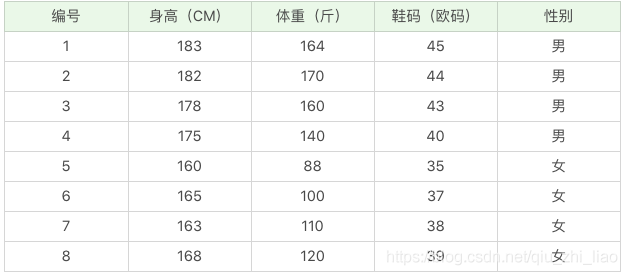
那么如果给你一个新的数据,(身高:180,体重:120,鞋码 41),请问该人是男是女呢? <br/>
公式还是上面的公式,这里的困难在于,由于身高、体重、鞋码都是连续变量,不能采用离散变量的方法计算概率。而且由于样本太少,所以也无法分成区间计算。怎么办呢?
<strong style="color:green;">这时,可以假设男性和女性的身高、体重、鞋码都是正态分布,通过样本计算出均值和方差,也就是得到正态分布的密度函数。</strong>
有了密度函数,就可以把值代入,算出某一点的密度函数的值。<br/>
比如,**男性的身高**是均值 179.5、标准差为 3.697 的正态分布。(我们选择不同条件下的样本,得出的均值,标准差就是条件下的概率分布了。这点稍后计算中体现)<br/>
所以男性的身高为 180 的概率为 0.1069。怎么计算得出的呢? 可以通过 excel 或者 python 工具类<br/>
NORMDIST(x,mean,standard\_dev,cumulative) 函数,一共有 4 个参数:

这里我们使用的是 NORMDIST(180,179.5,3.697,0)=0.1069
同理我们可以计算得出男性体重为 120 的概率为 0.000382324
男性鞋码为 41 号的概率为 0.120304111<br/>
推出,
P(C1 | A1A2A3 ) = 4.9169e-6 > P(C2 | A1A2A3) = 2.7244e-9
故,该组数据分类为男性的概率大于分类为女性的概率
## 3.sklearn实现
scikit-learn中朴素贝叶斯类库的使用也比较简单。相对于决策树,KNN之类的算法,朴素贝叶斯需要关注的参数是比较少的。
在scikit-learn中,一共有3个朴素贝叶斯的分类算法。
* GaussianNB:
* 先验为高斯分布的朴素贝叶斯
* MultionmailNB
* 先验为多项式分布的朴素贝叶斯
* 只有3个参数:
* alpha(拉普拉斯平滑)
* fit_prior(表示是否要考虑先验概率)
* class_prior:可选参数
* MultionmailNB的一个重要的功能是partial_fit方法,这个方法一般用在训练接数据量非常大,一次不能全部载入内存的时候。这是我们可以把训练集分成若干等份,重复调用partial_fit来一步步的学习训练集,非常方便。
* BernoulliNB
* 先验为伯努利分布的朴素贝叶斯
更多scikit-learn中朴素贝叶斯相关可以查看官方文档:[sklearn.naive_bayes.MultionmailNB](https://scikit-learn.org/dev/modules/generated/sklearn.naive_bayes.MultinomialNB.html)
## 4.项目实践 - 基于美团评论的文本情感分析
先贴上源码:[comment-model-analysis](https://github.com/buildupchao/comment-model-analysis)

### 4.1数据清洗
```python
import os
import random
import jieba
from sklearn.model_selection import train_test_split
# from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
"""
读取源数据
"""
def get_txt_data(txt_file):
most_words = []
try:
file = open(txt_file, 'r', encoding='utf-8')
for line in file.readlines():
current_line = line.strip().split("\t")
most_words.append(current_line)
file.close()
except:
try:
file = open(txt_file, 'r', encoding='gb2312')
for line in file.readlines():
current_line = line.strip().split("\t")
most_words.append(current_line)
file.close()
except:
try:
file = open(txt_file, 'r', encoding='gbk')
for line in file.readlines():
current_line = line.strip().split("\t")
most_words.append(current_line)
file.close()
except:
''
return most_words
"""
获取停用词
"""
def load_and_merge_stopwords():
stopwords_set = set()
# load stopwords into set collection so as to distinct
for root, dirs, filename_list in os.walk(r'../data/stop_words'):
for filename in filename_list:
file = open(root + '/' + filename, 'r')
for line in file:
if len(line.strip()):
stopwords_set.add(line.strip())
file.close()
print("加载停用词已完成,停用词共 %d 个" % len(stopwords_set))
return list(stopwords_set)
def context_cut(stopwords, sentence):
cut_words_str = ""
cut_words_list = []
cut_words = list(jieba.cut(sentence))
for word in cut_words:
if word in stopwords:
continue
else:
cut_words_list.append(word)
cut_words_str = ','.join(cut_words_list)
return cut_words_str, cut_words_list
def do_data_etl(using_test_dataset=False):
# 1.提取停用词
stopwords = load_and_merge_stopwords()
# 2.读取数据集,进行分词且过滤掉停用词
words = []
word_list = []
neg_doc = []
if using_test_dataset:
neg_doc = get_txt_data('../data/neg_head.txt')
else:
neg_doc = get_txt_data('../data/neg.txt')
for line_info in neg_doc:
cut_words_str, cut_words_list = context_cut(stopwords, line_info[0])
word_list.append((cut_words_str, -1))
words.append(cut_words_list)
neg_lena = len(word_list)
print("加载消极情绪数据集,共 %d 条" % neg_lena)
pos_doc = []
if using_test_dataset:
pos_doc = get_txt_data('../data/pos_head.txt')
else:
pos_doc = get_txt_data('../data/pos.txt')
for line_info in pos_doc:
cut_words_str, cut_words_list = context_cut(stopwords, line_info[0])
word_list.append((cut_words_str, 1))
words.append(cut_words_list)
print("加载积极情绪数据集,共 %d 条" % (len(word_list) - neg_lena))
random.shuffle(word_list)
print("加载数据集完成,数据共 %d 条" % (len(word_list)))
x, y = zip(*word_list)
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=42, test_size = 0.25)
print("数据分割已完成,训练数据集共 %d 条,测试数据集共 %d 条" % (len(x_train), len(x_test)))
# 3.提取特征向量
# vectorizer = TfidfVectorizer(analyzer='word', ngram_range=(1, 4), max_features=500)
vectorizer = CountVectorizer()
return x_train, x_test, y_train, y_test, vectorizer
```
### 4.2模型训练及使用
```python
from sklearn.naive_bayes import MultinomialNB
from data_etl import etl
from sklearn.pipeline import make_pipeline
from result_display import display
'''
使用CountVectorizer进行特征提取,使用MultinomialNB分类训练
'''
X_train, X_test, y_train, y_test, vectorizer = etl.do_data_etl()
classifier = MultinomialNB()
pipeline = make_pipeline(vectorizer, classifier)
history = pipeline.fit(X_train, y_train)
y_predict = pipeline.predict(X_test)
display.display_report(y_test, y_predict)
```
结果展示:
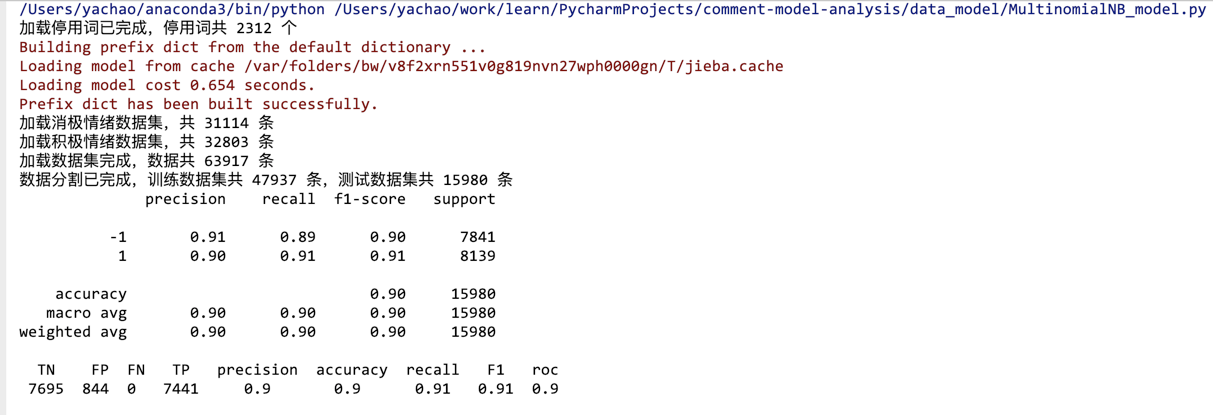
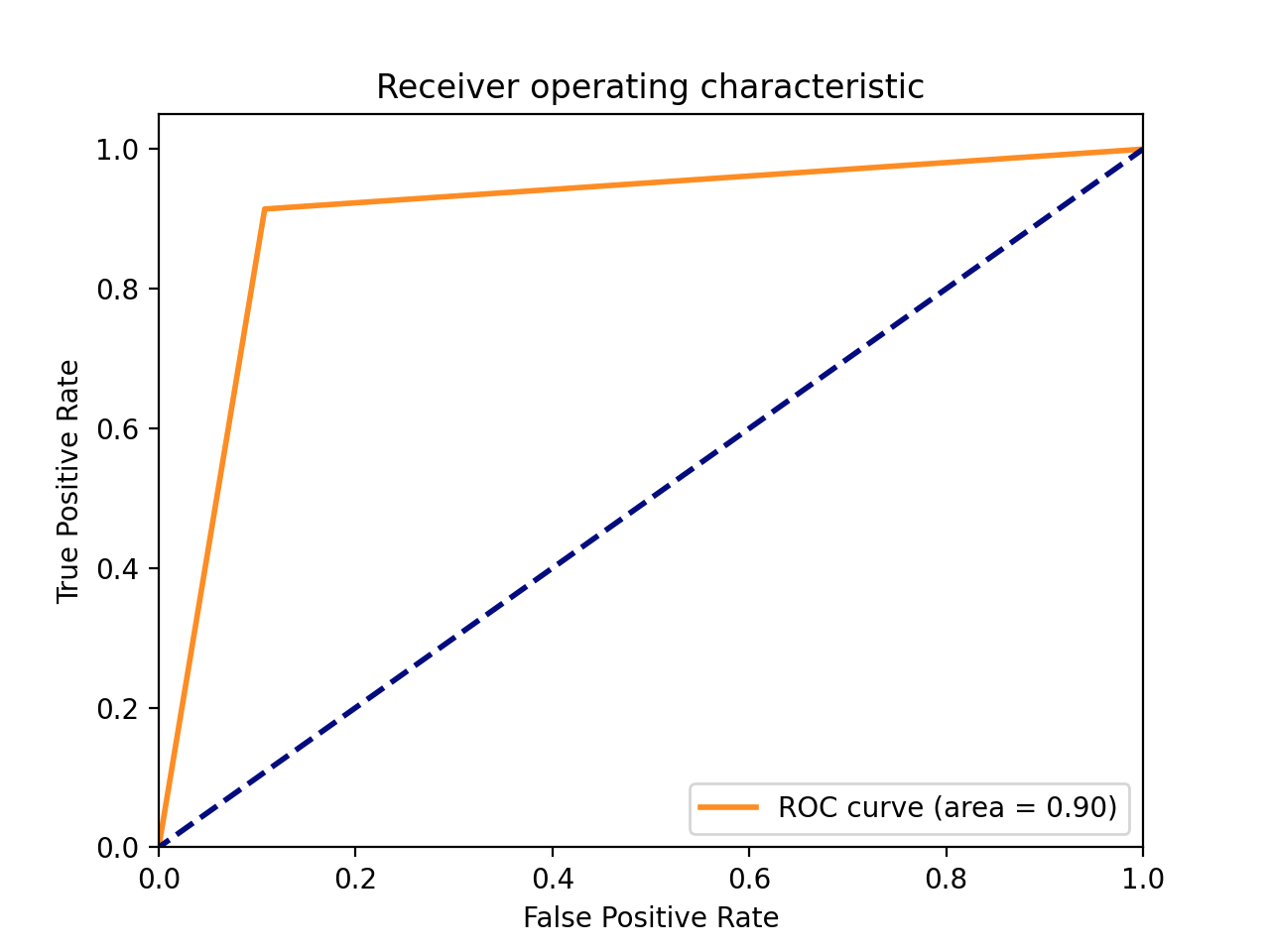
## 5.总结
### 5.1概率依据
* 先验概率:
* 凭借经验得出的概率
* 条件概率:
* 知道原因,推测结果的概率
* 后验概率:
* 知道结果推测原因发生的概率

### 5.2贝叶斯适用场景及各阶段分布
<strong style="color:green;">朴素贝叶斯分类常用于文本分类,尤其是对于英文等语言来说,分类效果很好。</strong>它常用于垃圾文本过滤、情感预测、推荐系统等。
* 准备阶段<strong style="color:red;">(打标签、分割数据集)</strong>:
* 确定特征属性,明确预测值是什么。
* 数据清洗(格式转换等)、打标签(数据分类)
* 分割数据(训练集、测试集/验证集)
* 该阶段对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
* 训练阶段<strong style="color:red;">(模型训练与验证)</strong>:
* 生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率。
* 输入:特征属性和训练样本
* 输出:分类器
* 应用阶段<strong style="color:red;">(模型上线应用)</strong>:
* 使用分类器对新数据进行分类
* 输入:分类器和新数据
* 输出:新数据的分类结果
### 5.3贝叶斯算法优缺点???
* 优点:
* 有稳定的分类效率(发源于古典数学理论)
* 对小规模的数据表现很好,能处理多分类任务,适合增量式训练,尤其是数据量超出内存时,我们可以一批批的去<strong style="color:green;">增量训练</strong>
*<strong style="color:green;"> 对缺失数据不太敏感,算法也比较简单,常用于文本分类</strong>
* 缺点:
* 朴素贝叶斯模型在给定输出类别的情况下,假设属性之间相互独立
* 这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
* 在属性相关性较小时,朴素贝叶斯性能最为良好。
* 对于这一点,有<strong style="color:green;">半朴素贝叶斯之类的算法</strong>通过考虑部分相关性适度改进。
* 需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
* 由于我们是通过先验和数据来决定后验的概率,从而决定分类,所以分类决策存在一定的错误率。
* <strong style="color:green;">对输入数据的表现形式很敏感。</strong>
## 6.课后思考题
如果你的男/女朋友,在你的微信里面发现你和别的女/男人的暧昧聊天记录,于是他/她开始思考了3个概率问题,那么以下3个问题分别属于哪种概率呢???(答案选项从“先验概率、后验概率、条件概率”中选择):
(1)你在没有任何征兆的情况下,出轨的概率;
(2)在你的微信里面发现了暧昧聊天记录,认为你出轨的概率;
(3)如果你出轨了,那么你的微信里面有暧昧聊天记录的概率。<br/>
<strong style="color:green;">答案就在5.1部分哦(总结的顺序就是答案的顺序)!</strong>
## 参考资料
* [算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification)](https://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html)
* [朴素贝叶斯分类实例-单词纠正问题](https://zhuanlan.zhihu.com/p/26653332)
* [朴素贝叶斯分类器的应用](http://www.ruanyifeng.com/blog/2013/12/naive_bayes_classifier.html)
* [朴素贝叶斯算法(Naive Bayes)](https://www.jianshu.com/p/5953923f43f0)
* [《Machine Learning in Action》 美.Perter Harrington著](http://www.java1234.com/a/javabook/javabase/2018/0618/11382.html?__cf_chl_jschl_tk__=1a9fd8cd05c65e779bf06b71c939ce301af6ba6f-1612414161-0-AS1KkYGWerV7qo3F4MC63eSztes9afmW8sVm1pUj0AA3CXfq5v_PHxGsg6jMvWKM9W4mfnJSCtYBsDQCjdTCBGKfDYhHQLuGBoCBxtLUvJVspQh1LAh0Vt-3fESV6P7AnGZLz1cm4bmFVXSAUPq75GxsqqySPmykRUQ2OEG9Xl3cleceh0Errob0UWroT0YJOQMNV_d7N7EeAvfH8DqesOBHzr_ju1v-skh5JI-kku4QIhpOqxJdgT3PYbnKYjukuJq3axyb7MaX_KaIB3oHk2nRzr8h7cdtUCqQKo7XTx1KSDfYMd60S-jZnK_l363Au8zU9k9N4dXKtNrOiME1no8ElxNb1pzF7G72Gk5ceuze)
* [sklearn.naive_bayes.MultionmailNB](https://scikit-learn.org/dev/modules/generated/sklearn.naive_bayes.MultinomialNB.html)
* [基于机器学习的文本情感分类](https://blog.csdn.net/qq_24206673/article/details/108004099)
