# DART booster
[XGBoost](https://github.com/dmlc/xgboost) 主要是将大量带有较小的 Learning rate (学习率) 的回归树做了混合。 在这种情况下,在构造前期增加树的意义是非常显著的,而在后期增加树并不那么重要。
Rasmi 等人从深度神经网络社区提出了一种新的方法来增加 boosted trees 的 dropout 技术,并且在某些情况下能得到更好的结果。
这是一种新型树结构 booster `dart` 的使用指南。
## 原始论文
Rashmi Korlakai Vinayak, Ran Gilad-Bachrach. “DART: Dropouts meet Multiple Additive Regression Trees.” [JMLR](http://www.jmlr.org/proceedings/papers/v38/korlakaivinayak15.pdf)
## 特性
* 直接 drop 树来解决 over-fitting(过拟合)。
* Trivial trees 会被阻止(纠正微不足道的错误)。
由于训练过程中的引入的随机性,会有下面的几点区别。
* 训练可能会比 `gbtree` 慢,因为随机地 dropout 会禁止使用 prediction buffer (预测缓存区)。
* 由于随机性,提早停止可能会不稳定。
## 它是如何运行的
* 在第 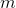 轮训练中,假设  个树被选定 drop 。
* 使用 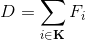 作为 drop 的树的 leaf scores (叶子分数)和 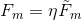 作为新树的 leaf scores (叶子分数)。
* 下面是目标函数 :
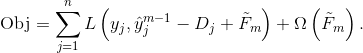
* 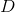 和 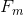 是 overshooting (超调), 所以使用 scale factor (比例因子)
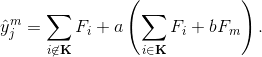
## 参数
### booster
* `dart`
这个 booster 继承了 `gbtree` ,所以 `dart` 还有 `eta`, `gamma`, `max_depth` 等等参数。
其他的参数如下所示。
### sample_type
sampling (采样)算法的类型。
* `uniform`: (默认) drop 的树被统一选择。
* `weighted`: 根据 weights(权重)选择 drop 的树。
### normalize_type
normalization (归一化)算法的类型。
* `tree`: (默认) 新树与 drop 的树的 weight(权重)相同。

* `forest`: 新树具有与 drop 的树(森林)的权重的总和相同的权重。

### rate_drop
dropout 比率.
* 范围: [0.0, 1.0]
### skip_drop
跳过 dropout 的概率。
* 如果一个 dropout 被跳过了,新的树将会像 gbtree 一样被添加。
* 范围: [0.0, 1.0]
## 示例脚本
```
import xgboost as xgb
# read in data
dtrain = xgb.DMatrix('demo/data/agaricus.txt.train')
dtest = xgb.DMatrix('demo/data/agaricus.txt.test')
# specify parameters via map
param = {'booster': 'dart',
'max_depth': 5, 'learning_rate': 0.1,
'objective': 'binary:logistic', 'silent': True,
'sample_type': 'uniform',
'normalize_type': 'tree',
'rate_drop': 0.1,
'skip_drop': 0.5}
num_round = 50
bst = xgb.train(param, dtrain, num_round)
# make prediction
# ntree_limit must not be 0
preds = bst.predict(dtest, ntree_limit=num_round)
```
