# 特性
这篇文档是对 LightGBM 的特点和其中用到的算法的简短介绍
本页不包含详细的算法,如果你对这些算法感兴趣可以查阅引用的论文或者源代码
## 速度和内存使用的优化
许多提升工具对于决策树的学习使用基于 pre-sorted 的算法 [[1, 2]](#references) (例如,在xgboost中默认的算法) ,这是一个简单的解决方案,但是不易于优化。
LightGBM 利用基于 histogram 的算法 [[3, 4, 5]](#references),通过将连续特征(属性)值分段为 discrete bins 来加快训练的速度并减少内存的使用。 如下的是基于 histogram 算法的优点:
* **减少分割增益的计算量**
* Pre-sorted 算法需要 `O(#data)` 次的计算
* Histogram 算法只需要计算 `O(#bins)` 次, 并且 `#bins` 远少于 `#data`
* 这个仍然需要 `O(#data)` 次来构建直方图, 而这仅仅包含总结操作
* **通过直方图的相减来进行进一步的加速**
* 在二叉树中可以通过利用叶节点的父节点和相邻节点的直方图的相减来获得该叶节点的直方图
* 所以仅仅需要为一个叶节点建立直方图 (其 `#data` 小于它的相邻节点)就可以通过直方图的相减来获得相邻节点的直方图,而这花费的代价(`O(#bins)`)很小。
* **减少内存的使用**
* 可以将连续的值替换为 discrete bins。 如果 `#bins` 较小, 可以利用较小的数据类型来存储训练数据, 如 uint8_t。
* 无需为 pre-sorting 特征值存储额外的信息
* **减少并行学习的通信代价**
## 稀疏优化
* 对于稀疏的特征仅仅需要 `O(2 * #non_zero_data)` 来建立直方图
## 准确率的优化
### Leaf-wise (Best-first) 的决策树生长策略
大部分决策树的学习算法通过 level(depth)-wise 策略生长树,如下图一样:
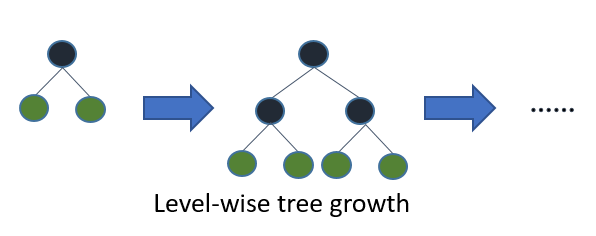
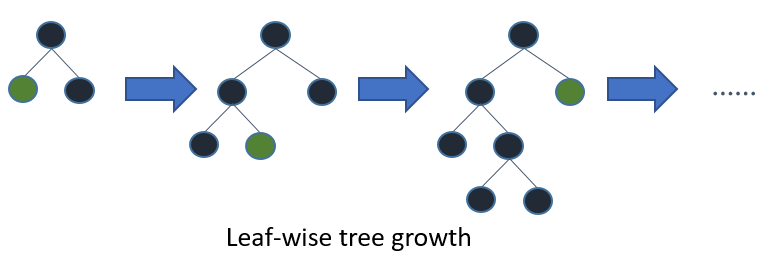
LightGBM 通过 leaf-wise (best-first)[[6]](#references) 策略来生长树。它将选取具有最大 delta loss 的叶节点来生长。 当生长相同的 `#leaf`,leaf-wise 算法可以比 level-wise 算法减少更多的损失。
当 `#data` 较小的时候,leaf-wise 可能会造成过拟合。 所以,LightGBM 可以利用额外的参数 `max_depth` 来限制树的深度并避免过拟合(树的生长仍然通过 leaf-wise 策略)。
### 类别特征值的最优分割
我们通常将类别特征转化为 one-hot coding。 然而,对于学习树来说这不是个好的解决方案。 原因是,对于一个基数较大的类别特征,学习树会生长的非常不平衡,并且需要非常深的深度才能来达到较好的准确率。
事实上,最好的解决方案是将类别特征划分为两个子集,总共有 `2^(k-1) - 1` 种可能的划分 但是对于回归树 [[7]](#references) 有个有效的解决方案。为了寻找最优的划分需要大约 `k * log(k)` .
基本的思想是根据训练目标的相关性对类别进行重排序。 更具体的说,根据累加值(`sum_gradient / sum_hessian`)重新对(类别特征的)直方图进行排序,然后在排好序的直方图中寻找最好的分割点。
## 网络通信的优化
LightGBM 中的并行学习,仅仅需要使用一些聚合通信算法,例如 “All reduce”, “All gather” 和 “Reduce scatter”. LightGBM 实现了 state-of-art 算法 [[8]](#references) . 这些聚合通信算法可以提供比点对点通信更好的性能。
## 并行学习的优化
LightGBM 提供以下并行学习优化算法:
### 特征并行
#### 传统算法
传统的特征并行算法旨在于在并行化决策树中的“ `Find Best Split`.主要流程如下:
1. 垂直划分数据(不同的机器有不同的特征集)
2. 在本地特征集寻找最佳划分点 {特征, 阈值}
3. 本地进行各个划分的通信整合并得到最佳划分
4. 以最佳划分方法对数据进行划分,并将数据划分结果传递给其他线程
5. 其他线程对接受到的数据进一步划分
传统的特征并行方法主要不足:
* 存在计算上的局限,传统特征并行无法加速 “split”(时间复杂度为 “O(#data)”)。 因此,当数据量很大的时候,难以加速。
* 需要对划分的结果进行通信整合,其额外的时间复杂度约为 “O(#data/8)”(一个数据一个字节)
#### LightGBM 中的特征并行
既然在数据量很大时,传统数据并行方法无法有效地加速,我们做了一些改变:不再垂直划分数据,即每个线程都持有全部数据。 因此,LighetGBM中没有数据划分结果之间通信的开销,各个线程都知道如何划分数据。 而且,“#data” 不会变得更大,所以,在使每天机器都持有全部数据是合理的。
LightGBM 中特征并行的流程如下:
1. 每个线程都在本地数据集上寻找最佳划分点{特征, 阈值}
2. 本地进行各个划分的通信整合并得到最佳划分
3. 执行最佳划分
然而,该特征并行算法在数据量很大时仍然存在计算上的局限。因此,建议在数据量很大时使用数据并行。
### 数据并行
#### 传统算法
数据并行旨在于并行化整个决策学习过程。数据并行的主要流程如下:
1. 水平划分数据
2. 线程以本地数据构建本地直方图
3. 将本地直方图整合成全局整合图
4. 在全局直方图中寻找最佳划分,然后执行此划分
传统数据划分的不足:
* 高通讯开销。 如果使用点对点的通讯算法,一个机器的通讯开销大约为 “O(#machine * #feature * #bin)” 。 如果使用集成的通讯算法(例如, “All Reduce”等),通讯开销大约为 “O(2 * #feature * #bin)”[8] 。
#### LightGBM中的数据并行
LightGBM 中采用以下方法较少数据并行中的通讯开销:
1. 不同于“整合所有本地直方图以形成全局直方图”的方式,LightGBM 使用分散规约(Reduce scatter)的方式对不同线程的不同特征(不重叠的)进行整合。 然后线程从本地整合直方图中寻找最佳划分并同步到全局的最佳划分中。
2. 如上所述。LightGBM 通过直方图做差法加速训练。 基于此,我们可以进行单叶子的直方图通讯,并且在相邻直方图上使用做差法。
通过上述方法,LightGBM 将数据并行中的通讯开销减少到 “O(0.5 * #feature * #bin)”。
### 投票并行
投票并行未来将致力于将“数据并行”中的通讯开销减少至常数级别。 其将会通过两阶段的投票过程较少特征直方图的通讯开销 [[9]](#references) .
## GPU 支持
感谢 “@huanzhang12 <[https://github.com/huanzhang12](https://github.com/huanzhang12)>” 对此项特性的贡献。相关细节请阅读 [[10]](#references) 。
* [GPU 安装](./Installatn-ioGuide.rst#build-gpu-version)
* [GPU 训练](./GPU-Tutorial.rst)
## 应用和度量
支持以下应用:
* 回归,目标函数为 L2 loss
* 二分类, 目标函数为 logloss(对数损失)
* 多分类
* lambdarank, 目标函数为基于 NDCG 的 lambdarank
支持的度量
* L1 loss
* L2 loss
* Log loss
* Classification error rate
* AUC
* NDCG
* Multi class log loss
* Multi class error rate
获取更多详情,请至 [Parameters](./Parameters.rst#metric-parameters)。
## 其他特性
* Limit `max_depth` of tree while grows tree leaf-wise
* [DART](https://arxiv.org/abs/1505.01866)
* L1/L2 regularization
* Bagging
* Column(feature) sub-sample
* Continued train with input GBDT model
* Continued train with the input score file
* Weighted training
* Validation metric output during training
* Multi validation data
* Multi metrics
* Early stopping (both training and prediction)
* Prediction for leaf index
获取更多详情,请参阅 [参数](./Parameters.rst)。
## References
[1] Mehta, Manish, Rakesh Agrawal, and Jorma Rissanen. “SLIQ: A fast scalable classifier for data mining.” International Conference on Extending Database Technology. Springer Berlin Heidelberg, 1996.
[2] Shafer, John, Rakesh Agrawal, and Manish Mehta. “SPRINT: A scalable parallel classifier for data mining.” Proc. 1996 Int. Conf. Very Large Data Bases. 1996.
[3] Ranka, Sanjay, and V. Singh. “CLOUDS: A decision tree classifier for large datasets.” Proceedings of the 4th Knowledge Discovery and Data Mining Conference. 1998.
[4] Machado, F. P. “Communication and memory efficient parallel decision tree construction.” (2003).
[5] Li, Ping, Qiang Wu, and Christopher J. Burges. “Mcrank: Learning to rank using multiple classification and gradient boosting.” Advances in neural information processing systems. 2007.
[6] Shi, Haijian. “Best-first decision tree learning.” Diss. The University of Waikato, 2007.
[7] Walter D. Fisher. “[On Grouping for Maximum Homogeneity](http://amstat.tandfonline.com/doi/abs/10.1080/01621459.1958.10501479).” Journal of the American Statistical Association. Vol. 53, No. 284 (Dec., 1958), pp. 789-798.
[8] Thakur, Rajeev, Rolf Rabenseifner, and William Gropp. “[Optimization of collective communication operations in MPICH](http://wwwi10.lrr.in.tum.de/~gerndt/home/Teaching/HPCSeminar/mpich_multi_coll.pdf).” International Journal of High Performance Computing Applications 19.1 (2005): 49-66.
[9] Qi Meng, Guolin Ke, Taifeng Wang, Wei Chen, Qiwei Ye, Zhi-Ming Ma, Tieyan Liu. “[A Communication-Efficient Parallel Algorithm for Decision Tree](http://papers.nips.cc/paper/6381-a-communication-efficient-parallel-algorithm-for-decision-tree).” Advances in Neural Information Processing Systems 29 (NIPS 2016).
[10] Huan Zhang, Si Si and Cho-Jui Hsieh. “[GPU Acceleration for Large-scale Tree Boosting](https://arxiv.org/abs/1706.08359).” arXiv:1706.08359, 2017.
